教程:静态评估
本指南展示如何为您的TensorZero函数定义并运行静态评估。
现状
假设我们有一个TensorZero函数用于根据给定主题创作俳句,并希望比较GPT-4o和GPT-4o Mini在此任务上的表现差异。
最初,我们对此函数的配置可能如下所示:
[functions.write_haiku]type = "chat"user_schema = "functions/write_haiku/user_schema.json"
[functions.write_haiku.variants.gpt_4o_mini]type = "chat_completion"model = "openai::gpt-4o-mini"user_template = "functions/write_haiku/user_template.minijinja"
[functions.write_haiku.variants.gpt_4o]type = "chat_completion"model = "openai::gpt-4o"user_template = "functions/write_haiku/user_template.minijinja"User Schema & Template
{ "$schema": "http://json-schema.org/draft-07/schema#", "type": "object", "properties": { "topic": { "type": "string" } }, "required": ["topic"], "additionalProperties": false}Write a haiku about: {{ topic }}我们如何以系统化的方式评估两种变体的行为表现?
一种选择是构建一个“测试用例”数据集,我们可以据此对它们进行评估。
数据集
要使用TensorZero评估功能,首先需要构建一个数据集。
数据集是数据点的集合。 每个数据点包含一个输入项,以及可选的输出项。 在评估场景中,数据集中的输出应作为参考输出,即您期望看到的理想输出结果。 您并非必须提供参考输出:部分评估器(例如LLM评判器)可以在没有参考输出的情况下对生成内容进行评分(否则该数据点将被跳过)。
让我们创建一个数据集:
- 生成多首俳句。(在GitHub上,我们提供了一个脚本
main.py,可通过write_haiku生成100首俳句。) - 打开用户界面,导航至“数据集”选项,然后选择“构建数据集”(
http://localhost:4000/datasets/builder)。 - 创建一个名为
haiku_dataset的新数据集。 选择您的write_haiku函数,"None"作为指标,"Inference"作为数据集输出。
评估
评估测试TensorZero函数变体的行为表现。
让我们在配置文件中定义一个评估项:
[evaluations.haiku_eval]type = "static"function_name = "write_haiku"评估器
每次评估包含一个或多个评估器:即您希望测试的规则或行为。
目前,TensorZero支持两种评估器类型:exact_match和llm_judge。
exact_match
exact_match评估器会将生成的输出与数据点的参考输出进行比对。如果两者完全一致,则返回true;否则返回false。
[evaluations.haiku_eval.evaluators.exact_match]type = "exact_match"llm_judge
LLM Judges 是一种特殊用途的 TensorZero 功能,可用于评估 TensorZero 功能。
例如,我们的俳句通常应遵循特定格式,但很难定义启发式规则来判断它们是否正确。 何不询问大语言模型呢?
让我们开始吧:
[evaluations.haiku_eval.evaluators.valid_haiku]type = "llm_judge"output_type = "boolean" # LLM judge should generate a boolean (or float)optimize = "max" # higher is bettercutoff = 0.95 # if the variant scores <95% = bad
[evaluations.haiku_eval.evaluators.valid_haiku.variants.gpt_4o_mini_judge]type = "chat_completion"model = "openai::gpt-4o-mini"system_instructions = "evaluations/haiku_eval/valid_haiku/system_instructions.txt"json_mode = "strict"System Instructions
Evaluate if the text follows the haiku structure of exactly three lines with a 5-7-5 syllable pattern, totaling 17 syllables. Verify only this specific syllable structure of a haiku without making content assumptions.这里,我们定义了一个类型为llm_judge的评估器valid_haiku,其中包含一个使用GPT-4o Mini的变体。
与常规的TensorZero函数类似,我们可以为LLM评判者定义多个变体。
但不同于常规函数,在评估期间同一时间只能有一个变体处于激活状态;您可以通过active属性来指定。
Example: Multiple Variants for an LLM Judge
[evaluations.haiku_eval.evaluators.valid_haiku]type = "llm_judge"output_type = "boolean"optimize = "max"cutoff = 0.95
[evaluations.haiku_eval.evaluators.valid_haiku.variants.gpt_4o_mini_judge]type = "chat_completion"model = "openai::gpt-4o-mini"system_instructions = "evaluations/haiku_eval/valid_haiku/system_instructions.txt"json_mode = "strict"active = true
[evaluations.haiku_eval.evaluators.valid_haiku.variants.gpt_4o_judge]type = "chat_completion"model = "openai::gpt-4o"system_instructions = "evaluations/haiku_eval/valid_haiku/system_instructions.txt"json_mode = "strict"我们上面展示的LLM评判器生成的是布尔值,但它们也可以生成浮点数。
让我们定义另一个评估器,用于统计俳句中隐喻的数量。
[evaluations.haiku_eval.evaluators.metaphor_count]type = "llm_judge"output_type = "float" # LLM judge should generate a boolean (or float)optimize = "max"cutoff = 1 # <1 metaphor per haiku = bad我们也可以为评估器使用不同的变体类型。 由于隐喻计数评估器稍微复杂一些,让我们为其使用思维链变体。
[evaluations.haiku_eval.evaluators.metaphor_count.variants.gpt_4o_mini_judge]type = "experimental_chain_of_thought"model = "openai::gpt-4o-mini"system_instructions = "evaluations/haiku_eval/metaphor_count/system_instructions.txt"json_mode = "strict"System Instructions
How many metaphors does the generated haiku have?目前我们定义的LLM评判标准仅关注数据点的输入和生成输出。 但我们也可以向评判者提供数据点的参考输出:
[evaluations.haiku_eval.evaluators.compare_haikus]type = "llm_judge"include = { reference_output = true } # include the reference output in the LLM judge's contextoutput_type = "boolean"optimize = "max"
[evaluations.haiku_eval.evaluators.compare_haikus.variants.gpt_4o_mini_judge]type = "chat_completion"model = "openai::gpt-4o-mini"system_instructions = "evaluations/haiku_eval/compare_haikus/system_instructions.txt"json_mode = "strict"System Instructions
Does the generated haiku include the same figures of speech as the reference haiku?运行评估
让我们开始运行评估吧!
您可以使用TensorZero评估CLI工具或TensorZero界面运行评估。
命令行界面
要在命令行界面运行评估,您可以使用tensorzero/evaluations容器:
docker compose run --rm evaluations \ --evaluation-name haiku_eval \ --dataset-name haiku_dataset \ --variant-name gpt_4o \ --concurrency 5Docker Compose
以下是评估工具相关部分的docker-compose.yml配置。
您需要为所有LLM评委提供凭证。
或者,评估工具可以通过--gateway-url http://gateway:3000参数使用外部TensorZero网关。
services: # ...
evaluations: profiles: [evaluations] image: tensorzero/evaluations volumes: - ./config:/app/config:ro environment: - OPENAI_API_KEY=${OPENAI_API_KEY:?Environment variable OPENAI_API_KEY must be set.} # ... and any other relevant API credentials ... - TENSORZERO_CLICKHOUSE_URL=http://chuser:chpassword@clickhouse:8123/tensorzero extra_hosts: - "host.docker.internal:host-gateway" depends_on: clickhouse: condition: service_healthy# ...查看GitHub获取完整的Docker Compose配置。
用户界面
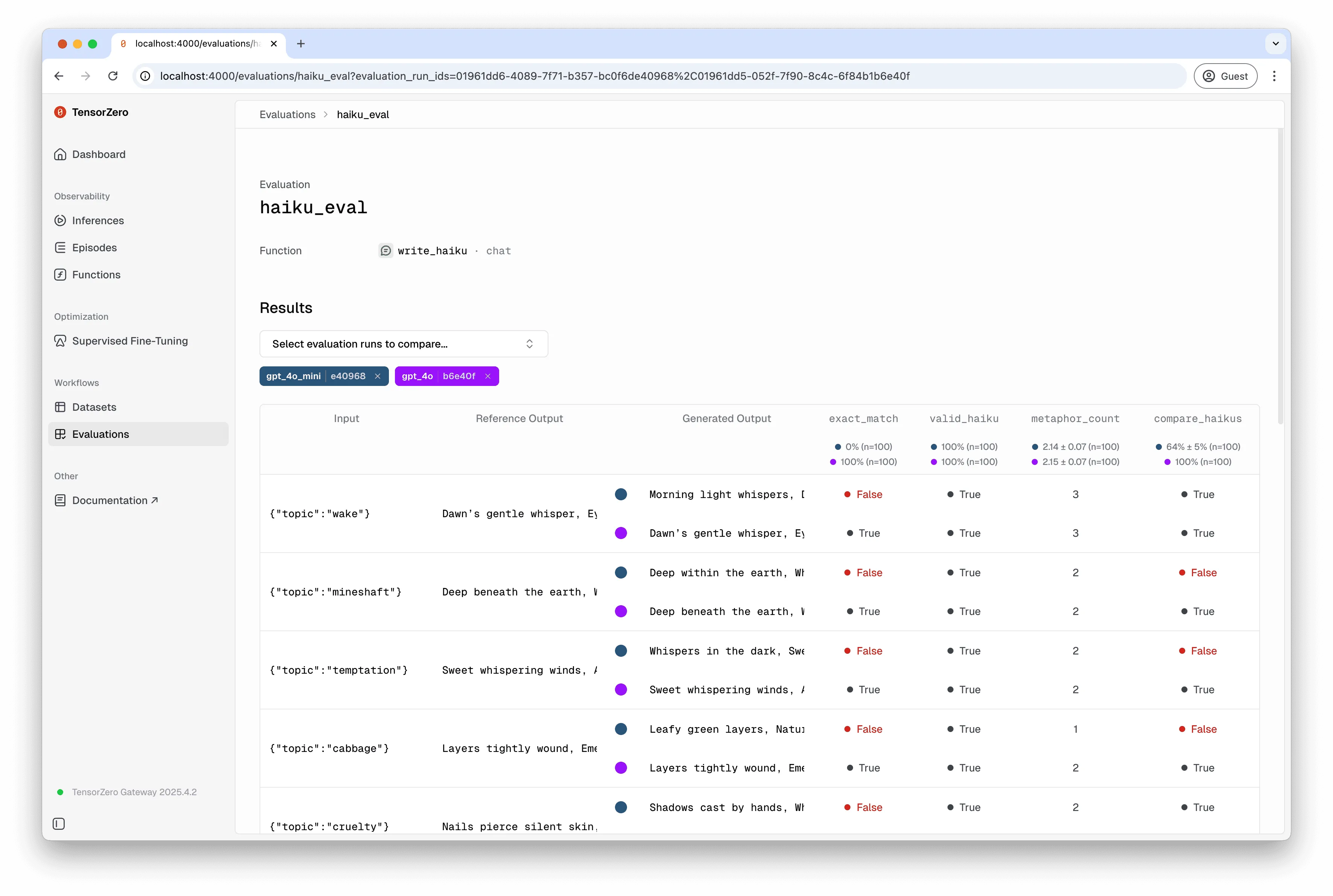
要在用户界面中运行评估,请导航至“评估”页面(http://localhost:4000/evaluations)并选择“新建运行”。
您可以在TensorZero用户界面中比较多个评估运行(包括CLI的评估运行)。