
推理时优化
推理时优化是一种强大的技术,无需进行模型微调即可显著提升您的LLM应用性能。
本指南将探讨TensorZero中作为变体类型实现的两种关键策略:N选优(BoN)采样和动态上下文学习(DICL)。N选优采样通过生成多个候选响应并使用评估模型选择最优解,而动态上下文学习则通过将相关历史示例整合到提示中来增强上下文理解。这两种技术都能显著提升大语言模型应用的响应质量和一致性。
N项最优采样
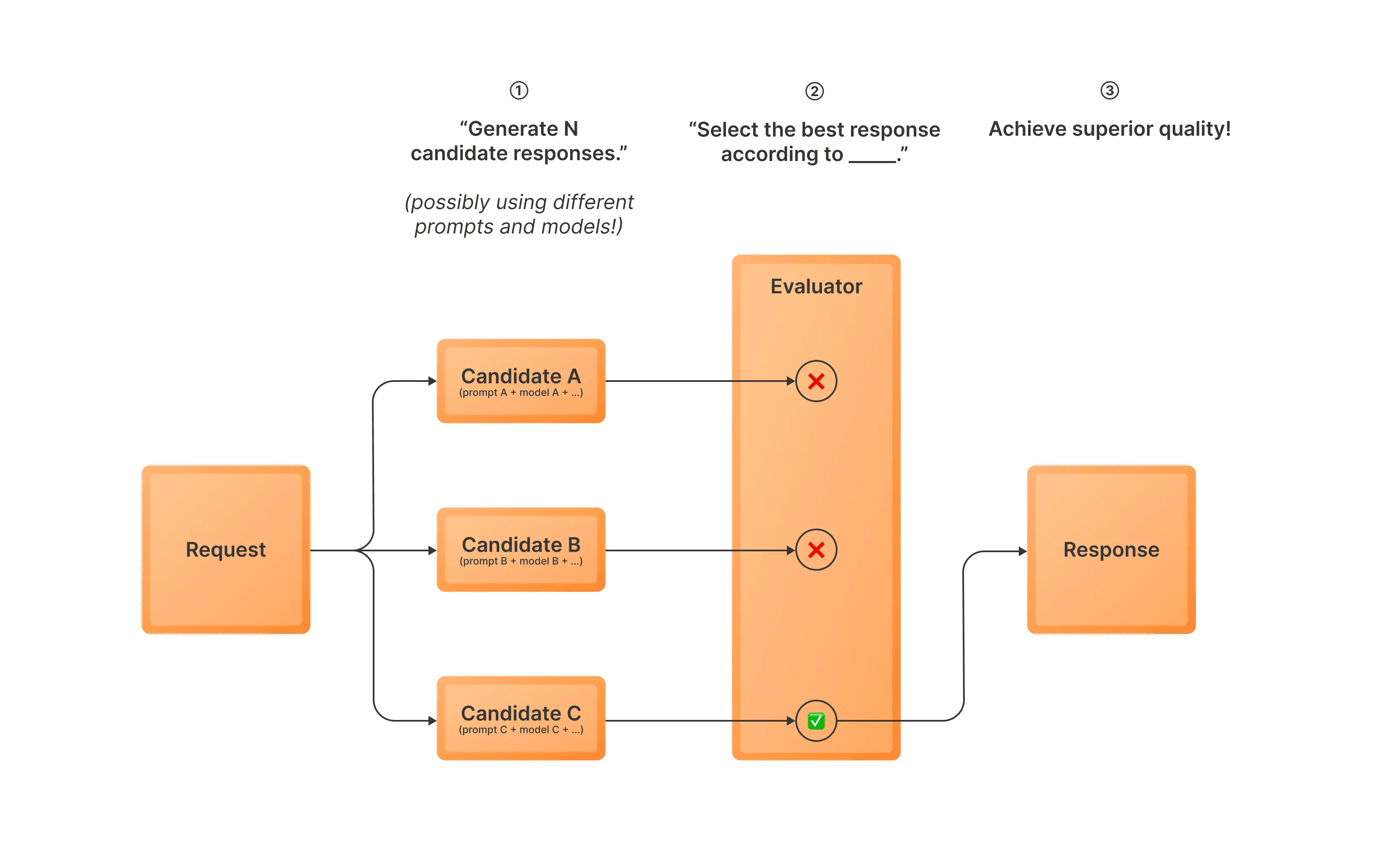
Best-of-N (BoN) 采样是一种推理时优化策略,可以显著提升大语言模型输出的质量。 其工作原理如下:
- 使用一个或多个变体生成多个响应候选(即可能使用不同的模型和提示)
- 使用评估模型从这些候选响应中选择最佳答案
- 将选定的响应作为最终输出返回
这种方法允许您利用多个提示或变体来提高获得高质量响应的可能性。当您希望从多种变体的集合中受益或减少偶尔生成不良结果的影响时,这种方法特别有用。在某些情况下,Best-of-N采样通常也被称为拒绝采样。
要在TensorZero中使用BoN采样,您需要配置一个带有experimental_best_of_n类型的变体。
以下是一个简单的配置示例:
[functions.draft_email.variants.promptA]type = "chat_completion"model = "gpt-4o-mini"user_template = "functions/draft_email/promptA/user.minijinja"
[functions.draft_email.variants.promptB]type = "chat_completion"model = "gpt-4o-mini"user_template = "functions/draft_email/promptB/user.minijinja"
[functions.draft_email.variants.best_of_n]type = "experimental_best_of_n"candidates = ["promptA", "promptA", "promptB"]weight = 1
[functions.draft_email.variants.best_of_n.evaluator]model = "gpt-4o-mini"user_template = "functions/draft_email/best_of_n/user.minijinja"在此配置中:
- 我们定义了一个
best_of_n变体,它使用两种不同的变体(promptA和promptB)来生成候选方案。 该变体会使用promptA生成两个候选方案,同时使用promptB生成一个候选方案。 evaluator模块用于指定模型和选择最佳回复的指令。
了解更多关于experimental_best_of_n变体类型的信息,请参阅配置参考。
思维链 (CoT)

思维链(Chain-of-Thought,简称CoT)是一种推理时优化策略,通过鼓励模型在生成最终答案前进行逐步推理,从而提升大语言模型的性能。 该技术促使模型对问题进行深入思考,使其更有可能产生正确且连贯的响应。
experimental_chain_of_thought 变体类型仅适用于对JSON函数的非流式请求。
对于聊天功能,我们建议改用推理模型(例如OpenAI o3、DeepSeek R1)。
要在TensorZero中使用思维链(CoT),您需要配置一个类型为experimental_chain_of_thought的变体。
它使用与chat_completion变体相同的配置。
在底层实现中,TensorZero会在目标输出模式前添加一个额外字段来包含思维链推理过程,并在最终输出时移除该字段。 这些推理数据会被存储在数据库中,用于后续的可观测性分析和优化。
动态上下文学习 (DICL)
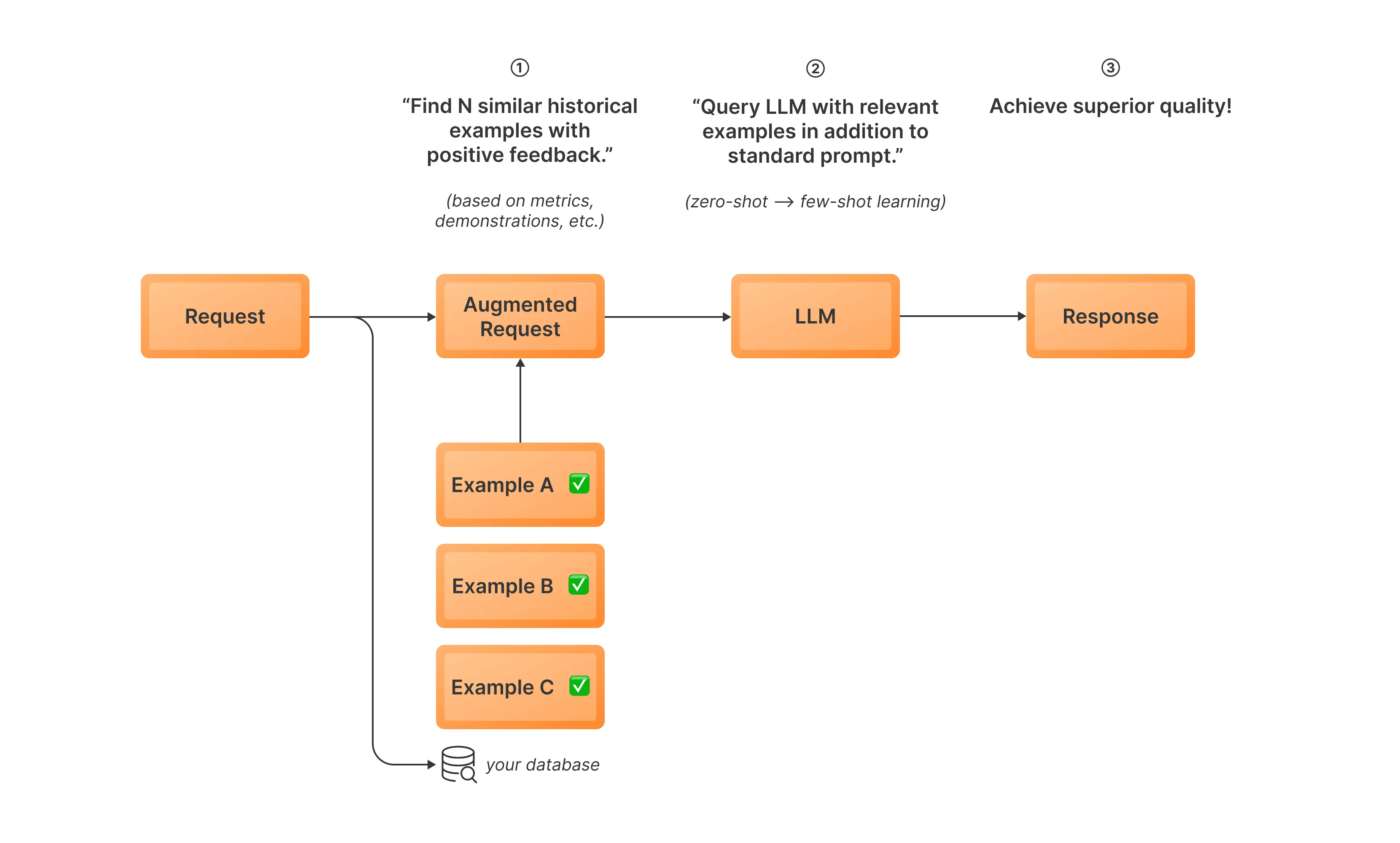
动态上下文学习(DICL)是一种推理时优化策略,它通过将相关历史示例融入提示词来提升大语言模型的性能。 该技术利用过往交互数据库,在当前提示中选择并包含上下文相似的示例,使模型无需微调即可适应特定任务或领域。 通过动态地使用相关历史数据增强输入,DICL使大语言模型能够做出更明智和准确的响应,有效地实现从过往经验中实时学习。
工作原理如下:
- 推理前:整理参考示例,将其嵌入并存储到数据库中
- 使用嵌入模型对当前输入进行嵌入,并从过往交互数据库中检索相似的高质量示例
- 将这些示例整合到提示中,以提供额外的上下文
- 使用增强提示生成响应
要在TensorZero中使用DICL,您需要配置一个带有experimental_dynamic_in_context_learning类型的变体。
以下是一个简单的配置示例:
[functions.draft_email.variants.dicl]type = "experimental_dynamic_in_context_learning"model = "gpt-4o-mini"embedding_model = "text-embedding-3-small"system_instructions = "functions/draft_email/dicl/system.txt"k = 5
[embedding_models.text-embedding-3-small]routing = ["openai"]
[embedding_models.text-embedding-3-small.providers.openai]type = "openai"model_name = "text-embedding-3-small"在此配置中:
- 我们定义了一个使用
experimental_dynamic_in_context_learning类型的dicl变体。 embedding_model字段指定用于对输入进行嵌入以进行相似性搜索的模型。 我们还需要在embedding_models部分定义这个模型。k参数决定了检索并整合到提示中的相似示例数量。
要使用动态上下文学习(DICL),您还需要在ClickHouse数据库的DynamicInContextLearningExample表中添加相关示例。
这些示例将被DICL变体用于在推理时增强提示的上下文。
将这些示例添加到数据库的过程对于DICL正常运行至关重要。 我们提供了一个简化此过程的示例方案:Dynamic In-Context Learning with OpenAI。
本方案支持基于布尔指标、浮点指标和演示示例进行筛选。它帮助您从历史数据中选取高质量相关示例,填充DynamicInContextLearningExample表。
有关DynamicInContextLearningExample表及其在TensorZero数据模型中作用的更多信息,请参阅数据模型。
如需查看experimental_dynamic_in_context_learning变体类型的完整配置选项列表,请参阅配置参考。
混合N采样
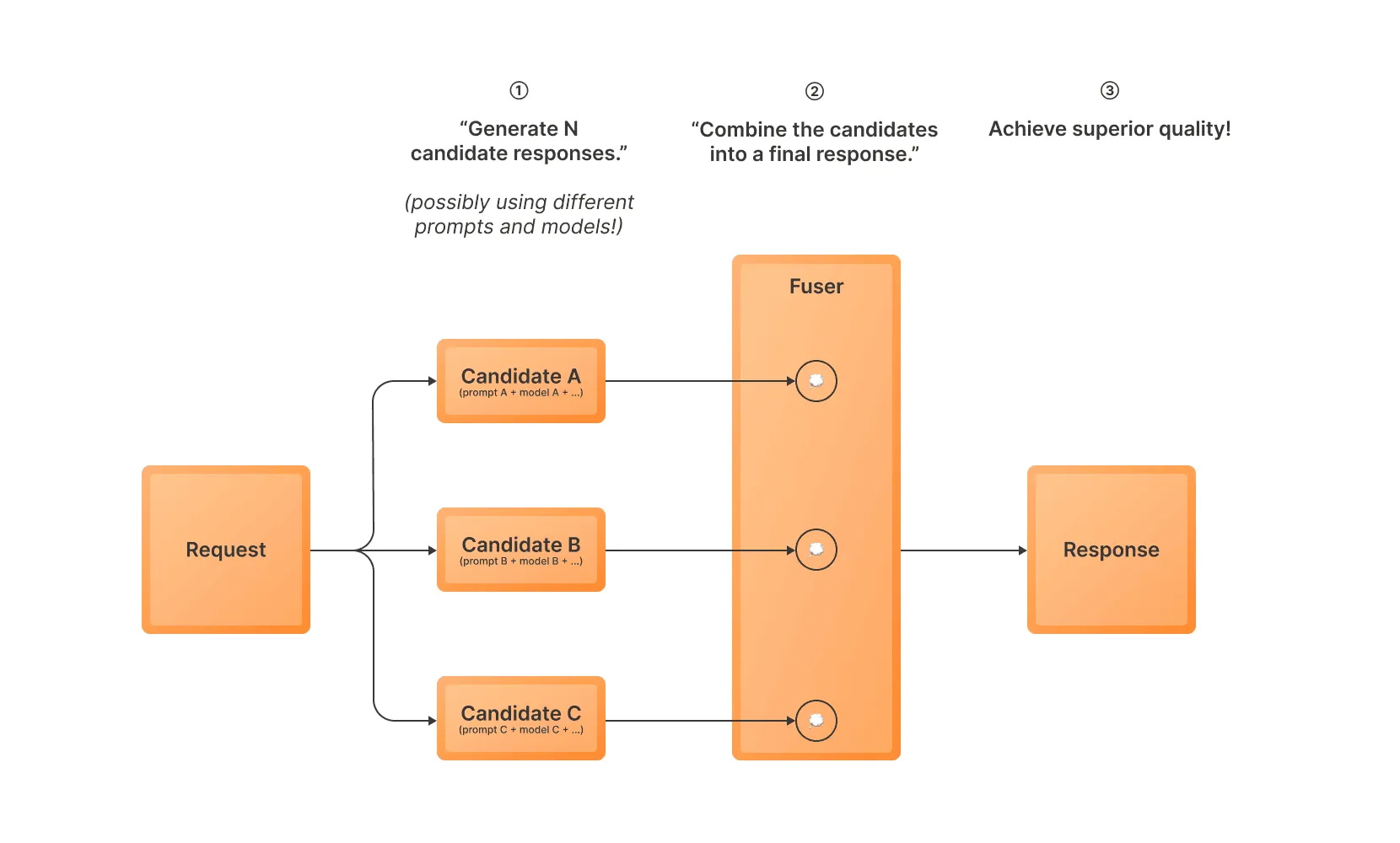
混合N采样(MoN)是一种推理时优化策略,能显著提升大语言模型的输出质量。其工作原理如下:
- 使用一个或多个变体生成多个响应候选(即可能使用不同的模型和提示)
- 使用融合模型将候选结果合并为单一响应
- 返回组合后的响应作为最终输出
这种方法允许您利用多个提示或变体,以提高获得高质量响应的可能性。当您希望从多种变体的组合中受益或减少偶尔生成不良结果的影响时,这种方法尤为有用。
要在TensorZero中使用MoN采样,您需要配置一个带有experimental_mixture_of_n类型的变体。
以下是一个简单的配置示例:
[functions.draft_email.variants.promptA]type = "chat_completion"model = "gpt-4o-mini"user_template = "functions/draft_email/promptA/user.minijinja"weight = 0
[functions.draft_email.variants.promptB]type = "chat_completion"model = "gpt-4o-mini"user_template = "functions/draft_email/promptB/user.minijinja"weight = 0
[functions.draft_email.variants.mixture_of_n]type = "experimental_mixture_of_n"candidates = ["promptA", "promptA", "promptB"]weight = 1
[functions.draft_email.variants.mixture_of_n.fuser]model = "gpt-4o-mini"user_template = "functions/draft_email/mixture_of_n/user.minijinja"在此配置中:
- 我们定义了一个
mixture_of_n变体,它使用两种不同的变体(promptA和promptB)来生成候选方案。 它会使用promptA生成两个候选方案,并使用promptB生成一个候选方案。 fuser模块指定了将候选结果合并为单一响应的模型和指令。
了解更多关于experimental_mixture_of_n变体类型的信息,请参阅配置参考。