教程#
学习AdalFlow库中每个核心部分背后的原因和操作方法(自定义和集成)。 这些是您继续构建端到端用例之前最重要的教程。
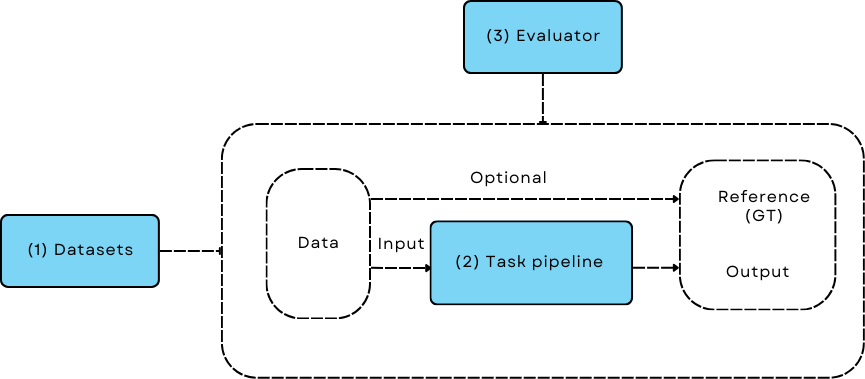
LLM 应用程序与模式训练/评估工作流没有区别#
AdalFlow 库专注于为开发者提供构建块,以构建和优化任务管道。 我们有一个明确的设计理念,这导致了类层次结构的形成。
介绍#
Component 对于LLM任务管道的作用,就像 nn.Module 对于PyTorch模型的作用一样。 AdalFlow中的LLM任务管道主要由组件组成,例如 Prompt、ModelClient、Generator、Retriever、Agent 或其他自定义组件。 这个管道可以是 Sequential 的,也可以是一个有向无环图(DAG)的组件。 Prompt 将与 DataClass 一起工作,以简化与LLM模型的数据交互。 Retriever 将与数据库一起工作,以检索上下文并克服LLM的幻觉和知识限制,遵循检索增强生成(RAG)的范式。 Agent 将与工具和LLM规划器一起工作,以增强推理、规划和执行现实世界任务的能力。
此外,AdalFlow的亮点在于所有编排组件,如Retriever、Embedder、Generator和Agent,都是模型无关的。 你可以通过更换ModelClient及其model_kwargs,轻松使每个组件与来自不同提供商的不同模型一起工作。
我们将从核心基础类开始介绍这个库,然后转向RAG基础,最后是代理基础。 通过这些构建模块,我们将进一步介绍优化,其中优化器使用诸如用于自动提示的Generator和用于动态少样本上下文学习(ICL)的retriever等构建模块。
构建#
基类#
代码路径: adalflow.core.
基类 |
描述 |
|---|---|
任务管道的构建块。它通过call、acall和__call__方法标准化了所有组件的接口,处理状态序列化、嵌套组件和优化参数。组件可以通过 |
|
数据的基础类。它简化了与LLMs的数据交互,用于提示格式化和输出解析。 |
RAG 基础#
RAG组件#
代码路径:adalflow.core。对于抽象类:
ModelClient: 功能子类位于 adalflow.components.model_client。Retriever: 功能子类位于 adalflow.components.retriever。
部分 |
描述 |
|---|---|
基于jinja2构建,它以编程方式灵活地格式化提示作为生成器的输入。 |
|
标准的协议,用于将LLMs、嵌入模型、排名模型等集成到各自的编排器组件中,无论是通过API还是本地方式,以实现模型无关。 |
|
orchestrator 用于LLM预测。它简化了三个组件:ModelClient、Prompt 和 output_processors,并与优化器一起工作以优化提示。 |
|
LLM输出的解释器。该组件将输出字符串解析为结构化数据。 |
|
负责协调模型客户端(特别是嵌入模型)和输出处理器的组件。 |
|
所有检索器的基础类,特别是从给定数据库中检索相关文档,以向生成器添加上下文。 |
数据管道和存储#
数据处理:包括转换器、管道和存储。代码路径:adalflow.components.data_process,adalflow.core.db,和adalflow.database。
组件处理一系列Document并返回一系列Document。
部分 |
描述 |
|---|---|
将长文本分割成较小的块,以适应嵌入器和生成器的令牌限制,或确保在RAG中使用时具有更相关的上下文。 |
|
理解数据建模、处理和存储作为一个整体。我们将在本笔记中构建一个具有增强记忆和记忆检索功能的聊天机器人(RAG)。 |
将所有内容整合在一起#
部分 |
描述 |
|---|---|
根据最先进的研究和行业最佳实践的全面RAG手册。 |
代理基础#
components.agent 中的代理是 LLM,擅长推理、规划和使用工具来交互和完成任务。
部分 |
描述 |
|---|---|
提供工具(函数调用)以与生成器进行交互。 |
|
ReactAgent。 |
优化#
AdalFlow自动优化提供了一个强大且统一的框架,用于优化提示的每个部分:(1) 指令,(2) 少量示例,以及(3) 提示模板,适用于您刚刚构建的任何任务流程。我们利用了从Dspy、Text-grad、ORPO到我们自己在库中的研究的所有最先进的提示优化技术。
优化要求用户至少有一个数据集、一个评估器,并定义要使用的优化器。 本节我们将简要介绍库中支持的数据集和评估指标。
评估#
你无法优化你无法衡量的东西。 在本节中,我们提供了一个关于评估数据集、指标和方法的通用指南,以将你的LLM任务投入生产并发布你的研究。
培训#
代码路径: adalflow.optim.
Adalflow 定义了四个重要的类用于自动优化:(1) Parameter,类似于 PyTorch 中的 nn.Tensor 的角色,
(2) Optimizer,(3) AdalComponent 用于定义训练和验证步骤,以及 (4) Trainer 用于在数据加载器或数据集上运行训练和验证步骤。
我们将首先介绍这些类,从它们的设计到每个类提供的重要特性。
类#
注意:本节文档正在编写中。
部分 |
描述 |
|---|---|
parameter_ |
Parameter 类存储文本、文本梯度(反馈),并管理状态,在自动微分中应用反向传播。 |
optimizer_ |
用于定义结构并管理propose、revert和step方法的Optimizer。我们定义了两个变体:DemoOptimizer和TextOptimizer,以涵盖提示优化和少样本优化。 |
few_shot_optimizer_ |
继承自 |
auto_text_grad_ |
继承自 |
adalcomponent_ |
|
trainer_ |
|
日志记录与追踪#
代码路径: adalflow.utils 和 adalflow.tracing.
部分 |
描述 |
|---|---|
AdalFlow 使用原生的 |
|
我们提供两种追踪方法,以帮助您开发和改进生成器: 1. 在开发过程中追踪提示的历史变化(状态)。 2. 将所有失败的LLM预测追踪到一个统一的文件中,以便进一步改进。 |