
RAG 操作手册#
注意
本教程仍在不断完善中。我们将继续更新和改进它。 如果您有任何反馈,请随时通过以下任一方式与我们联系: 社区。
在本手册中,我们将根据最先进的研究和行业最佳实践提供全面的RAG手册。 手册的大纲如下:
RAG 概述
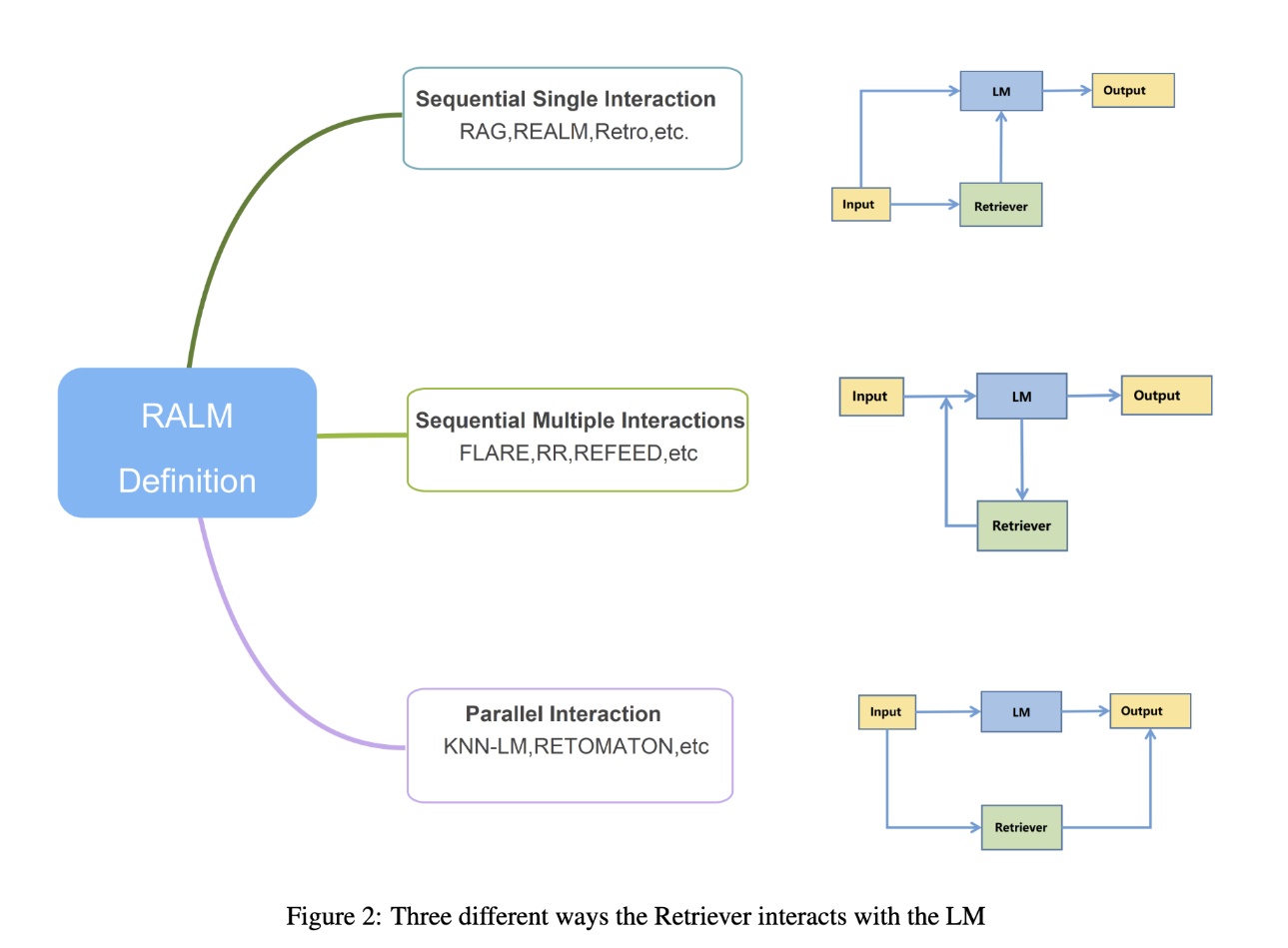
从第一篇RAG论文到多样化的RAG设计架构
每个组件的RAG设计和调优策略
RAG 概述#
检索增强生成(RAG)是一种结合检索优势的范式,旨在消除大型语言模型(LLMs)的幻觉和知识截止问题,并作为一种适应任何特定领域知识库的方式。 此外,能够引用知识来源对于任何AI用例的透明度和可解释性都是一个巨大的优势。
RAG_PROMPT_TEMPLATE = r"""<START_OF_SYSTEM_MESSAGE>
{{task_desc}}
<END_OF_SYSTEM_MESSAGE>
<START_OF_USER>
{{input_str}}
{{context_str}}
<END_OF_USER>
"""
给定一个用户查询,RAG 从一个大语料库中检索相关段落,然后基于检索到的段落生成响应。 这种形式开启了广泛的应用场景,如对话式搜索引擎、定制知识库上的问答、 客户支持、事实核查。 上面的模板展示了 RAG 最常用的格式,其中我们传递任务描述,连接输入字符串,并将检索到的段落放入上下文字符串中,然后将其传递给 LLM 模型进行生成。
但是,RAG远不止这些。让我们深入了解一下。
首批RAG论文
RAG 由 Meta 的 Lewis 等人于 2020 年提出 [1],它是一种架构,通过仅对最终答案进行监督,联合微调查询编码器(类似于大多数嵌入模型的双编码器)和生成器(LLM)。
REALM [7] 是同年由谷歌引入的另一个RAG模型,它不仅在下游任务中对检索器和生成器进行了微调,还通过使用掩码语言模型(MLM)在简单文本中随机掩码标记来联合预训练这两个模型。
最初的论文没有提到文档分块,因为在大多数情况下,它们的文本长度通常较短,并且也适合嵌入模型的上下文长度。 随着嵌入模型和LLM模型在知识和参数方面的扩展(论文中使用了400M的LLM模型),RAG可以在少样本(提示工程)设置中实现高性能,而无需进行微调。
然而,RAG的灵活性也意味着它需要仔细的设计和调优才能达到最佳性能。 对于每个用例,我们需要考虑以下问题:
使用哪种检索方式?它应该有多少个阶段?我们需要一个重新排序器甚至LLM来帮助检索阶段吗?
哪种云数据库能够很好地配合检索策略并且能够扩展?
如何评估RAG的整体性能?有哪些指标可以帮助我特别理解检索阶段,以便我知道它不会损害整体性能?
我是否需要查询扩展或其他技术来提高检索性能?如何避免由于向LLM提供不相关段落而导致的性能下降?
如何优化RAG超参数,例如检索到的段落数量、块的大小、块之间的重叠,甚至是分块策略?
有时你甚至需要创建自己的定制/微调的嵌入/检索模型。我该怎么做?
如何使用零样本提示和少样本提示通过上下文学习(ICLs)自动优化RAG管道?
关于微调呢?如何进行微调,它会更节省令牌还是更有效?
设计RAG#
RAG组件 |
技术 |
指标 |
|---|---|---|
数据准备 |
|
|
数据存储 |
|
|
嵌入 |
|
|
索引 |
||
检索 |
|
|
生成器 |
|
|
待办事项:将其制作成一个可以放入链接的表格。这样我就可以将其他教程链接在一起,形成一个全面的指南。
对于基准测试数据集和指标,请参考评估指南。 此外,FlashRAG [3] 提供了更多关于RAG数据集和研究的参考资料。
数据准备管道#
文档检索与重新排序#
在Retriever中引入了从最便宜、最快、最不准确到最昂贵、最慢、最准确的多阶段检索。
RAG优化#
我们可以分别优化每个组件,例如为检索器或生成器设计的研究,或者在RAG的背景下联合优化它们。 有时我们可以使用一种代理方法,例如Self-RAG [11]。
#TODO: 拟合水文
检索优化
由于不相关的段落,特别是那些位于上下文顶部的段落,可能会降低最终性能,因此优化检索性能尤为重要: 我们有以下选项:
超参数优化:优化检索到的段落数量、块的大小以及块之间的重叠,甚至使用检索器评估指标或最终生成器性能来优化分块策略。
查询扩展:通过扩展查询来提高召回率。
使用LLM监督调整嵌入器:通过LLM监督调整嵌入器,以提高检索的召回率和精确度。
重新排序:使用重新排序器作为附加阶段以提高检索准确性。
使用检索评估器:使用检索评估器来评估检索到的段落的相关性。
生成器优化
自从第一篇RAG论文发表以来,许多具有高参数数量和性能的LLM已经发布。 上下文学习(ICL)或提示工程已成为优化生成器在任何任务上性能的首选方法,而不是模型微调。 你可以使用任何旨在提高生成器推理能力的优化方法,例如思维链、反思等。
当在RAG的上下文中使用Generator时,我们需要考虑(检索到的上下文、查询和生成的响应)之间的关系。 我们需要在以下方面优化生成器:
它如何利用相关上下文生成响应?是否被不相关的段落误导?
对于生成器,我们有三个流行的选择:
提示工程:使用零样本或少样本学习来优化生成器,或通过更多的测试时标记(例如,思维链、反思)来改进生成器的响应。
通过指令学习微调生成器
特别针对使用上下文的格式微调生成器。
未来,我们将提供一个提示工程/ICL手册,目前我们将跳过这一部分。
检索优化#
查询转换
查询扩展(QE)[16]是搜索引擎中常用的一种技术,用于扩展用户的搜索查询以包含更多文档。
在这个LLM的新时代,查询可以通过LLM进行重写/扩展。
查询重写
通过提示工程让LLM重写初始查询\(x\)为\(x' = LLM(Prompt(x))\),我们最终优化了检索器的性能,而无需像Lewis等人的论文[1]那样重新训练检索器。 通过利用AdalFlow的上下文内训练器,我们可以自动端到端优化RAG管道。 唯一的缺点是会使用更多的LLM模型的令牌预算,最终会导致更高的成本。
这里我们总结了一些方法并介绍了AdalFlow的API。
查询重写论文 [17] 提出了两种使用LLM进行重写的方法:
Few-shot prompt: 鼓励LLM“推理”并输出与输入查询相关的一个、多个或不输出查询。
可训练方案:使用较小的重写器模型来重写查询,而不是使用黑箱LLM,以降低成本。
重写器通过强化学习使用生成器的反馈进行训练。 它有两个训练阶段:预热阶段,使用导致生成器正确响应的\((x, x')\)对的合成数据集来微调重写器。 然后,重写器通过强化学习进行训练,以与检索器和生成器对齐。
使用LLM监督调整嵌入器
为了提高检索的召回率和精确度,我们可以通过LLM监督来调整嵌入器。 最便宜的解决方案只需要在嵌入模型之上添加一个线性层,并使用LLM模型从数据源生成的查询-段落对合成数据集。 这种方法也适用于黑盒嵌入模型。AdalFlow未来将考虑开源这项技术。
第二种方法是直接微调嵌入器。Replug [6] 是这种方法的一个很好的例子。 Replug 可以在微调或不微调的情况下使用。
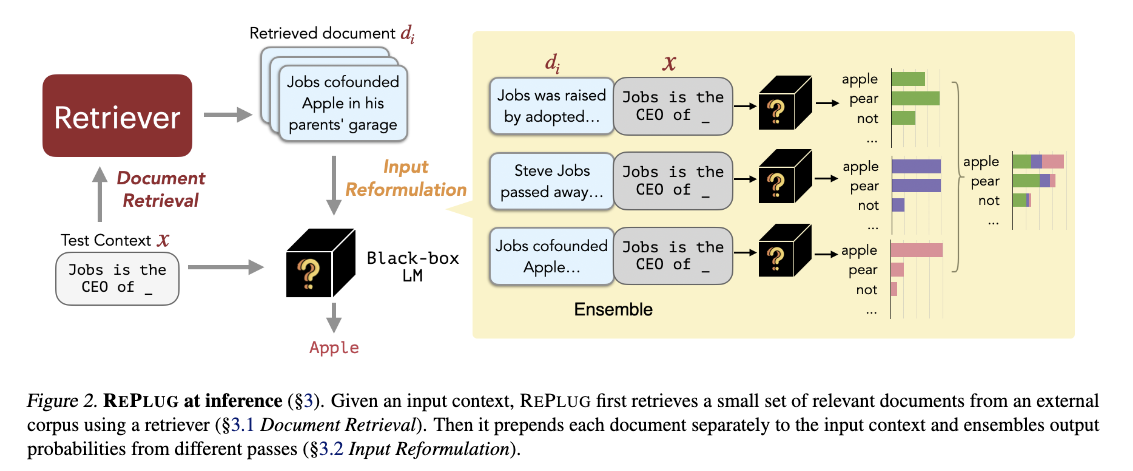
当我们进行Replug时,它会并行计算每个查询和文档对的LLM输出,并将所有输出集成以获得最终分数。 这对于推理速度特别有帮助,并且超越了LLM模型的上下文长度限制。
重新排序
Rerankers 通常是查询和文档之间的交叉编码器。它在计算上更昂贵,但也更准确。Cohere 和 Transformers 都提供了最先进的 rerankers。
使用检索评估器
C-RAG [10] 提出了一种轻量级的检索评估器,该评估器在测试数据集的训练分割上进行了微调。更昂贵但无需训练模型的方法是,我们可以使用LLM来分类检索到的段落的相关性,使用诸如“正确”、“错误”、“模糊”等标签。
生成器优化#
除了上述三种流行的选项外,还有一个研究分支,其中检索到的上下文在生成器(增强生成器)中作为模型的一部分进行整合,而不是简单地从提示中组合。
RAG 管道优化#
我们介绍了RAG管道的三种流行的整体优化策略。
自我RAG#
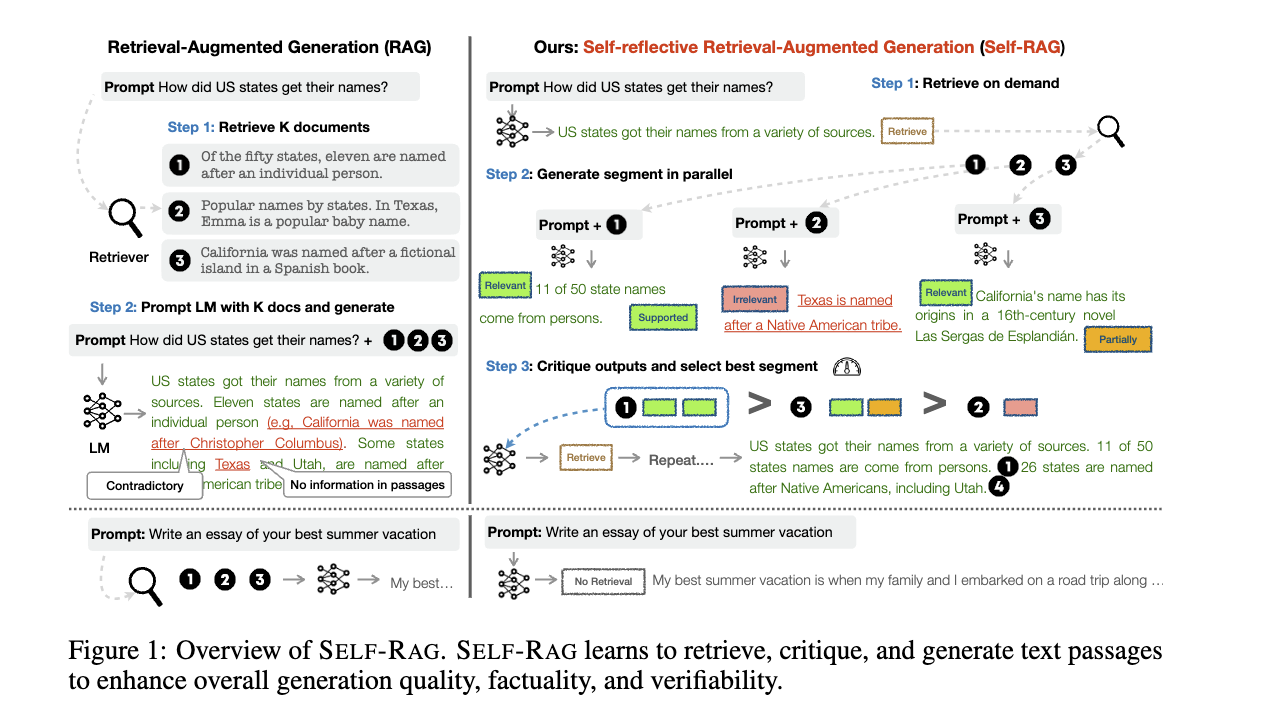
Self-RAG 很有趣,因为它被编程为决定是否需要检索,它并行地处理检索到的段落,为每个查询 x 和段落 d_t 生成 y_t。 对于每个 (x, d_t, y_t) 对,它“反映”在三个指标上:
ISREL: 使用 (x, d_t) 来检查 d_t 是否提供有用的信息以解决 x,通过输出两个标签 (is_relevant, is_irrelevant)。
ISSUP: 使用 (x, d_t, y_t) 来检查 y_t 中所有有价值的陈述(回答问题的部分)是否由 d_t 支持,通过输出三个标签(is_supported, partically_supported, not_supported)。
ISUSE: 使用 (x, y_t) 来检查 y_t 是否有助于解决 x,通过输出 5 个标签 (5, 4, 3, 2, 1)。
它计算一个统一三个指标的单一分段分数,并使用它来重新排序答案,并选择分数最高的答案作为最终答案。 论文还提到了如何创建合成的训练数据集并训练critic和generator模型。 好消息是Self-RAG可以在微调或不微调的情况下使用。
Self-RAG 可以应用于需要高精度的复杂任务,但它比普通的 RAG 复杂得多。
领域#
REALM [7] 非常有趣,并且它有一个明确的优化目标。

检索-然后-预测过程
REALM 将任务建模为一个“检索然后预测”的过程:
首先,检索器根据输入\(x\)从大型知识库\(Z\)中采样文档\(z\)。这种检索由\(p(z | x)\)建模,即在给定输入\(x\)的情况下检索文档\(z\)的概率。
然后,模型根据输入\(x\)和检索到的文档\(z\)预测缺失的单词或答案,建模为\(p(y | z, x)\),其中\(y\)是预测结果(例如,被遮蔽的标记或答案)。
对所有可能的文档进行边缘化
给定输入\(x\),正确预测目标输出\(y\)的概率是通过对知识库\(Z\)中所有可能的文档进行边缘化计算得出的:
这意味着总体概率是每个文档\(z\)帮助预测\(y\)的加权和,权重由检索器对该文档的信念\(p(z | x)\)决定。
损失函数和梯度优化
优化检索器的关键在于通过调整检索相关文档的概率\(p(z | x)\)来最大化正确预测\(y\)的可能性。 正确预测\(y\)的对数似然是训练目标:
奖励相关文档
要了解检索器是如何被奖励或惩罚的,考虑关于检索器评分函数 \(f(x, z)\) 的对数似然梯度(该函数衡量文档 \(z\) 与输入 \(x\) 的相关性):
这是如何工作的:
如果文档 \(z\) 改进了对 \(y\) 的预测(即 \(p(y | z, x) > p(y | x)\)),梯度为正,检索器被鼓励增加分数 \(f(x, z)\),使其在未来更有可能检索到该文档。
如果文档 \(z\) 没有帮助(即 \(p(y | z, x) < p(y | x)\)),梯度为负,鼓励检索器降低分数 \(f(x, z)\),使其不太可能检索到该文档。