数据集与资产 (.datasets)#
预计阅读时间:8分钟
你将学习的内容#
本指南旨在帮助您熟悉可在Datasite服务器上托管的数据集和资产。
简介#
PySyft中的数据集是让研究人员能够以远程方式对无法直接访问的私有数据进行研究的关键。PySyft服务器上可以托管两种类型的数据:
私有数据: 由于敏感性质和相关风险而无法公开的原始数据
模拟数据: 一种模仿原始数据的虚拟版本,至少保留数据集结构和数值分布特征。这类数据可以完全从头生成,也可以是具有适当隐私保障的合成版本。
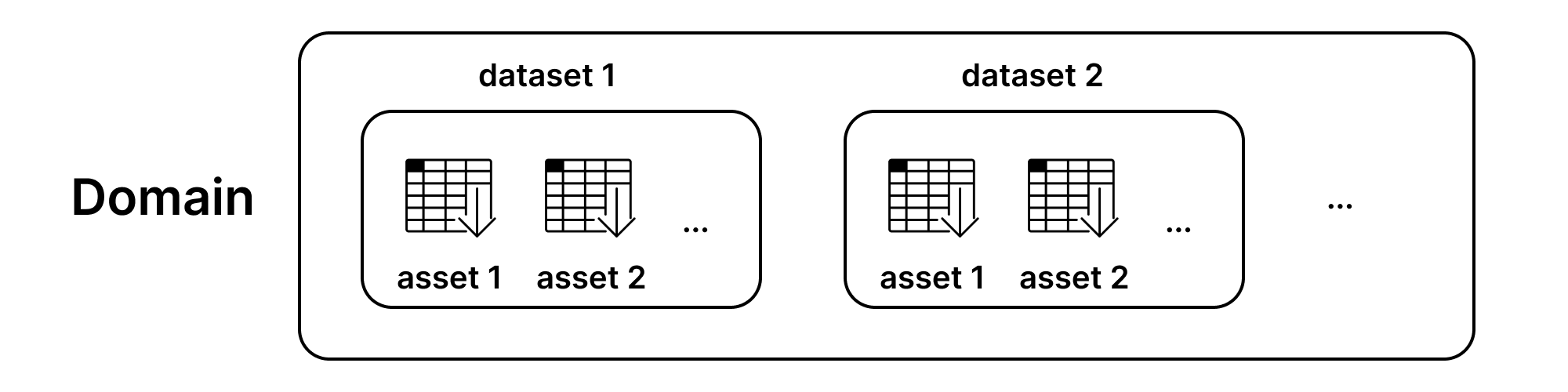
这两个数据集都属于一个名为Asset的对象,该对象具有双重行为——它既是指向私有数据的指针,又可以根据权限设置让用户访问私有数据或模拟数据。此外,相关的资产会被方便地分组到Dataset对象下,从而能够更广泛地描述这些资产。
构建数据集与资产#
一个Syft数据集可以包含一个或多个Syft资产。
警告
资产必须归属于某个数据集,不能单独上传。
以下是几个关于如何在数据集中组织资产的示例:
示例1:训练与测试数据
该数据集由两个资产组成,一个包含测试数据,另一个包含训练数据。这两部分可以一起上传到同一个数据集中。
示例2:时序数据
该数据集由不同时间段收集的多个资产组成,例如data-july-14.csv、data-july-17.csv和data-august-12.csv。这三个资产都可以上传到同一个数据集中。
低端与高端配置的差异#
具体部署尤其由跨服务器的数据安排所定义:低端服务器可以仅托管模拟数据,而高端服务器则享有额外的安全性优势,可以包含私有数据。
以这种方式配置服务器不需要自定义配置。唯一需要注意的方面是永远不要在低安全级别上传包含私有数据的Asset。
警告
记住!
私有(或敏感)数据必须仅在高安全级别服务器上上传。
低权限服务器只能包含模拟数据。
对于高安全级别服务器,是否提供模拟数据用于测试目的完全由数据所有者决定。
获取测试数据#
为了展示如何创建数据集和资产并进一步上传,我们现在将启动一个测试服务器,并从下载一个Kaggle数据集开始进行演示(Age Dataset 2023)。
Show code cell source
import syft as sy
server = sy.orchestra.launch(name="test_server", port="auto", dev_mode=False, reset=True)
# logging in with default credentials
do_client = sy.login(email="[email protected]", password="changethis", port=server.port)
!curl -O https://openminedblob.blob.core.windows.net/csvs/ages_dataset.csv
!curl -O https://openminedblob.blob.core.windows.net/csvs/ages_mock_dataset.csv
import pandas as pd
import syft as sy
age_df = pd.read_csv("ages_dataset.csv")
age_df = age_df.dropna(how="any")
age_df.head()
age_mock_df = pd.read_csv("ages_mock_dataset.csv")
age_mock_df = age_mock_df.dropna(how="any")
age_mock_df.head()
创建资产#
要创建一个资产 (syft.Asset),必需的参数包括:
name (type: string): 资产名称,作为同一数据集中资产间的键,必须唯一data: 包含私有数据;如果您正在为低安全域准备资产,也可以用模拟数据替代。mock: 包含模拟数据;这些数据应与私有数据具有相同的结构,但不包含任何敏感信息
提供以下额外参数:
description (type: string): a short description of the asset. It can only be a string, does not suppport Markdown or HTML.countributors (type: list): 一个syft.Contributors列表,用于列出资产数据的作者并指定联系邮箱以便进一步咨询mock_is_real (type: bool): 声明模拟数据是否是从原始数据合成生成的。如果是伪造的,这个值应该设为false。mock.shape (type: tuple): 如果数据是Pandas DataFrame或Numpy Array时的数据形状。data_subjects: 已弃用 - 请勿使用。
注意
高安全级别服务器注意事项
如果您正在向高安全级别服务器上传数据,且没有可用的模拟数据或认为不需要模拟数据,可以传递mock=sy.ActionObject.empty()来表明这一点。
main_contributor = sy.Contributor(name="Jeffrey Salazar", role="Dataset Creator", email="[email protected]")
asset = sy.Asset(
name="asset_name",
description="this is my asset",
data=age_df, # real dataframe
mock=age_mock_df, # mock dataframe
contributors=[main_contributor]
)
Asset中允许的数据类型#
在此设置中,数据直接上传到服务器。唯一支持的数据格式为:
Python 基础类型 (int, string, list, dict, ...)
Pandas 数据框
NumPy数组
如果您想上传自定义数据格式,我们推荐使用blob存储功能。该功能目前处于测试阶段,相关文档将很快添加。
创建数据集#
创建数据集时,可用的参数包括:
name (type: string): 数据集的名称,作为数据集之间的键,必须唯一asset_list (type: [syft.Assets]): 包含作为数据集一部分上传的实际数据的资产列表description (type: string): 关于数据集中数据的简要附加信息;支持markdown格式。
提供以下额外的可选参数:
citation (type: string): 如果使用该数据集时的引用说明url (type: string): 与数据集相关的链接contributors_list (type: [Contributor]): 数据集的贡献者
dataset = sy.Dataset(
name="Dataset name",
description="**Dataset description**",
asset_list=[asset],
contributors=[main_contributor]
)
警告
在低权限端与高权限端部署时保持命名一致 对于低权限端和高权限端的部署场景,确保数据集和资产使用相同的名称至关重要。这能保证在低权限端编写并使用低权限端资产的代码可以轻松在高权限端执行。
数据上传#
要在域上上传数据集,请使用upload_dataset函数。您需要先登录到该域(低权限端或高权限端)。
注意
信息 资产只能作为数据集的一部分上传。
# Uploading the dataset
do_client.upload_dataset(dataset)
访问数据集#
PySyft通过分配给用户的角色来实现访问控制。简要说明:
管理员和数据所有者可以完全访问、更新和删除数据集
数据科学家/访客只能访问他们注册服务器上所有数据集的模拟副本。请注意不要通过mock参数传递私有数据。
# Access is possible via the datasets API
do_client.datasets
# Retrieve one dataset
dataset_retrieved = do_client.datasets[0]
dataset_retrieved
# Retrieve an asset
asset_retrieved = dataset_retrieved.assets[0]
asset_retrieved
# Accessing the mock or private part of an asset directly:
mock_data = dataset_retrieved.assets[0].mock
private_data = dataset_retrieved.assets[0].data
mock_data
请注意,只有管理员/数据所有者可以访问 dataset_retrieved.assets[0].data。
更新数据集#
对于已上传的对象,无法更新数据。相反,您只能在资产或数据集上传之前进行更新。
如需更改已上传的数据集,我们建议您删除并重新创建该对象。
asset.set_description("Updated asset description")
dataset.add_asset(asset, force_replace=True)
do_client.datasets
删除数据集#
建议谨慎进行删除操作,以防被用户的不同代码请求所使用。
do_client.api.dataset.delete(uid = do_client.datasets[0].id)
do_client.datasets
数据集描述#
描述是数据集的重要属性,因为它们是帮助数据科学家理解数据的关键,尽管无法直接访问数据。因此,一份撰写完善、内容全面的描述可以帮助解答问题,并澄清数据科学家可能对数据做出的假设。
Markdown支持#
PySyft允许以Markdown格式编写数据集描述,使数据所有者能够准确记录数据所需的所有信息。因此,您可以直接在Markdown编辑器(Editor.md、Markdown Live Preview)中编写描述,进行编辑和预览直至满意,最终在创建数据集时将最终的Markdown内容复制到描述字段中。
描述可以捕获以下维度:
数据集摘要: 简要说明数据类型(数值型、文本型、图像型或混合型)及来源领域;
数据集使用政策: 描述研究人员在研究过程中必须遵守的数据使用政策,以获得其请求的批准
使用场景: 该数据集被提议用于哪些使用场景
数据收集与预处理: 关于特征如何被收集和/或衍生,以及数据准确性的信息
关键特性: 数据字典,解释数据集中呈现的所有列。如果列之间存在关联关系,建议予以说明
代码片段: 可以包含常见操作的示例代码,例如如何加载数据集以开始使用的代码片段
引用: 如何引用该数据集
让我们来看一个示例
description_template = '''### About the dataset
This extensive dataset provides a rich collection of demographic and life events records for individuals across multiple countries. It covers a wide range of indicators and attributes related to personal information, birth and death events, gender, occupation, and associated countries. The dataset offers valuable insights into population dynamics and various aspects of human life, enabling comprehensive analyses and cross-country comparisons. The dataset is the largest one on notable deceased people and includes individ- uals from a variety of social groups, including but not limited to 107k females, 90k researchers, and 124 non-binary indi- viduals, spread across more than 300 contemporary or histor- ical regions.
### Dataset usage policy
This dataset is subject to compliance with internal data use and mis-use policies at our organisation. The following rules apply:
- only aggregate statistics can be released from data computation
- data subjects should never be identifiable through the data computation outcomes
- a fixed privacy budget of eps=5 must be preserved by each researcher
### Data collection and pre-processing
The dataset is based on open data hosted by Wikimedia Foundation.
**Age**
Whenever possible, age was calculated based on the birth and death year mentioned in the description of the individual.
**Gender**
Gender was available in the original dataset for 50% of participants. For the remaining, it was added from predictions based on name, country and century in which they lived. (97.51% accuracy and 98.89% F1-score)
**Occupation**
The occupation was available in the original dataset for 66% of the individuals. For the remaining, it was added from predictions from a multiclass text classificator model. (93.4% accuracy for 84% of the dataset)
More details about the features can be found by reading the paper.
### Key features
1. **Id**: Unique identifier for each individual.
2. **Name**: Name of the person.
3. **Short description**: Brief description or summary of the individual.
4. **Gender**: Gender/s of the individual.
5. **Country**: Countries/Kingdoms of residence and/or origin.
6. **Occupation**: Occupation or profession of the individual.
7. **Birth year**: Year of birth for the individual.
8. **Death year**: Year of death for the individual.
9. **Manner of death**: Details about the circumstances or manner of death.
10. **Age of death**: Age at the time of death for the individual.
11. **Associated Countries**: Modern Day Countries associated with the individual.
12. **Associated Country Coordinates (Lat/Lon)**: Modern Day Latitude and longitude coordinates of the associated countries.
13. **Associated Country Life Expectancy**: Life expectancy of the associated countries.
### Use cases
- Analyze demographic trends and birth rates in different countries.
- Investigate factors affecting life expectancy and mortality rates.
- Study the relationship between gender and occupation across regions.
- Explore correlations between age of death and associated country attributes.
- Examine patterns of migration and associated countries' life expectancy.
### Getting started
```
!curl -O https://openminedblob.blob.core.windows.net/csvs/ages_dataset.csv
age_df = pd.read_csv("ages_dataset.csv")
```
### Execution environment
The data is hosted in a remote compute environment with the following specifications:
- X CPU cores
- 1 GPU of type Y
- Z RAM
- A additional available storage
### Citation
Annamoradnejad, Issa; Annamoradnejad, Rahimberdi (2022), “Age dataset: A structured general-purpose dataset on life, work, and death of 1.22 million distinguished people”, In Workshop Proceedings of the 16th International AAAI Conference on Web and Social Media (ICWSM), doi: 10.36190/2022.82
'''
# Create a dataset with description
dataset = sy.Dataset(
name="Dataset name with description",
description=description_template,
asset_list=[
sy.Asset(
name="Age Data 2023",
data=age_df,
mock=age_mock_df
)],
contributors=[main_contributor]
)
do_client.upload_dataset(dataset)
do_client.datasets[0]