同步API (.sync)#
预计阅读时间:15分钟
信息
本指南面向数据所有者。
你将学习的内容#
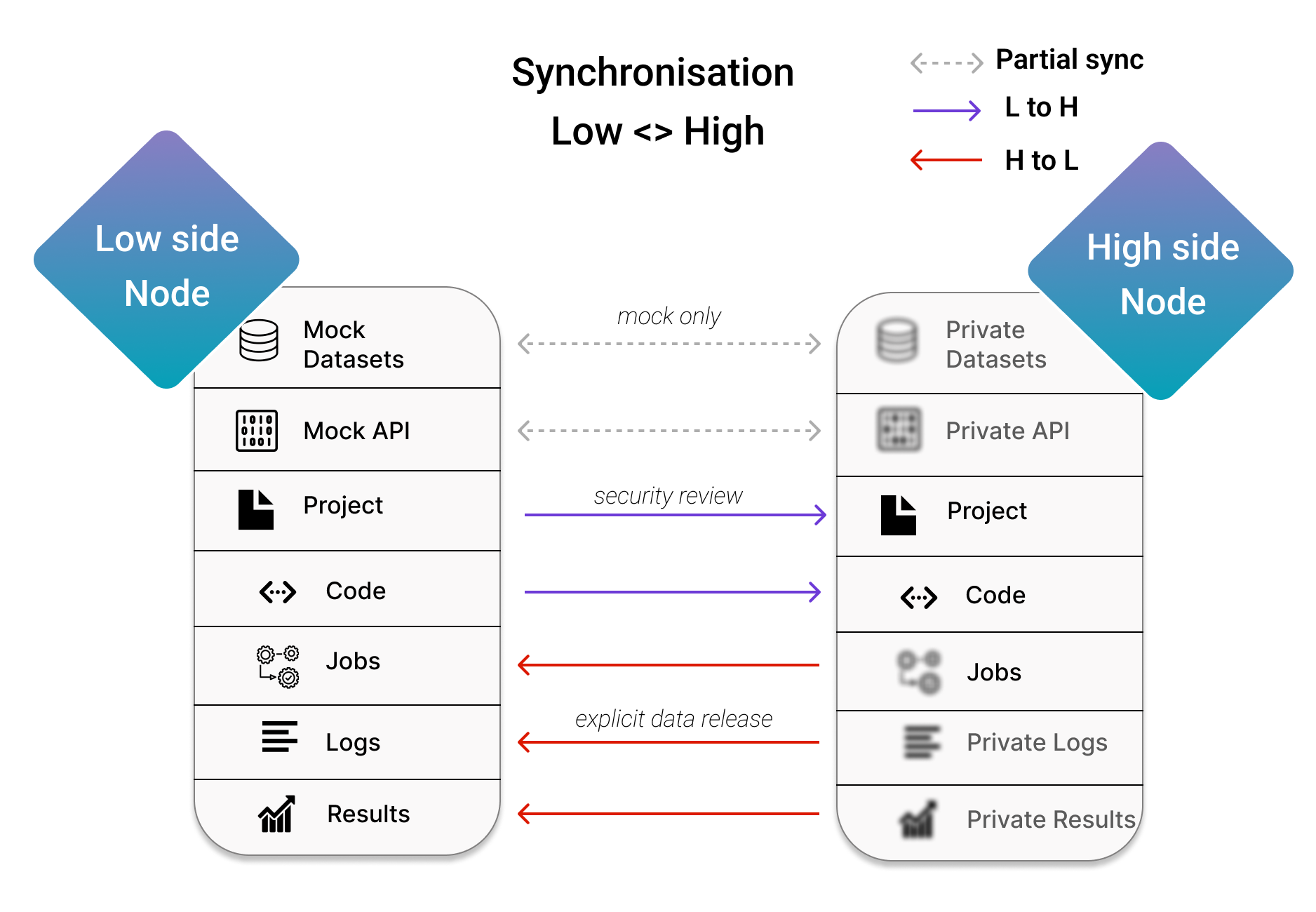
本指南旨在帮助您熟悉在高安全区/低安全区场景下的同步工作原理,该场景中两个不同风险等级的服务器在Datasite下协同工作。
简介#
物理隔离部署对数据所有者带来的安全风险最低。它依赖于一个低安全区服务器(不包含任何机密信息,可被不受信任方无风险访问)和一个高安全区服务器(采用物理隔离,仅数据所有者可访问)。
这种将高安全侧服务器与不安全网络(如公共互联网或不安全的局域网)进行物理隔离的方式,实际上是一台服务器所能获得的最大保护。
同步对于简化在低端服务器与高端服务器之间手动传输信息的过程至关重要。
警告
此功能正在积极开发中,目前处于测试阶段,意味着在某些情况下可能不稳定且容易出现故障。
数据传输#
在低端/高端部署中存在两种不同类型的数据传输:
高安全区到低安全区的数据传输(显式数据释放):由于数据的敏感性,任何从高安全区释放信息都需要数据所有者的明确批准。同步功能通过获取您需要审查的信息并快速发送来简化这一流程。
低安全区到高安全区的数据传输(安全审查):低安全区作为项目入口点和用户代码进入安全私有执行环境(高安全区)的通道。但由于这些内容来自不可信方,可能会引入恶意代码,从而执行侧信道攻击、泄露私有数据或破坏高安全区环境的完整性。因此,同步机制允许您在将数据传输至高安全区前进行充分的安全审查。
这些职责均由数据所有者承担,因为低安全区与高安全区之间的直接连接会构成敏感数据的攻击途径。这也是为什么私有资产无法自动复制,且只有模拟资产能存在于低安全区(在部分同步后)。
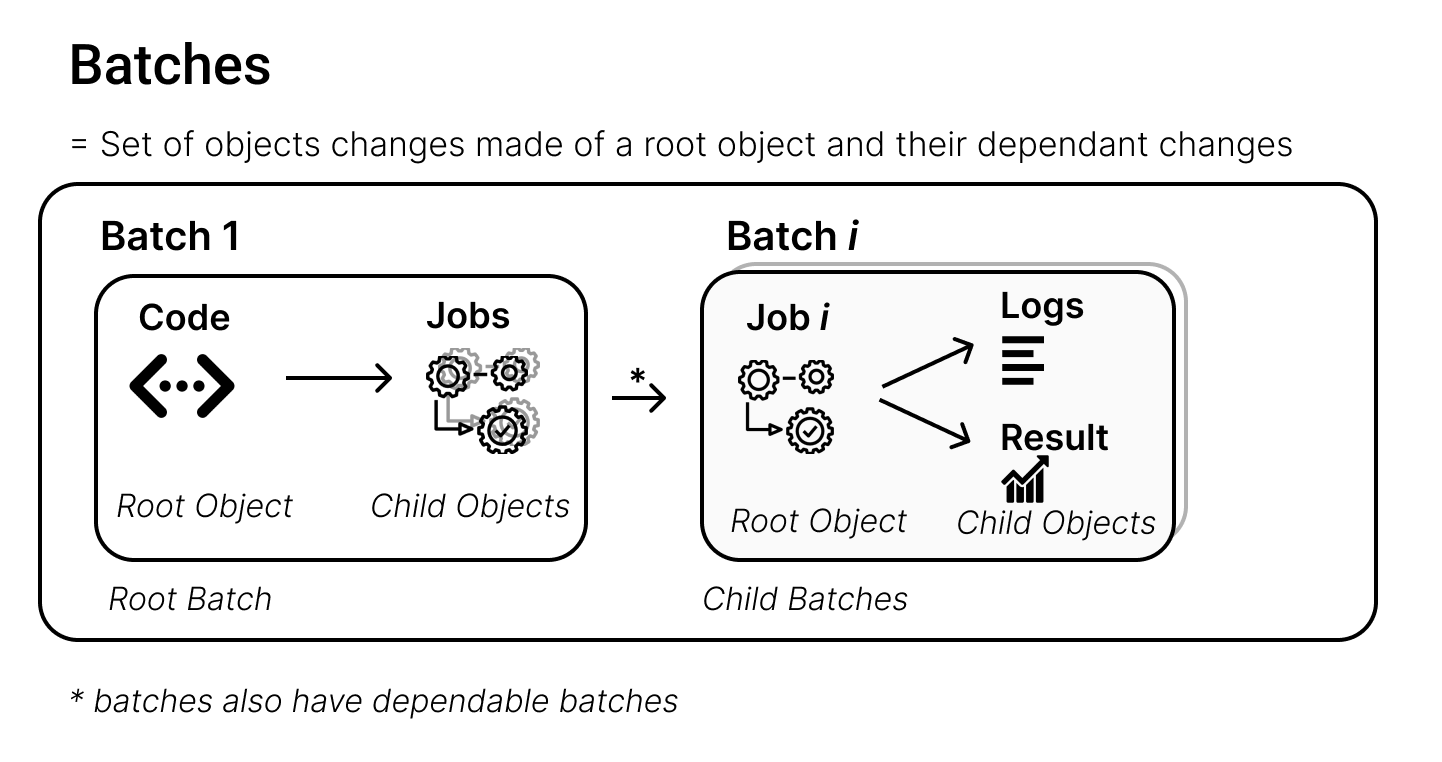
同步是如何工作的?#
同步是通过批次完成的。
一个批次代表对服务器对象的一组更改。PySyft以树形结构组织这些更改,根对象的更改位于底部,依赖对象的更改则从那里分支展开。
例如,用户的Syft Function是一个根对象,而该函数的执行(jobs)依赖于它。类似地,在批处理中,一个job可以是根对象,该job的日志和结果作为子对象。
工作原理
一般来说,一个批次只有一层依赖深度。不过,批次之间也可以相互依赖,形成树状结构。
模拟设置#
Show code cell source
import syft as sy
import pandas as pd
# launch a test setup
server_low = sy.orchestra.launch(
name="low_domain",
port="auto",
dev_mode=False,
reset=True,
server_side_type="low",
create_producer=True,
n_consumers=1
)
server_high = sy.orchestra.launch(
name="high_domain",
port="auto",
dev_mode=False,
reset=True,
create_producer=True,
n_consumers=1
)
# log in (don't forget to change the credentials in a real-life scenario)
client_low = sy.login(
email="[email protected]",
password="changethis",
port=server_low.port
)
client_high = sy.login(
email="[email protected]",
password="changethis",
port=server_high.port
)
main_contributor = sy.Contributor(name="Jeffrey Salazar", role="Uploader", email="[email protected]")
low_side_asset = sy.Asset(
name="asset_name",
data=[1,2,3], # real data
mock=[4,5,6], # mock data
contributors=[main_contributor],
)
high_side_asset = sy.Asset(
name="asset_name",
data=[1,2,3],
mock=[1,2,3],
contributors=[main_contributor],
)
low_side_dataset = sy.Dataset(
name="Dataset name",
description="**Dataset description**",
asset_list=[low_side_asset],
contributors=[main_contributor],
)
high_side_dataset = sy.Dataset(
name="Dataset name",
description="**Dataset description**",
asset_list=[high_side_asset],
contributors=[main_contributor],
)
client_low.upload_dataset(low_side_dataset)
client_high.upload_dataset(high_side_dataset)
client_low.settings.allow_guest_signup(enable=True)
client = sy.login_as_guest(port=server_low.port).register(email="[email protected]", password="123", name="Curious Scientist", password_verify="123", institution="")
client = sy.login(port=server_low.port, email="[email protected]", password="123")
# User proposes a research project
project = sy.Project(
name="Sum of numbers",
description="I want to research the sum of the data points.",
members=[client]
)
project.send()
# User proposes the research code that implements the project
@sy.syft_function_single_use(data=client.datasets[0].assets[0])
def sum_of_numbers(data):
return sum(data)
project.create_code_request(sum_of_numbers, client)
@sy.syft_function_single_use(data=client.datasets[0].assets[0])
def malicious_user_code(data):
return data
# User submits the code requests alongside the project and awaits approval
project.create_code_request(malicious_user_code, client)
低端到高端同步#
将数据从低安全级别同步到高安全级别有助于传输请求(及其代码)以便在高安全级别执行。
要查看代码并决定使用哪个服务器,我们可以使用sync函数:
sy.sync(client_low, client_high)
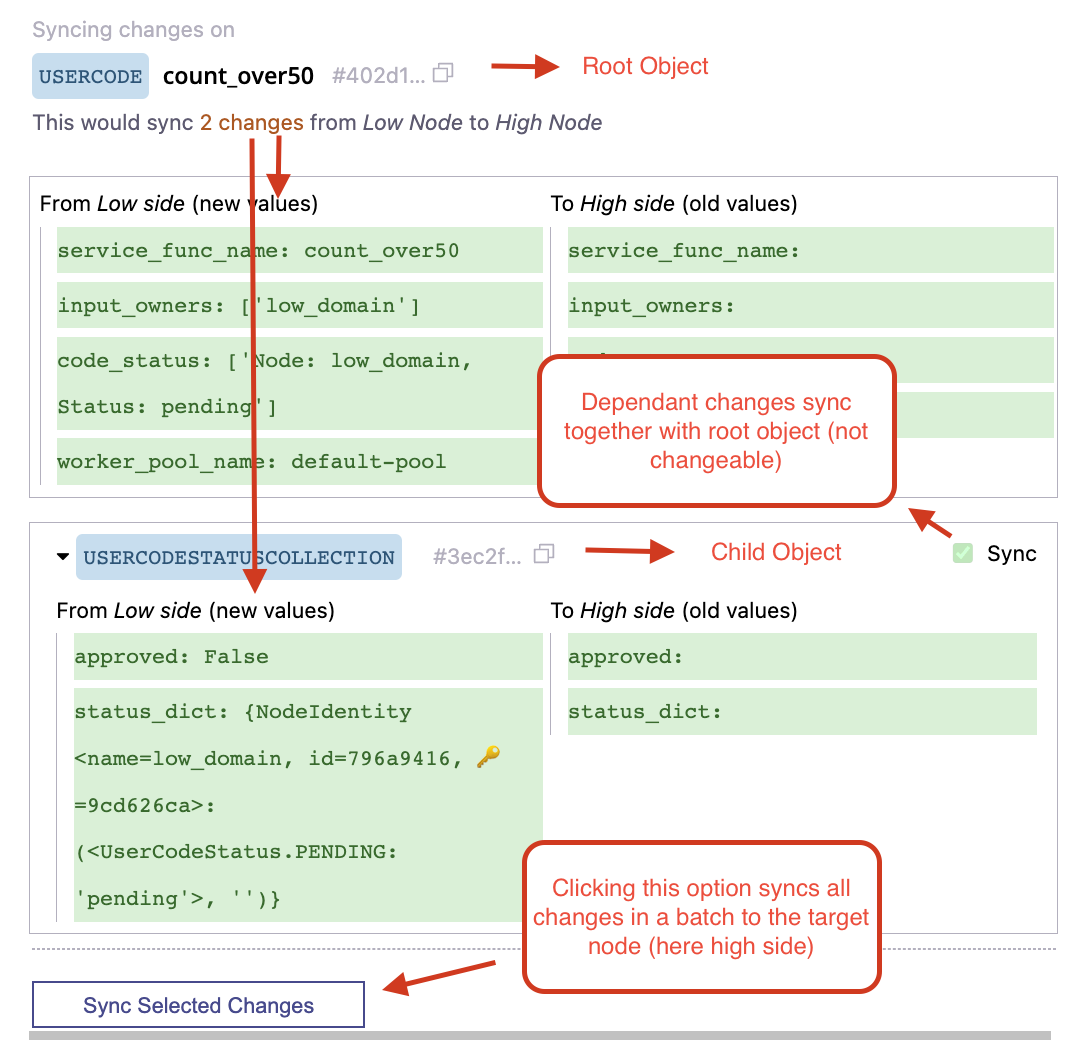
该函数首先从两个节点获取自上次同步以来的最新状态更新,然后将差异以表格形式呈现,如上所示。用户可以通过Next和Previous按钮在未同步的更改之间来回切换,并使用Apply Selected Changes同步选定的更改。
小部件的结构在下面的截图中详细展示。
提醒
重要的是要记住,依赖变更总是与根对象一起批量同步。
筛选与其他小部件选项#
在计算差异时,您可以通过filter_by_email按电子邮件筛选批次,以便更轻松地分类同步操作。
还有更多参数可用于自定义视图:
hide_usercode: 默认情况下用户的代码会作为请求的一部分显示给用户,以便于审核流程;将其设置为False会为了可读性分开显示视图,但它们仍属于同一批次。include_ignored: 您不想同步的批次可以被忽略并从所有差异视图中隐藏;将此设置为True允许用户同步之前被忽略的更改。include_type: 您希望包含在小部件中的类型列表。可以是字符串(request、twinapiendpoint)或类型。
widget = sy.sync(client_low, client_high, filter_by_email="[email protected]", include_types=["request"])
widget
以编程方式批准变更#
这可以通过操作all-batches小部件实现,该部件提供了以下方法:
.click_sync(index): 同步给定索引的批次。这永远不会同步私有信息,需要明确操作才能同步。.click_share_all_private_data(index): 同步给定索引的批次及存储的私有信息,例如计算结果和日志。
警告
使用后者时请谨慎,因为共享结果会通知研究人员他们的请求已获批准且结果已存入。
你也可以直接索引小部件本身,这将启用相同的方法,但以批量级别操作。假设我们只想同步非恶意的那个,可以这样做:
widget[0].click_sync()
忽略批次#
在这个示例场景中,我们希望忽略其他代码请求,因为我们确信永远不希望将其转移到高安全区,因为它包含恶意代码。
信息
如果你忽略一个包含依赖批次的批次,所有相关批次将一起被忽略。
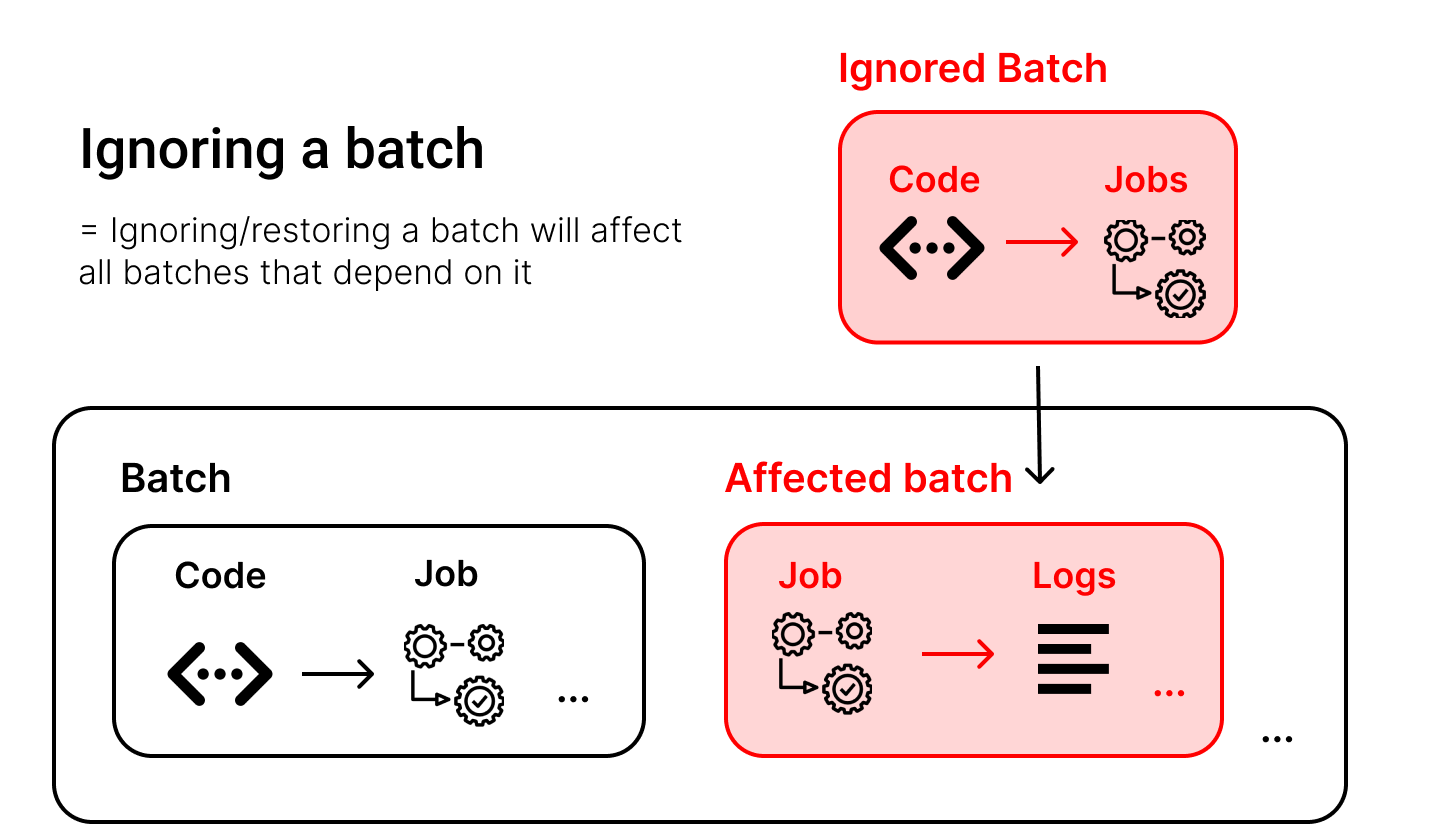
忽略操作仅适用于尚未同步的批次,如下所示:
widget.batches
widget.batches[1].ignore()
widget.batches
高权限端到低权限端同步#
client_high.requests
让我们执行它并在同步代码的同时获取任务结果。
job = client_high.code.sum_of_numbers(data=client_high.datasets[0].assets[0], blocking=False)
job
job.wait().get()
现在,我们希望与低权限端共享上述结果,以便响应数据科学家的请求:
widget = sy.sync(client_high, client_low)
widget
警告
共享隐私数据 该小部件针对可能泄露隐私信息的对象设有特殊复选框,通常涉及对隐私数据的计算结果及其日志。
结果和日志的共享可以独立决定(日志使用Share real data,结果使用Share real data and approve)。但是,如果您决定共享结果(计算产生的ActionObject),这将隐式批准请求并向用户提供结果。这是为了防止数据所有者在不明确向用户共享的情况下将私有数据共享到低安全侧,因为低安全侧更容易受到攻击。
以编程方式批准结果与我们之前看到的类似:
widget.click_share_all_private_data(0) # approving the sharing of private data for the batch at index 0
widget.click_sync(0)