PySyft 从入门到精通#
让我们从基础开始,逐步学习如何使用PySyft。在本教程中,我们将逐步了解PySyft支持的数据科学工作流的主要步骤,并学习PySyft如何在既不获取也不查看数据本身副本的情况下,实现对非公开数据的数据科学分析。
示例:乳腺癌数据研究#
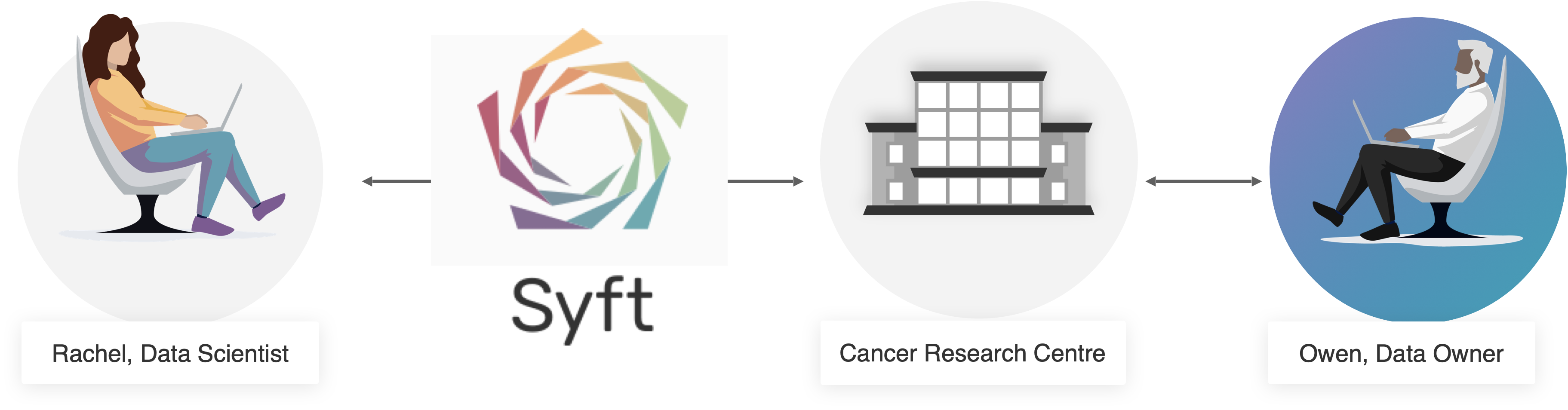
有什么比通过实际用例学习更好的方式呢?
在本教程中,我们将使用PySyft来研究乳腺癌数据。在我们的场景中——如上图简要概括——将有两个主要角色:
 Rachel, 数据科学家:#
Rachel, 数据科学家:#
Rachel是一位数据科学家和研究员,她正在开展一个利用机器学习研究乳腺癌数据的项目。为此,Rachel希望使用《癌症研究中心》数据网站上提供的(非公开)"乳腺癌生物标志物"数据集。
 欧文, 数据所有者:#
欧文, 数据所有者:#
欧文是癌症生物标志物研究小组的实验室数据管理员。欧文负责组织和整理从匿名患者样本中收集的临床数据库。由于法律和监管限制,该数据集无法公开获取,其任何副本也不得离开研究中心的场所。 尽管如此,欧文非常希望允许研究人员在他们的项目中使用"乳腺癌生物标志物"数据集。因此,欧文建立了一个托管该数据集的PySyft数据站点。作为数据所有者,欧文将负责
上传数据
管理凭证和用户资料
审核外部数据科学家提交的任何项目提案。
数据科学工作流程#
本教程选择的用例场景将帮助我们深入了解PySyft支持的数据科学工作流的各个步骤:
步骤1. Owen通过以下方式建立新的癌症研究中心数据站点:(a)上传非公开的"乳腺癌生物标志物"数据集,(b)为Rachel配置登录凭证以访问该数据站点。
步骤2. Rachel连接到癌症研究中心;准备他们的机器学习代码以处理"乳腺癌生物标志物"数据集;并将他们的研究提交到Datasite。
步骤3. 作为Datasite的数据所有者,Owen收到请求并审查Rachel的代码以进行批准。
步骤4. 一旦获得批准,Rachel就能在数据站点上远程执行他们的代码,并使用"乳腺癌数据集"获取他们机器学习研究的结果。
总之,通过使用PySyft:
欧文通过允许他们在隐私保障下使用"乳腺癌生物标志物"数据集进行研究,从而解锁了瑞秋的研究。
Rachel能够通过PySyft远程在"乳腺癌生物标志物"数据集上运行他们的代码,而无需查看数据本身。
在本教程中,我们将学习如何操作!🤓
教程结构#
本教程将分为五个部分。每个部分将聚焦于数据科学工作流程的一个步骤,并重点介绍PySyft的所有相关功能。在每个部分开始时,将强调学习目标以及需要完成的预期成果。
第一部分:数据集与资产
第二部分:客户端与数据站点访问
第三部分: 提出研究方案
第四部分: 代码审核请求
第五部分: 获取结果
准备工作#
我们假设您已经安装了PySyft。您可以通过在shell提示符(通常用$符号表示)中运行以下命令来确认PySyft是否安装以及查看其版本:
$ python -c "import syft; print(syft.__version__)"
如果已安装PySyft,您应该能看到安装的版本号。如果未安装,则会收到Python报错提示ModuleNotFoundError: No module named 'syft'。
本教程针对PySyft 0.9版本编写,该版本支持Python 3.10或更高版本。
如需了解更多关于如何快速安装PySyft的信息,或获取在使用旧版本PySyft时设置环境的建议,请参阅PySyft快速安装指南。