第4部分:代码审查请求#
到目前为止,我们已经了解了Rachel如何通过PySyft提交她的研究项目,该项目目前正等待数据所有者Owen的审核。
你将学习的内容#
在第4部分结束时,你将学习到:
如何访问传入的项目请求;
如何审查用户代码;
如何批准代码请求。
 4.1. 审核传入请求#
4.1. 审核传入请求#
和往常一样,第一步是登录数据站点。这次我们将使用数据所有者Owen的凭证进行登录。
import syft as sy
data_site = sy.orchestra.launch(name="cancer-research-centre")
client = data_site.login(email="[email protected]", password="cancer_research_syft_admin")
然后,我们可以通过client实例访问现有项目:
client.projects
正如预期,Datasite目前包含Rachel为她的"乳腺癌机器学习项目"提出的请求。通过查看描述,Owen可以大致了解即将到来的代码请求内容。
让我们获取请求以便进一步检查。可以通过index访问现有请求:
request = client.requests[0]
request
从request对象开始,我们可以立即获取与之关联的代码引用。这段代码对应数据科学家提交的代码,并附加到原始项目中。
在继续测试代码执行之前,数据所有者可以审查代码,并再次确认项目描述中设定的期望是否得到满足:
request.code
警告
隐私与安全代码审查
代码审查必须经过安全和隐私评估后才能批准。为确保隐私得到尊重,数据所有者必须检查代码是否符合其自身的数据发布规则。为确保安全性,建议密切关注恶意代码请求。以下是一些可能有用的安全代码审查链接:
4.2. 执行代码#
在审查完代码后,Owen的下一步是在提交代码中指定的资产上对模拟和真实数据执行该代码。
在审查Rachel的代码后,我们可以看到该函数需要features和labels两个资产,这些在"乳腺癌生物标志物"数据集中是可用的。
首先,让我们获取特定syft函数的引用:
syft_function = request.code
接下来,让我们获取所需的资产:
bc_dataset = client.datasets["Breast Cancer Biomarker"]
features, labels = bc_dataset.assets
此时,数据所有者可以首先在features.mock和targets.mock上运行syft_function,然后对features.data和labels.data重复相同操作:
result_mock_data = syft_function.run(features_data=features.mock, labels=labels.mock)
result_mock_data
在模拟数据上执行
在模拟数据上的结果与我们在第3部分中最初通过Rachel代码获得的结果完全相同。这是因为Rachel的代码确实正确使用了随机种子,以确保结果可复现。
确认代码在模拟数据上运行无误后,我们可以在真实数据上测试代码,并收集Rachel等待的结果:
result_real_data = syft_function.run(features_data=features.data, labels=labels.data)
result_real_data
4.3. 批准请求#
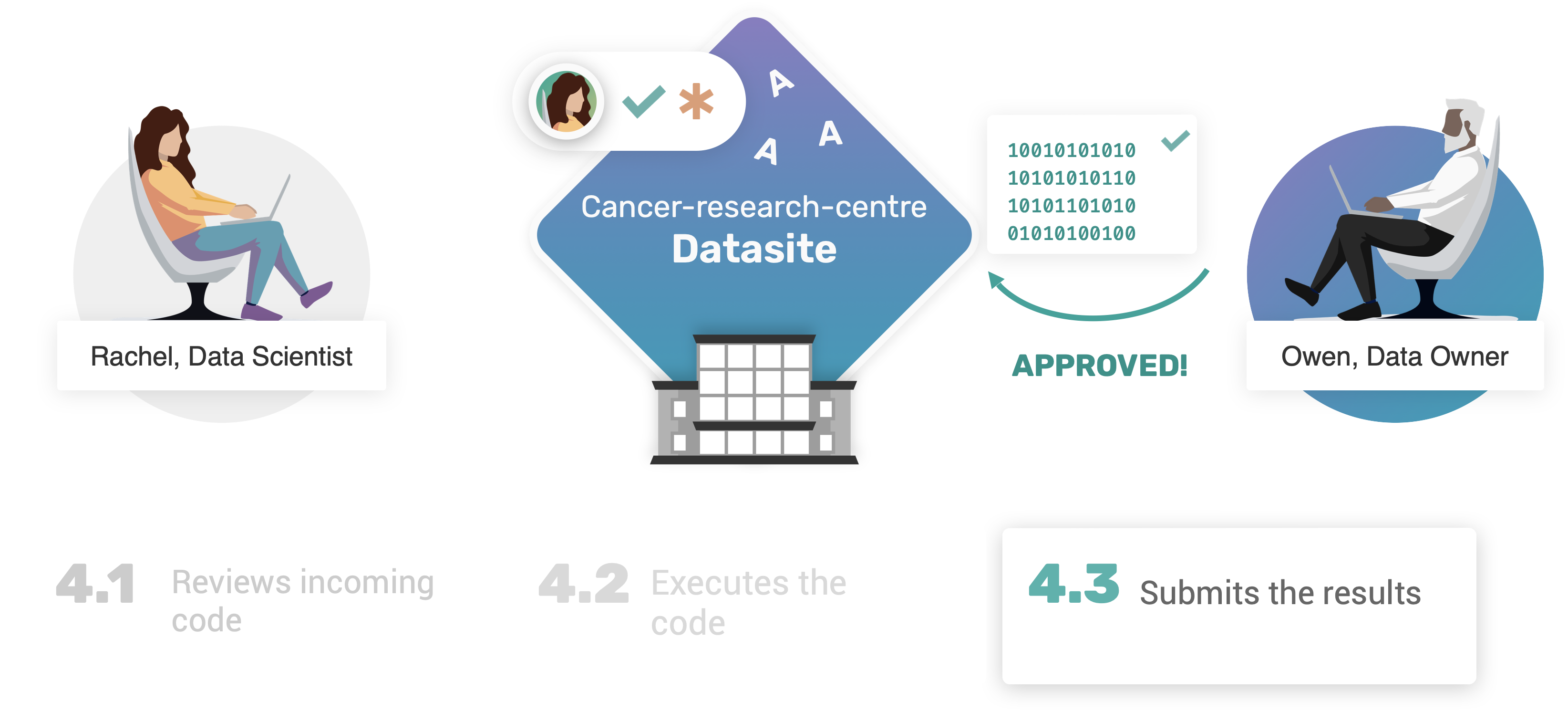
现在我们已经审查、检查并测试了Rachel在选定资产上的函数,同时也在真实的非公开数据上收集了结果,Owen可以继续批准代码请求:
request.approve()
我们可以通过查看当前可用请求的状态来验证该请求是否已获批准:
client.requests
正如预期,Rachel的请求状态现在显示为已批准。
恭喜完成第4部分 🎉#
恭喜您完成教程的第4部分。
在这一部分,我们探讨了PySyft中请求审查和批准的全流程。具体来说,在收到Rachel的新请求后,Owen能够查阅她的研究目的,审查提交的代码,并确认所有预期条件和数据访问标准都已满足。最终,在模拟数据和真实数据上执行代码后,该请求获得了批准。
在最后一部分,第5部分,我们将看到Rachel在收到请求批准后如何能够获取她等待的结果。