第一部分:数据集与资产#
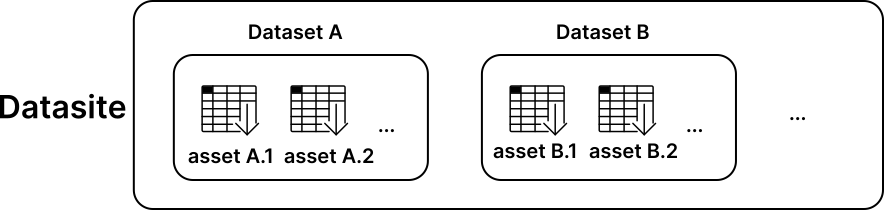
If you are new to PySyft, you need to know one word: Datasite. A Datasite is like a website, but for data instead. Web servers let you download files (e.g. .html, .css) to your browser. Datasites don’t. Instead, a Datasite helps a data scientist to download the answer to a question from data in the server, without downloading the data itself. Data in a Datasite are made available as datasets, each containing multiple assets.
In this first the tutorial, we will learn how create and upload assets and datasets to a Datasite.
你将学习到:#
在第一部分结束时,你将学会:
如何使用PySyft快速启动本地数据站点;
如何创建和配置持有公开及非公开信息的资产;
如何将数据集上传到数据站点。
 1.1. 启动本地开发数据站点#
1.1. 启动本地开发数据站点#
您可以通过三种方式启动Datasite服务器:
使用
syft.orchestra.launch: 适合本地开发;使用单个容器(Docker, Podman): 适合轻量级部署;
使用 Kubernetes: 适用于生产环境;
在本入门教程中,我们将使用syft.orchestra.launch。请查阅文档相关章节以了解更多关于Datasite和deployment选项的信息。
首先导入syft为sy(本教程将始终采用此编码约定, ed.):
import syft as sy
syft.orchestra.launch 函数会启动一个特殊的 本地数据站点服务器,该服务器仅用于开发目的。每个服务器通过其唯一的 name 进行标识,PySyft 在重启时会使用该名称来恢复其内部状态。我们将使用 reset=True 选项来确保服务器实例是首次初始化。
data_site = sy.orchestra.launch(name="cancer-research-centre", reset=True)
服务器启动并运行后,我们可以登录数据站点:
client = data_site.login(email="[email protected]", password="changethis")
管理用户账户
作为初始的第一步,Owen将使用默认管理员凭据登录Datasite。在第二部分:Datasite访问中,我们将学习如何更新和个性化这些凭据,以及如何管理用户账户。
1.2. 下载我们的示例数据集#
要下载我们的示例数据集,我们将使用ucimlrepo Python包,可以通过pip安装:
$ pip install ucimlrepo
使用正确的Python环境
请确保将此包安装在已安装PySyft的同一Python环境中。更多说明请参阅快速安装指南。
完成后,让我们使用以下代码下载数据集:
from ucimlrepo import fetch_ucirepo
# fetch dataset
breast_cancer_wisconsin_diagnostic = fetch_ucirepo(id=17)
# data (as pandas dataframes)
X = breast_cancer_wisconsin_diagnostic.data.features
y = breast_cancer_wisconsin_diagnostic.data.targets
# metadata
metadata = breast_cancer_wisconsin_diagnostic.metadata
# variable information
variables = breast_cancer_wisconsin_diagnostic.variables
我们将使用流行的乳腺癌数据集来模拟Owen的"乳腺癌生物标志物"数据集版本。
X.head(n=5) # n specifies how many rows we want in the preview
该数据集包含596个样本,按30个临床特征(即X)进行组织。
X.shape
每个样本对应一个分类目标,用于标识肿瘤的结果:B代表良性;M代表恶性:
y.sample(n=5, random_state=10)
1.3. 创建资产与数据集#
在本教程的最开始,我介绍PySyft时提到,它能让用户处理数据时既无需下载也看不到数据本身的任何副本。不过到了现在,您可能会产生疑问:
数据科学家如何能够针对他们不具备的数据编写代码?
他们甚至该从哪里开始呢?🤔
PySyft将通过托管两种类型的数据来解决这个问题。首先,它将托管真实数据(稍后会详细介绍);其次,它将托管模拟数据,这是数据科学家可以下载和查看的真实数据的假版本。
创建模拟数据#
因此,在我们把数据集上传到Datasite之前,Owen需要先创建一个数据的模拟版本。我们现在就开始吧!
import numpy as np
# fix seed for reproducibility
SEED = 12345
np.random.seed(SEED)
X_mock = X.apply(lambda s: s + np.mean(s) + np.random.uniform(size=len(s)))
y_mock = y.sample(frac=1, random_state=SEED).reset_index(drop=True)
临床特征X_mock是通过在原始X基础上添加每列的算术平均值,再加上来自正态分布的一些随机噪声而获得的。分类目标y_mock则是通过简单打乱原始值创建的。通过这种方式,数据类型以及类别分布保持不变,同时消除了样本中任何可能的模式。
创建 资产#
现在我们同时拥有真实和模拟数据,可以准备在PySyft中创建相应的资产了,每个资产都通过其在数据站点中的唯一name进行标识。
features_asset = sy.Asset(
name="Breast Cancer Data: Features",
data = X, # real data
mock = X_mock # mock data
)
targets_asset = sy.Asset(
name="Breast Cancer Data: Targets",
data = y, # real data
mock = y_mock # mock data
)
请注意每个资产如何持有对data和mock的引用,这两个属性也是我们可以检查的syft.Asset对象的属性:
features_asset.data.head(n=3)
features_asset.mock.head(n=3)
创建一个数据集#
好的,现在我们有两个资产:features_asset和targets_asset,准备将它们上传到Datasite服务器\(\ldots\)对吧?!其实还不完全正确!这里有个问题:
如果我们就这样不加任何额外信息将这些资产上传到我们的Datasite,外部数据科学家如何才能找到并知道如何使用这些数据?
因此,PySyft要求每个资产都作为syft.Dataset对象的一部分存储。PySyft中的每个数据集都通过其唯一名称进行标识,并包含额外的元数据(例如description、citation、contributors),这些元数据进一步描述了其资产中包含的核心数据。
现在让我们收集元数据,然后使用它创建我们的Dataset对象:
# Metadata
description = f'{metadata["abstract"]}\n{metadata["additional_info"]["summary"]}'
paper = metadata["intro_paper"]
citation = f'{paper["authors"]} - {paper["title"]}, {paper["year"]}'
summary = "The Breast Cancer Wisconsin dataset can be used to predict whether the cancer is benign or malignant."
# Dataset creation
breast_cancer_dataset = sy.Dataset(
name="Breast Cancer Biomarker",
description=description,
summary=summary,
citation=citation,
url=metadata["dataset_doi"],
)
最后,我们可以将这两个资产添加到数据集中:
breast_cancer_dataset.add_asset(features_asset)
breast_cancer_dataset.add_asset(targets_asset)
最后让我们看一下新创建的breast_cancer_dataset对象,使用PySyft提供的默认rich表示方式:
breast_cancer_dataset
1.4. 将数据集上传至数据站点#
要将新数据集上传到数据站点,我们可以从可用的client中调用upload_dataset函数:
client.upload_dataset(dataset=breast_cancer_dataset)
干得漂亮!👏
数据集终于到达数据站点🎉。
为了验证这一点,我们可以探索通过client对象可访问的所有datasets:
client.datasets
1.5. 关闭数据站点#
完成数据集上传后,我们可以使用land函数关闭正在运行的服务器
data_site.land()
恭喜完成第一部分 🎉#
恭喜完成教程的第一部分!👏
在这一部分,我们学习了如何为"癌症研究中心"设置一个数据站点。为了简化操作且不失一般性,我们使用了PySyft内置的本地开发服务器来快速在本地机器上托管数据站点服务器。随后我们创建并上传了一个新的syft.Dataset到数据站点,其中包含了"乳腺癌生物标志物"数据的特征和目标资源。
在第二部分中,我们将学习如何管理用户凭证,并设置对数据站点的访问权限。