![]() 要在GitHub上执行或查看/下载此笔记本
要在GitHub上执行或查看/下载此笔记本
使用Conformers进行流式语音识别
自动语音识别(ASR)模型通常仅设计用于转录整个大块音频,不适合用于需要低延迟、长格式转录的用例,如直播转录。
本教程介绍了动态分块训练方法以及您可以应用的架构更改,以使Conformer模型可流式传输。它介绍了SpeechBrain可以为您提供的训练和推理工具。 如果您对训练和理解自己的流式模型感兴趣,或者甚至想要探索改进的流式架构,这可能是一个很好的起点。
本教程非常深入地介绍了实现过程。根据你的目标,可能可以略读。
这里描述的模型和训练程序并不是最先进的,但它是一个相当不错且现代的端到端方法。它已成功应用于以下配方(非详尽列表):
CommonVoice/ASR/transducer(法语, 意大利语)
推荐的先决条件
安装 SpeechBrain
%%capture
# Installing SpeechBrain via pip
BRANCH = 'develop'
!python -m pip install git+https://github.com/speechbrain/speechbrain.git@$BRANCH
%%capture
%pip install matplotlib
流模型需要实现什么
我们需要一种细粒度的方式来限制和记住上下文,以便模型只关注最近的上下文,而不是未来的帧。这种策略必须在训练和推理之间保持一致。
传统模型可能能够奢侈地在训练和推理中重复使用相同的前向代码路径。流式处理时的训练和推理具有相反的性能特征,这导致在某些层中出现特殊情况。
对于推理,我们通常需要逐块处理输出的数据,这通常意味着在不同层缓存一些过去的隐藏状态。
对于训练,我们更倾向于一次性传入大批量的完整话语,以最大化GPU占用率并降低Python和CUDA内核启动的开销。因此,我们更倾向于通过掩码来强制执行这些限制。
教程摘要
本教程尝试将理论和实践分开在不同的部分。以下是每个部分的摘要:
介绍对Conformer模型的架构更改。我们将讨论:
我们如何通过分块注意力掩码解决自注意力机制的未来依赖问题。
我们如何通过动态块卷积解决卷积模块的未来依赖问题。
为什么我们可以避免在训练时更改特征提取器和位置嵌入。
解释用于训练的Dynamic Chunk Training策略。我们将讨论:
如何训练模型以支持在运行时选择各种块大小和左上下文大小。
更改块大小和左上下文大小的后果。
不同损失函数对流模型训练的影响。
列出在SpeechBrain中训练流式Conformer所需的实际更改。
解释如何调试神经层以确保正确的流行为。
介绍流式推理中涉及的所有部分。我们将:
介绍包装器,将非流式特征提取器适配为流式特征提取器。
解释流式上下文对象架构和流式转发方法。
列出需要对模型进行的其他杂项更改。
介绍SpeechBrain中的推理工具的实际应用。我们将:
演示如何使一个经过训练的流式模型准备好进行流式推理。
提供
StreamingASR推理接口的完整示例,用于流或文件处理。
Conformer的架构变更
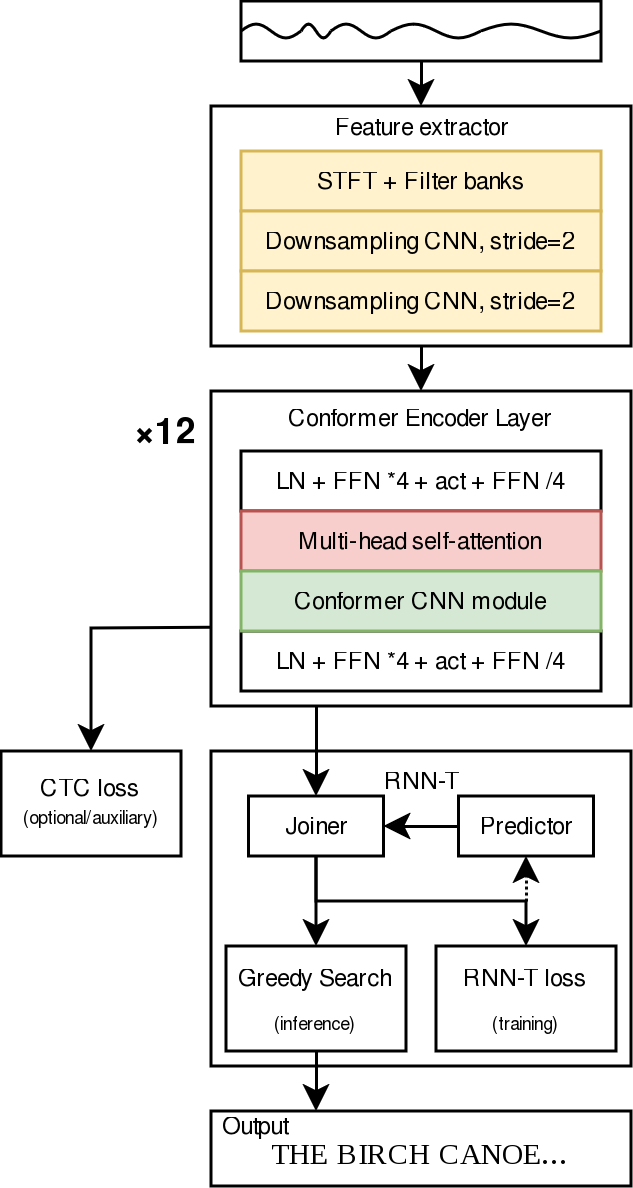
以上是我们模型中使用的普通Conformer架构的(非常)简化图,从上到下阅读。
彩色砖块是我们在流式处理时需要小心的部分,因为它们跨时间步传播信息。
分块注意力
什么是因果注意力?
如果你熟悉Transformer架构,你可能对因果注意力机制有所了解。简而言之,因果注意力机制确保在时间步\(t\)的输出帧不能关注来自“未来”时间步(\(t+1\)、\(t+2\)等)的输入。
这直接意味着,如果你想预测模型在时间步\(t\)的输出,你只需要“当前”和“过去”的输入(\(t\),\(t-1\),\(t-2\)等)。这对我们来说很重要,因为我们不知道未来的帧!
因果注意力机制应用起来非常简单(直观上),实际上也符合流式自动语音识别的要求…但我们在这里不会使用它。
什么是分块注意力,为什么我们更喜欢它?
因果注意力机制实现起来很简单,但对于流式自动语音识别(ASR),发现它会不成比例地增加词错误率。 因此,在流式注意力模型中,通常选择分块注意力机制来代替。
从概念上讲,分块注意力引入了块的概念,这些块将给定数量的帧(chunk_size)分组。例如,如果你的块大小为4,那么你会这样查看你的输入:

块内的帧可以相互关注。与因果关注相比,这保留了更多的关注表达能力。
块也可以关注过去的块,但我们限制了过去的时间范围,以减少推理时的计算和内存成本(left_context_chunks)。
在训练时,我们使用注意力掩码来强制执行这一点。注意力掩码回答了这个问题:第j个输出帧是否可以关注第i个输入帧?
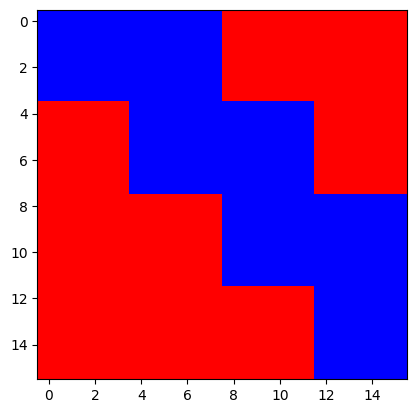
因此,它被定义为一个形状为(t, t)的布尔张量。下面是一个示例(尽管实际的掩码是这个的转置):

事实上,我们可以很容易地重现这个确切的掩码。请注意,我们正在转置掩码以便显示,这里,True(红色)表示掩码,而False(蓝色)表示不掩码:
from speechbrain.lobes.models.transformer.TransformerASR import make_transformer_src_mask
from speechbrain.utils.dynamic_chunk_training import DynChunkTrainConfig
from matplotlib import pyplot as plt
import torch
# dummy batch size, 16 sequence length, 128 sized embedding
chunk_streaming_mask = make_transformer_src_mask(torch.empty(1, 16, 128), dynchunktrain_config=DynChunkTrainConfig(4, 1))
plt.imshow(chunk_streaming_mask.T, cmap="bwr")
plt.show()
推理过程中的分块注意力
在设计流式模型时,我们需要非常小心地处理输出帧和输入帧之间的依赖关系如何在各层之间传播。
例如,回想一下因果注意力,你可能会想,如果我们允许时间步\(t\)的输出帧关注时间步\(t+1\)的输入帧,即每一层都给它一些“右”/未来的上下文,是否可以提高一些准确性。
是的,我们可以,这确实有些帮助,但考虑一下堆叠层时的影响!例如,考虑两层注意力,其中\(a\)是输入,\(b\)是第一层的输出,\(c\)是第二层的输出:\(c_t\)将关注\(b_{t+1}\)(以及其他),而\(b_{t+1}\)本身将关注\(a_{t+2}\)。这在实际中会更糟,因为我们可能有12或17层。
这很麻烦,并且可能会对延迟(我们需要缓冲一堆“未来”帧)和内存/计算成本产生负面影响。
另一方面,分块注意力机制与此配合得非常好。让我们先忽略左侧上下文。 以下示例聚焦于输入的第四个分块,以及哪些帧实际上依赖于/关注于哪些帧:
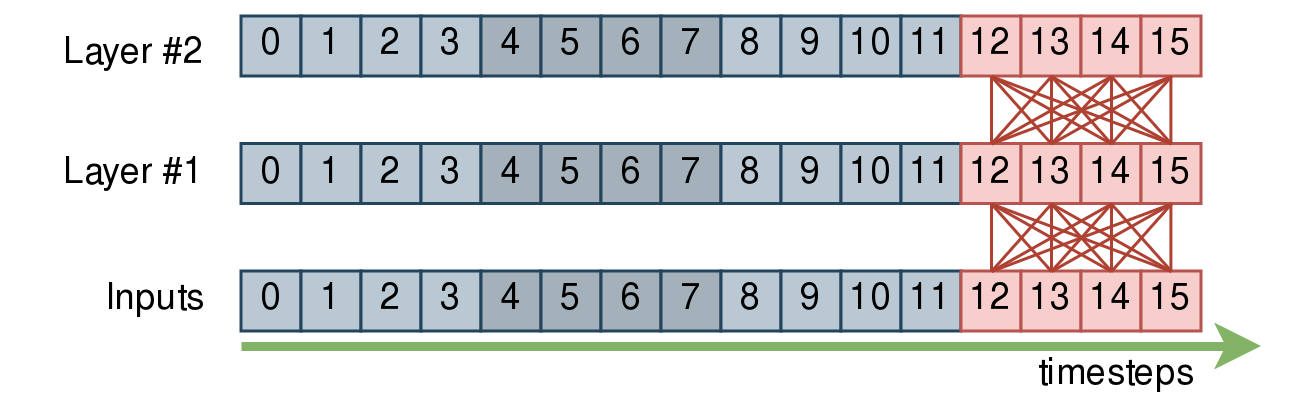
忽略左侧上下文,一个块内的帧可以相互关注。如果你堆叠注意力层,块的边界在各层之间保持不变。
现在,让我们添加上下文。在下面的示例中,我们将假设上下文大小为1个块。为了清晰起见,我们省略了12,13,14的连接,但它们与15关注的是相同的帧。
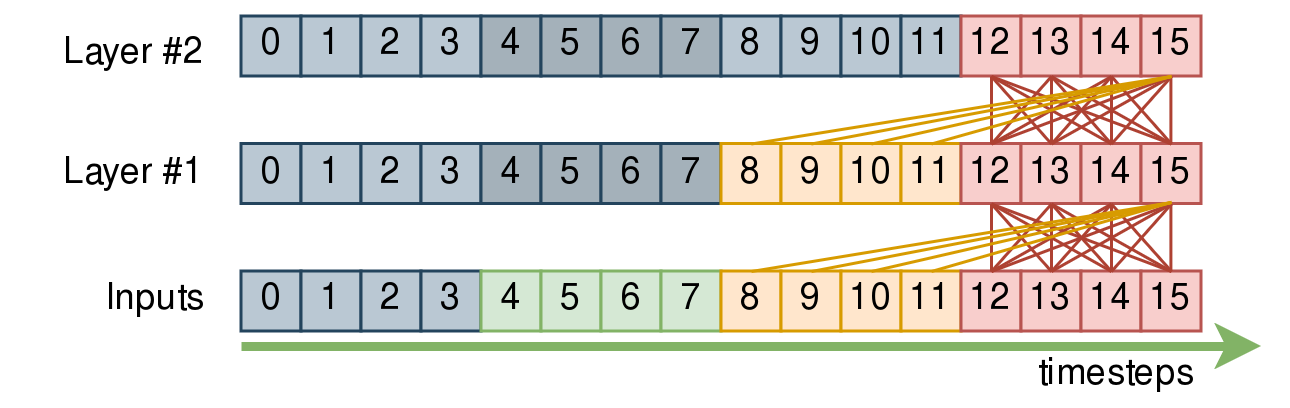
等等,这是否意味着
Layer #2的输出12,13,14,15需要我们记住输入4,5,6,7的嵌入?
不!在Layer #2的12,13,14,15块确实依赖于Layer #1的8,9,10,11,而Layer #1本身又依赖于Inputs的4,5,6,7。
然而,Layer #1的8,9,10,11的隐藏状态完全不受我们的红色块影响!因此,在推断时,我们可以缓存任意数量的左侧上下文块,而我们需要缓存/重新计算的内容量不会随着层数的增加而爆炸。
speechbrain.lobes.models.transformer.TransformerASR.make_transformer_src_mask 是生成这些掩码的函数。
在推理时这是如何工作的?
左上下文被定义,使得给定的块\(i\)可以关注left_context_chunks个块,即块\(i\)内的所有输出帧可以关注过去left_context_chunks个块内的所有帧。
最终,这种设计允许我们在推理时为给定输入块定义处理注意力的数学公式,如下所示:
attention_module(concat(cached_left_chunks, input_chunk))
忽略KV缓存,这里,cached_left_chunks最终是,对于每一层,一个大小为(batch_size, left_context_chunks * chunk_size, emb_dim)的张量。这是相当合理的,并且这是我们在推理时为了注意力部分必须保存的唯一内容。
动态块卷积
普通卷积

致谢:Xilai Li 等人, 2023 (动态块卷积论文)
卷积示例 \(k=5\),意味着“半个窗口”,\(\frac{k-1}{2}\),是 \(2\)
普通的卷积操作在窗口上进行,对于时间步\(t\)的卷积输出,窗口跨越从\(t-\frac{k-1}{2}\)到\(t+\frac{k-1}{2}\)的索引,其中\(k\)是卷积核的大小。因此,时间步\(t\)的输出将依赖于未来的帧,这是我们希望避免的。
我们可以假装通过正常训练来忽略这个问题,并在推理时,将我们不知道的帧右填充为零(见图)。然而,这将导致训练和推理之间的严重不匹配,并会显著损害准确性。
因果卷积

这里有一个直接的解决方案:因果卷积。它们只是将输出\(t\)的窗口移动,以覆盖从\(t-(k-1)\)到\(t\)的索引。
其数学原理非常简单:你只需要在输入的左侧填充\(\frac{k-1}{2}\)帧,将其传递给卷积,然后在左侧截断这些\(\frac{k-1}{2}\)输出帧。
动态块卷积

不幸的是,因果卷积会导致准确性下降。为了解决这个问题,Xilai Li 等人,2023 提出了用于流式分块 ASR 的动态分块卷积的概念。
通过这种方式,我们重用了用于分块注意力的相同分块边界。
在上图中,考虑帧 \(T_{15}\):它看起来很像普通的卷积,除了任何属于未来块的输入帧都被屏蔽了。这解决了我们依赖未来帧的问题。
请注意示例块的最左侧输出\(T_0\)如何依赖于\(\frac{k-1}{2}\)过去帧:在推理时,我们将在每一层缓存这一点。不过,这是相当轻量级的。
在训练时,这个实现实际上远非显而易见,因为PyTorch卷积运算符不能仅仅接受类似于我们使用的自注意力掩码的掩码。如果你感到冒险,你可以阅读speechbrain.lobes.models.transformer.Conformer.ConvolutionModule的源代码,这是一堆(注释和图示的)张量重塑魔法。
我们没有改变的内容
架构的某些部分并不真正重要,也不需要为流式处理提供任何特殊照顾,因为它们不会在帧之间传播信息(即它们只是逐点的)。
另一方面,有些部分需要解释为什么它们重要或不重要。
特征提取
在SpeechBrain中实现的Conformer特征提取器不是因果的。这通常会对流式处理造成影响,但我们在训练中保持不变。这是为什么呢?
事实证明,特征提取实际上并不需要太多的右侧上下文(即查看许多未来的帧)。我们可以为此引入一些右侧上下文的概念,因为它无论如何都代表了毫秒级的语音。这在一定程度上简化了整个复杂过程,并为探索特征提取器提供了更多的灵活性。
SpeechBrain 提供了一个包装器,speechbrain.lobes.features.StreamingFeatureWrapper,它几乎完全为您抽象了这一点,通过自动填充和缓存上下文。它仍然需要被告知特征提取器的特性,我们将在后面进一步展开。
归一化是特征提取器中未编辑的另一部分。这实际上在训练和测试之间造成了差异,但我们发现这种差异很小,即使是在全音频归一化和每块归一化之间也是如此。因此,它基本上被忽略了,尽管你可以更加关注它。
位置嵌入
我们不会在这里详细解释位置嵌入,尽管它们在ASR模型精度中起着重要作用。重要的是要知道它们通过位置信息丰富了注意力机制。否则,模型将缺乏关于标记之间相对位置的信息。
幸运的是,我们使用的是在SpeechBrain中定义的模型,该模型使用相对位置的正弦编码(speechbrain.nnet.attention.RelPosEncXL)。我们将在下面强调为什么这很有用。
在自注意力机制中,任何查询都可以关注任何键(只要该查询/键对没有被屏蔽,就像我们在分块注意力中所需要的那样)。
如果没有位置嵌入,注意力机制将忽略query和key在句子中的实际位置。
使用一个相当简单的位置嵌入,我们会关心key相对于句子开头的位置。这种方法有效,但在流式自动语音识别(ASR)中存在一些问题。最明显的是,距离会变得相当长。
通过我们的相对位置嵌入,我们查看查询和键之间的位置差异。
由于我们有限制的分块注意力机制,限制了query可以关注过去和未来的范围,我们编码的距离永远不会超过我们关注的帧窗口。
换句话说,如果我们关注16个标记的块,并且有48个标记的左侧上下文,我们最多会表示从最右边的标记到最左边的标记的距离,即\(63\)。
\(63\)的距离会有其固定的位置编码向量,这在自注意力机制中用于计算特定query/key对的分数时会考虑进去。
此外,无论我们是\(0\)秒还是\(30\)分钟进入流,这些距离都保持不变,因为它们是相对位置。
以下示例展示了在16个时间步长和嵌入大小为64的序列上的相对位置编码:
from speechbrain.nnet.attention import RelPosEncXL
from matplotlib import pyplot as plt
test_pos_encoder = RelPosEncXL(64)
test_pos = test_pos_encoder.make_pe(seq_len=16)
print(f"(batch, seq_len*2-1, emb_size): {tuple(test_pos.shape)}")
plt.imshow(test_pos.squeeze(0).T, cmap="bwr")
plt.xlabel("seq_len*2-1")
plt.ylabel("emb_size")
plt.show()
(batch, seq_len*2-1, emb_size): (1, 31, 64)
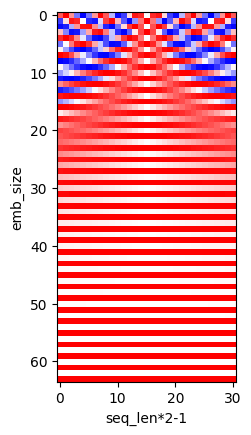
在上图中,中心列对应于位置差为零的位置嵌入向量,即被关注的键与查询是相同的输入。
从中心到水平距离表示自注意力机制中给定查询和键对之间的距离。
中心右侧一列将表示距离为\(1\),依此类推。
这不取决于键或查询与序列开始的距离。
在推理时,我们只需要使上面的seq_len与注意力窗口的大小(左上下文 + 活动块)一样大。
请注意,这个嵌入通过首先传递到一个可学习的线性层进一步丰富。
训练策略和动态块训练
块大小和左上下文大小影响哪些指标?
通常,在流式处理时,我们会尝试以匹配块大小的方式分割输入流,并在块到达时逐个处理它们。
较小的块会降低准确性,但会带来更低的延迟。
这是一个权衡,取决于最终的使用场景,值得在代表最终应用程序的测试数据集上对不同块大小进行基准测试。
查看来自speechbrain/asr-streaming-conformer-librispeech的数据,对于左侧块计数为4,以及这个特定模型和数据集,我们得到如下曲线(注意比例):
from matplotlib import pyplot as plt
import matplotlib.ticker as mtick
xs = [1280, 960, 640, 480, 320]
ys = [3.10, 3.11, 3.31, 3.39, 3.62]
plt.scatter(xs, ys)
plt.plot(xs, ys)
plt.ylim(2, 4)
plt.title("asr-streaming-conformer-librispeech WER vs chunk size")
plt.xlabel("chunk size (ms)")
plt.ylabel("WER (%)")
plt.gca().yaxis.set_major_formatter(mtick.PercentFormatter())
plt.show()
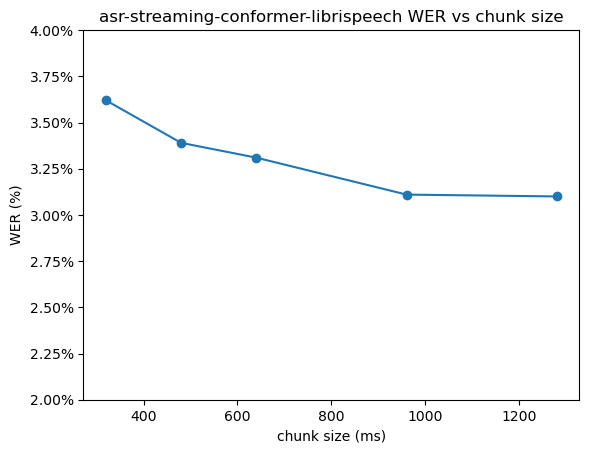
左侧上下文大小纯粹是准确性和计算/内存成本之间的权衡。同样,根据所需的权衡,值得使用不同大小来评估模型。
如何选择块大小?
有趣的是,它不必是静态的!以下策略效果出奇地好:
对于40%的批次(随机选择),我们正常训练,不使用任何分块策略。
对于剩下的60%,我们执行以下操作:
对于每个批次,我们在一些合理的值之间随机抽取一个块大小(例如,在8到32个普通conformer帧之间进行均匀采样)
对于这些数据块中的75%,我们同样限制了左上下文(例如2-32个数据块)。对于剩下的25%,我们没有限制。
该策略在SpeechBrain中通过speechbrain.utils.dynamic_chunk_training.DynChunkTrainConfigRandomSampler进行了抽象。
这一结果非常有趣:训练好的模型仍然可以以传统的非流式方式进行推断,但它也可以以流式方式进行推断,并且在运行时选择块大小!令人惊讶的是,我们发现与前一种情况相比,未修改模型的错误率下降有时很小,但对于其他超参数和数据集,影响可能会更显著。
让我们写一个例子:
from speechbrain.core import Stage
from speechbrain.utils.dynamic_chunk_training import DynChunkTrainConfig
from speechbrain.utils.dynamic_chunk_training import DynChunkTrainConfigRandomSampler
sampler = DynChunkTrainConfigRandomSampler(
chunkwise_prob=0.6,
chunk_size_min=8,
chunk_size_max=32,
limited_left_context_prob=0.8,
left_context_chunks_min=2,
left_context_chunks_max=16,
test_config=DynChunkTrainConfig(32, 16),
valid_config=None
)
for i in range(10):
print(f"Draw #{i:<2} -> {sampler(Stage.TRAIN)}")
print()
print(f"Test config -> {sampler(Stage.TEST)}")
print(f"Valid config -> {sampler(Stage.VALID)}")
Draw #0 -> None
Draw #1 -> DynChunkTrainConfig(chunk_size=5, left_context_size=None)
Draw #2 -> DynChunkTrainConfig(chunk_size=23, left_context_size=None)
Draw #3 -> None
Draw #4 -> DynChunkTrainConfig(chunk_size=12, left_context_size=14)
Draw #5 -> DynChunkTrainConfig(chunk_size=19, left_context_size=14)
Draw #6 -> DynChunkTrainConfig(chunk_size=24, left_context_size=None)
Draw #7 -> DynChunkTrainConfig(chunk_size=16, left_context_size=None)
Draw #8 -> DynChunkTrainConfig(chunk_size=8, left_context_size=6)
Draw #9 -> DynChunkTrainConfig(chunk_size=12, left_context_size=None)
Test config -> DynChunkTrainConfig(chunk_size=32, left_context_size=16)
Valid config -> None
损失函数
目前训练流式Conformer模型的最简单方法是使用RNN-T损失(并可选择使用CTC作为辅助损失以改善训练)。如需复习,请参阅Speech Recognition From Scratch及其相关资源。
也有可能将编码器-解码器交叉熵作为辅助损失添加(即使使用RNN-T路径进行推理,也可以提高模型准确性),或用于流式处理,但这尚未经过测试,目前不受支持。
要实现这一点,您可能需要探索文献和竞争模型所采用的方法。
培训:使用SpeechBrain将所有内容整合在一起
这是很多理论,但我们如何利用SpeechBrain实现的内容呢?
以下描述了应该使用什么代码,以及典型的流式Conformer-Transducer配方中的流式特定代码。
你最好调整一个已知良好的配方(例如LibriSpeech/ASR/transducer。
如果你正在尝试适应一个不同的模型,这可能对你有帮助,但你可能需要进行更多的研究和工作。
通过传递动态块训练配置进行自动掩码
speechbrain.utils.dynamic_chunk_training.DynChunkTrainConfig 类已添加,其目的是描述一个批次的流配置。
为了实现完整的动态块训练策略,您的训练脚本可以从DynChunkTrainConfigRandomSampler中为每个批次随机采样一个配置。(如果您愿意,您可以自由实现自己的策略。)
增强了各种功能,例如TransformerASR.encode,以接受dynchunktrain_config作为可选参数。
此参数允许您为此特定批次传递动态块训练配置。当None/未传递时,不会进行任何更改。
根据需要,参数被传递到每一层。使用标准的Conformer配置,传递此对象是使编码器模块具备流式处理能力的全部需求。这使得代码的导航变得相当容易。
对.yaml的更改
以下代码片段是相关的:
streaming: True # controls all Dynamic Chunk Training & chunk size & left context mechanisms
如前所述,配置采样器对于描述超参数中的训练策略非常有用:
# Configuration for Dynamic Chunk Training.
# In this model, a chunk is roughly equivalent to 40ms of audio.
dynchunktrain_config_sampler: !new:speechbrain.utils.dynamic_chunk_training.DynChunkTrainConfigRandomSampler # yamllint disable-line rule:line-length
chunkwise_prob: 0.6 # Probability during a batch to limit attention and sample a random chunk size in the following range
chunk_size_min: 8 # Minimum chunk size (if in a DynChunkTrain batch)
chunk_size_max: 32 # Maximum chunk size (if in a DynChunkTrain batch)
limited_left_context_prob: 0.75 # If in a DynChunkTrain batch, the probability during a batch to restrict left context to a random number of chunks
left_context_chunks_min: 2 # Minimum left context size (in # of chunks)
left_context_chunks_max: 32 # Maximum left context size (in # of chunks)
# If you specify a valid/test config, you can optionally have evaluation be
# done with a specific DynChunkTrain configuration.
# valid_config: !new:speechbrain.utils.dynamic_chunk_training.DynChunkTrainConfig
# chunk_size: 24
# left_context_size: 16
# test_config: ...
确保您使用的是支持的架构(例如Conformer,其中TransformerASR的causal参数设置为False)。
目前,在流式上下文中仅支持贪婪搜索。你可能希望确保你的test集使用贪婪搜索进行评估。
此外,您可以为采样器指定一个valid_config或test_config(参见注释),以便在评估模型时模拟流式处理。
对train.py的更改
在compute_forward中,你应该随机采样一个配置(以便每个批次都不同):
if self.hparams.streaming:
dynchunktrain_config = self.hparams.dynchunktrain_config_sampler(stage)
else:
dynchunktrain_config = None
然后,假设编码器可以作为enc超参数使用,编辑其调用以转发dynchunktrain_config:
x = self.modules.enc(
src,
#...
dynchunktrain_config=dynchunktrain_config,
)
对于训练来说,应该就是这样了!
调试流式架构
speechbrain.utils.streaming 提供了一些有用的功能,包括我们将演示的调试功能。
检测神经网络层中的未来依赖关系
正如你可能已经注意到的,将流式支持改造到现有架构中并非易事,很容易忽略对未来的意外依赖。
speechbrain.utils.streaming.infer_dependency_matrix 可以为你计算输出帧和输入帧之间的依赖矩阵。
它通过重复调用你的模块并确定哪些输出受到哪些输入随机化的影响来实现这一点。
它还可以检测你的模型是否不够确定性,即两次连续调用导致不同的数据。
输出可以使用speechbrain.utils.streaming.plot_dependency_matrix进行可视化。
红色单元格表示给定输出的值可能受到给定输入的影响。因此,如果你看过之前的图表,这些图可能看起来非常熟悉。
请注意,由于实现的原因,在较大的图表和一些模型上,你可能会看到一些随机的空洞。这些可能是假阴性。不要依赖infer_dependency_matrix来提供完美的输出!
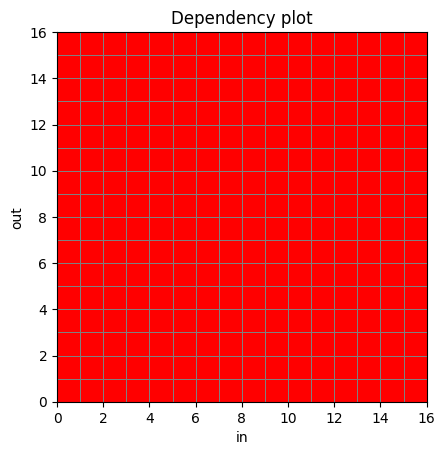
以下是使用实际Conformer层的依赖图示例:
from speechbrain.lobes.models.transformer.TransformerASR import TransformerASR
from speechbrain.utils.streaming import infer_dependency_matrix, plot_dependency_matrix
from matplotlib import pyplot as plt
noncausal_model = TransformerASR(
tgt_vocab=64, input_size=64, d_model=64, nhead=1, d_ffn=64,
encoder_module="conformer", normalize_before=True,
attention_type="RelPosMHAXL",
num_encoder_layers=4, num_decoder_layers=0,
causal=False
)
noncausal_model.eval()
noncausal_deps = infer_dependency_matrix(noncausal_model.encode, seq_shape=[1, 16, 64])
plot_dependency_matrix(noncausal_deps)
plt.show()
causal_model = TransformerASR(
tgt_vocab=64, input_size=64, d_model=64, nhead=1, d_ffn=64,
encoder_module="conformer", normalize_before=True,
attention_type="RelPosMHAXL",
num_encoder_layers=4, num_decoder_layers=0,
causal=True
)
causal_model.eval()
causal_deps = infer_dependency_matrix(causal_model.encode, seq_shape=[1, 16, 64])
plot_dependency_matrix(causal_deps)
plt.show()
from speechbrain.utils.dynamic_chunk_training import DynChunkTrainConfig
chunked_model = TransformerASR(
tgt_vocab=64, input_size=64, d_model=64, nhead=1, d_ffn=64,
encoder_module="conformer", normalize_before=True,
attention_type="RelPosMHAXL",
num_encoder_layers=4, num_decoder_layers=0,
causal=False
)
chunked_model.eval()
chunked_conf = DynChunkTrainConfig(chunk_size=4, left_context_size=1)
chunked_deps = infer_dependency_matrix(lambda x: chunked_model.encode(x, dynchunktrain_config = chunked_conf), seq_shape=[1, 16, 64])
plot_dependency_matrix(chunked_deps)
plt.show()
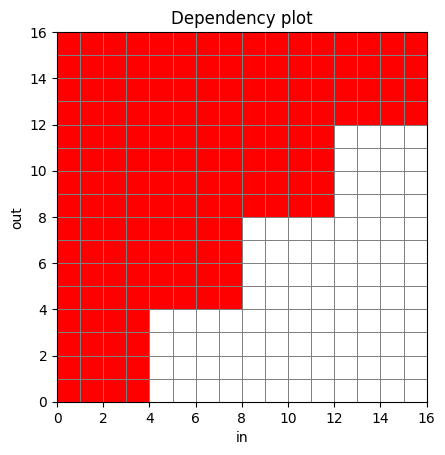
提醒一下,上述情况是正常的,例如在时间步\(t=15\)的输出依赖于\(t=0\)。
在任何层中,\(t=15\)都不会直接关注\(t=0\)。请阅读分块注意力部分以获取更多详细信息。
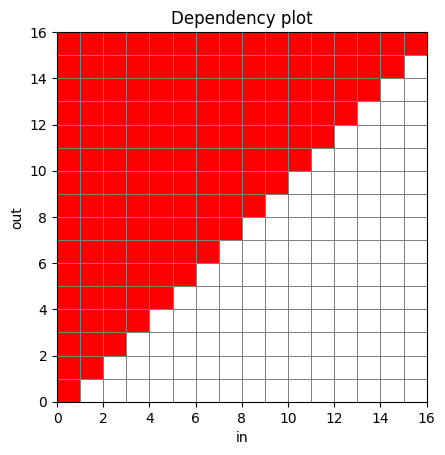
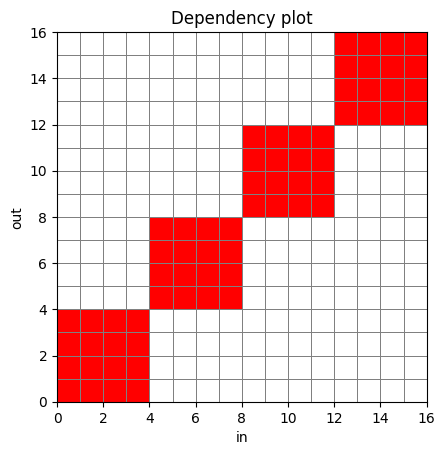
如果我们想看到没有任何左上下文的纯分块,我们可以减少卷积模块的核大小,完全禁用左上下文,并观察以下内容:
from speechbrain.utils.dynamic_chunk_training import DynChunkTrainConfig
chunked_model_nopast = TransformerASR(
tgt_vocab=64, input_size=64, d_model=64, nhead=1, d_ffn=64,
encoder_module="conformer", normalize_before=True,
attention_type="RelPosMHAXL",
num_encoder_layers=4, num_decoder_layers=0,
kernel_size=1,
causal=False
)
chunked_model_nopast.eval()
chunked_conf = DynChunkTrainConfig(chunk_size=4, left_context_size=0)
chunked_deps = infer_dependency_matrix(lambda x: chunked_model_nopast.encode(x, dynchunktrain_config = chunked_conf), seq_shape=[1, 16, 64])
plot_dependency_matrix(chunked_deps)
plt.show()
推理:详细细节
为推理封装特征提取器
我们简要介绍了用于流式推理的特征提取器的封装。我们在这里使用的Conformer特征提取器基本上有三层:
归一化(我们选择在流式处理时按块应用,如前所述——它实际上并不影响事情)
两个下采样CNN,每个都是一个步幅为2的卷积,有效地将时间维度除以4。
我们这里有两个问题:
我们在转换器级别定义块大小(在特征提取之后)。因此,我们需要确切地知道应该给提取器多少帧才能获得预期的形状。为此,我们需要确切地知道特征提取器如何转换形状。
我们需要正确处理左/过去和右/未来的上下文,以便特征提取器的行为基本上与训练期间完全相同。
让我们尝试可视化这个问题。我们将为16kHz的输入波形定义一个相当标准的Conformer特征提取器。请注意,x轴上的步幅是16,意味着1毫秒。因此,x轴的计数可以看作是毫秒(实际上输入样本比图中显示的要多16倍)。
from speechbrain.utils.streaming import infer_dependency_matrix, plot_dependency_matrix
from hyperpyyaml import load_hyperpyyaml
from matplotlib import pyplot as plt
feat_extractor_hparams = load_hyperpyyaml("""
compute_features: !new:speechbrain.lobes.features.Fbank
sample_rate: 16000
n_fft: 512
n_mels: 80
win_length: 32
cnn: !new:speechbrain.lobes.models.convolution.ConvolutionFrontEnd
input_shape: (8, 10, 80)
num_blocks: 2
num_layers_per_block: 1
out_channels: (64, 32)
kernel_sizes: (3, 3)
strides: (2, 2)
residuals: (False, False)
feat_extractor: !new:speechbrain.nnet.containers.LengthsCapableSequential
- !ref <compute_features>
- !ref <cnn>
properties: !apply:speechbrain.utils.filter_analysis.stack_filter_properties
- [!ref <compute_features>, !ref <cnn>]
""")
feat_extractor_hparams["cnn"].eval()
feat_extractor_deps = infer_dependency_matrix(
# we need some shape magic here to adapt the input and output shape to what infer_dependency_matrix expects
# for the input, squeeze the feature dimension
# for the output, flatten the channels dim as the output is of shape [batch, t, c0, c1]
lambda x: feat_extractor_hparams["feat_extractor"](x.squeeze(-1)).flatten(2),
# 100ms audio (@16kHz)
seq_shape=[1, 3200, 1],
# 1ms stride (@16kHz)
in_stride=16
)
feat_extractor_fig = plot_dependency_matrix(feat_extractor_deps)
feat_extractor_fig.set_size_inches(15, 10)
plt.show()

使用和定义过滤器属性
要解决这个问题:
我们将滤波器组提取和CNN视为具有特定步幅、核大小(加上我们不在此使用的扩张和因果性)的滤波器(在信号处理的意义上)。在SpeechBrain中,这些数据表示为
FilterProperties。我们为一些模块提供了
get_filter_properties方法(请注意,目前还不多)。stack_filter_properties然后用于“堆叠”这些过滤器,并获取整个特征提取器的结果属性。
让我们来演示这些。
from speechbrain.utils.filter_analysis import stack_filter_properties
print(f"""Filter properties of the fbank module (including the STFT):
fbank -> {feat_extractor_hparams['compute_features'].get_filter_properties()}
Filter properties of the downsampling CNN:
... of each layer:
cnn[0] -> {feat_extractor_hparams['cnn']['convblock_0'].get_filter_properties()}
cnn[1] -> {feat_extractor_hparams['cnn']['convblock_1'].get_filter_properties()}
... with both layers stacked:
cnn -> {feat_extractor_hparams['cnn'].get_filter_properties()}
Properties of the whole extraction module (fbank+CNN stacked):
both -> {feat_extractor_hparams['properties']}""")
Filter properties of the fbank module (including the STFT):
fbank -> FilterProperties(window_size=512, stride=160, dilation=1, causal=False)
Filter properties of the downsampling CNN:
... of each layer:
cnn[0] -> FilterProperties(window_size=3, stride=2, dilation=1, causal=False)
cnn[1] -> FilterProperties(window_size=3, stride=2, dilation=1, causal=False)
... with both layers stacked:
cnn -> FilterProperties(window_size=7, stride=4, dilation=1, causal=False)
Properties of the whole extraction module (fbank+CNN stacked):
both -> FilterProperties(window_size=1473, stride=640, dilation=1, causal=False)
提取模块的步幅为640个输入帧。由于我们处理的是16kHz,这相当于大约640/16000=40ms的步幅。
因此,块大小为16基本上意味着我们将在每个块中将输入移动16*40ms=640ms,无需担心窗口大小和填充。
请注意,步幅在这里相对容易计算。你可能会注意到它是所有三个步幅的乘积。窗口大小稍微复杂一些,完整的实现请参见FilterProperties.with_on_top。
最终结果是,我们可以将特征提取器视为具有已知属性的简单过滤器。这解决了我们之前的两个问题,因为我们都知道:
特征提取器生成
chunk_size时间步(在transformer级别)所需的输入帧数。窗口大小(以及其他属性)使我们能够准确知道需要保留多少帧作为左右上下文。
重要提示: 特征提取器的有效窗口大小对延迟有直接的负面影响!窗口大小绝不应高到接近块大小(就输入帧而言)。
自动包装非流式提取器
StreamingFeatureWrapper 是特征提取拼图的最后一块,它将我们有些任意的特征提取器转变为纯粹的分块提取器,它接受固定且已知数量的输入帧(参见 StreamingFeatureWrapper.forward)。
如果你好奇的话,这是一个低级别的演示用法;否则,这完全由 StreamingASR 抽象化了!
from speechbrain.lobes.features import StreamingFeatureWrapper
from speechbrain.utils.dynamic_chunk_training import DynChunkTrainConfig
feature_wrapper = StreamingFeatureWrapper(
module=feat_extractor_hparams["feat_extractor"],
properties=feat_extractor_hparams["properties"]
)
filter_properties = feat_extractor_hparams["properties"]
chunk_size = 4
# see: StreamingFeatureWrapper.forward docs
# reason for the `-1` is that the stride is only applied `window_size-1` times in such a filter
chunk_size_frames = (filter_properties.stride - 1) * chunk_size
batch_size = 1
# a fair amount of streaming stuff carries around _streaming contexts_, which are opaque objects
# that you are meant to reuse across calls for the same streaming session.
# these will be detailed further in the next subsection.
streaming_context = feature_wrapper.make_streaming_context()
print(f"Chunk size selected: {chunk_size} ({chunk_size_frames} frames, {1000*chunk_size_frames/16000:.3f}ms)")
for t in range(4): # imagine we're iterating over a stream, etc.
sample_chunk = torch.rand((batch_size, chunk_size_frames))
latest_outs = feature_wrapper(sample_chunk, context=streaming_context)
print(f"(bs, t, ch0, ch1) = {tuple(latest_outs.shape)}") # output for our chunk!
# normally you _may_ have to inject a final chunk of zeros.
# see StreamingASR for an example implementation.
Chunk size selected: 4 (2556 frames, 159.750ms)
(bs, t, ch0, ch1) = (1, 4, 20, 32)
(bs, t, ch0, ch1) = (1, 4, 20, 32)
(bs, t, ch0, ch1) = (1, 4, 20, 32)
(bs, t, ch0, ch1) = (1, 4, 20, 32)
这并没有告诉我们它真正做了什么。StreamingFeatureWrapper.forward的源代码最能说明这一点:
feat_pad_size = self.get_required_padding()
num_outputs_per_pad = self.get_output_count_per_pad_frame()
# consider two audio chunks of 6 samples (for the example), where
# each sample is denoted by 1, 2, ..., 6
# so chunk 1 is 123456 and chunk 2 is 123456
if context.left_context is None:
# for the first chunk we left pad the input by two padding's worth of zeros,
# and truncate the right, so that we can pretend to have right padding and
# still consume the same amount of samples every time
#
# our first processed chunk will look like:
# 0000123456
# ^^ right padding (truncated)
# ^^^^^^ frames that some outputs are centered on
# ^^ left padding (truncated)
chunk = torch.nn.functional.pad(chunk, (feat_pad_size * 2, 0))
else:
# prepend left context
#
# for the second chunk ownwards, given the above example:
# 34 of the previous chunk becomes left padding
# 56 of the previous chunk becomes the first frames of this chunk
# thus on the second iteration (and onwards) it will look like:
# 3456123456
# ^^ right padding (truncated)
# ^^^^^^ frames that some outputs are centered on
# ^^ left padding (truncated)
chunk = torch.cat((context.left_context, chunk), 1)
# our chunk's right context will become the start of the "next processed chunk"
# plus we need left padding for that one, so make it double
context.left_context = chunk[:, -feat_pad_size * 2 :]
feats = self.module(chunk, *extra_args, **extra_kwargs)
# truncate left and right context
feats = feats[:, num_outputs_per_pad:-num_outputs_per_pad, ...]
return feats
在上述情况下,我们有效地引入了超过80毫秒的填充/延迟,如下所示:
print(f"{1000 * feature_wrapper.get_required_padding() / 16000}ms")
80.0ms
这并不理想,但对于典型的块大小(大约500-1000毫秒)来说,这并不是一个巨大的惩罚。
然而,这确实强调了,虽然你可以随意调整特征提取器,但你应该小心其有效窗口大小不会爆炸。
流式上下文对象
为了实现流式处理,我们需要缓存/存储任意上下文张量以便在后续块中重复使用。
因为这些是极其特定于模型的,并且实际上并不共享功能,所以它们以数据类的形式实现,这些数据类是:
可变的: 上下文对象在给定块的前向传递后会被更新。同一个对象应该再次传递给下一个处理的块。
递归: 上下文对象可能包含任意数量的上下文对象。
Opaque: 这些包含的上下文对象可以是任意其他上下文对象类型,被视为需要移动的黑盒子。
每个这样的对象都包含任何所需的配置和一批流会话。该对象将在每次后续调用时重复使用,无论它被调用在哪个层上。
示例
我们的Conformer编码器的顶级类是TransformerASR抽象。
TransformerASRStreamingContext 是其相关的“流式上下文”。它被定义为:
@dataclass
class TransformerASRStreamingContext:
"""Streaming metadata and state for a `TransformerASR` instance."""
dynchunktrain_config: DynChunkTrainConfig
"""Dynamic Chunk Training configuration holding chunk size and context size
information."""
encoder_context: Any
"""Opaque encoder context information. It is constructed by the encoder's
`make_streaming_context` method and is passed to the encoder when using
`encode_streaming`.
"""
在上述情况下,encoder_context 是一个任意类型的字段,具体取决于所选的编码器。
TransformerASR 不需要了解其详细信息;它只需要能够创建、存储并传递它(例如,TransformerASR.encode_streaming 将调用 encoder.forward_streaming 并使用 context=context.encoder_context)。
对于Conformer,这将是一个ConformerEncoderStreamingContext,它需要持有一个ConformerEncoderLayerStreamingContext的列表(文档已删除):
@dataclass
class ConformerEncoderStreamingContext:
dynchunktrain_config: DynChunkTrainConfig
layers: List[ConformerEncoderLayerStreamingContext]
ConformerEncoderLayerStreamingContext 本身需要存储一堆张量(文档已删除):
@dataclass
class ConformerEncoderLayerStreamingContext:
mha_left_context_size: int
mha_left_context: Optional[torch.Tensor] = None
dcconv_left_context: Optional[torch.Tensor] = None
因此,如果您有一个为Conformer配置的TransformerASRStreamingContext对象,您可以通过context.encoder_context.layers[0].mha_left_context访问第一层的mha_left_context缓存对象。
创建流式上下文对象
就像每个模块都会有一个对应的StreamingContext数据类一样,它们也应该指定一个make_streaming_context方法。这个方法将由父模块或用户调用。通常,它会接受一个DynChunkTrainConfig对象,但也有一些例外。
就像上下文的数据结构是任意递归的一样,make_streaming_context可能会调用子模块自己的make_streaming_context方法。
让我们通过重用我们之前初始化的TransformerASR来演示:
test_context = chunked_model.make_streaming_context(DynChunkTrainConfig(16, 2))
test_context
TransformerASRStreamingContext(dynchunktrain_config=DynChunkTrainConfig(chunk_size=16, left_context_size=2), encoder_context=ConformerEncoderStreamingContext(dynchunktrain_config=DynChunkTrainConfig(chunk_size=16, left_context_size=2), layers=[ConformerEncoderLayerStreamingContext(mha_left_context_size=32, mha_left_context=None, dcconv_left_context=None), ConformerEncoderLayerStreamingContext(mha_left_context_size=32, mha_left_context=None, dcconv_left_context=None), ConformerEncoderLayerStreamingContext(mha_left_context_size=32, mha_left_context=None, dcconv_left_context=None), ConformerEncoderLayerStreamingContext(mha_left_context_size=32, mha_left_context=None, dcconv_left_context=None)]))
流式转发方法
对于需要流式上下文的模块,流式推理需要使用与通常的forward不同的方法,通常是forward_streaming(但不一定,例如参见TransformerASR.encode_streaming)。
请参见以下实际示例。在这里,我们选择了一个块大小为16,以及一个左上下文大小为4个块。观察每个后续块,随着左上下文的到来,左上下文张量的大小逐渐增加。一旦积累了足够的块,左上下文张量将保持在该长度。
test_context = chunked_model.make_streaming_context(DynChunkTrainConfig(16, 4))
for chunk_id in range(8):
print(f"chunk #{chunk_id}:")
test_chunk = torch.rand((1, 16, 64))
test_mha_context = test_context.encoder_context.layers[0].mha_left_context
model_output = chunked_model.encode_streaming(test_chunk, context=test_context)
print(f"\tbefore forward MHA left context: {tuple(test_mha_context.shape) if test_mha_context is not None else '(None)'}")
print(f"\tencode_streaming output: {tuple(model_output.shape)}")
chunk #0:
before forward MHA left context: (None)
encode_streaming output: (1, 16, 64)
chunk #1:
before forward MHA left context: (1, 16, 64)
encode_streaming output: (1, 16, 64)
chunk #2:
before forward MHA left context: (1, 32, 64)
encode_streaming output: (1, 16, 64)
chunk #3:
before forward MHA left context: (1, 48, 64)
encode_streaming output: (1, 16, 64)
chunk #4:
before forward MHA left context: (1, 64, 64)
encode_streaming output: (1, 16, 64)
chunk #5:
before forward MHA left context: (1, 64, 64)
encode_streaming output: (1, 16, 64)
chunk #6:
before forward MHA left context: (1, 64, 64)
encode_streaming output: (1, 16, 64)
chunk #7:
before forward MHA left context: (1, 64, 64)
encode_streaming output: (1, 16, 64)
流式分词器
我们仍然需要注意的一个小细节是流式上下文中的分词。
通常情况下,分词器总是同时解码完整的句子,这导致解码中的第一个空格(例如在▁are标记中)会被移除。
然而,在流式处理时,我们可能正在解码句子中间的部分,此时句子中间的空格不能被移除。spm_decode_preserve_leading_space处理这种情况,并需要携带一个小型的上下文对象。
流式传感器贪婪搜索
TransducerBeamSearcher 提供了一个 transducer_greedy_decode_streaming 方法,与其他 _streaming 方法类似,需要用户创建并携带一个上下文对象。
在这种情况下,它是一个相当简单的包装器,用于缓存并传递贪婪搜索器的最新隐藏状态。
推理:使用StreamingASR的实际示例
从训练好的模型到StreamingASR超参数
目前,在SpeechBrain中,您需要为训练和推理定义一个单独的超参数文件。您可以主要复制训练超参数,并根据推理的相关性删除/添加键。
在这种情况下,speechbrain.inference.ASR.StreamingASR,更高级别的推理接口,需要推理超参数以相对灵活的方式定义一组键和模块。
如果你查看文档,你可以找到以下超参数键和模块字典条目要求:
HPARAMS_NEEDED = [
"fea_streaming_extractor",
"make_decoder_streaming_context",
"decoding_function",
"make_tokenizer_streaming_context",
"tokenizer_decode_streaming",
]
MODULES_NEEDED = ["enc", "proj_enc"]
让我们看看这涉及到什么。对于我们的Conformer模型,我们可以使用speechbrain/asr-streaming-conformer-librispeech作为参考。(提醒一下,用!name:初始化的键只是对这里函数的引用。)参见:
make_tokenizer_streaming_context: !name:speechbrain.tokenizers.SentencePiece.SentencePieceDecoderStreamingContext
tokenizer_decode_streaming: !name:speechbrain.tokenizers.SentencePiece.spm_decode_preserve_leading_space
make_decoder_streaming_context: !name:speechbrain.decoders.transducer.TransducerGreedySearcherStreamingContext # default constructor
decoding_function: !name:speechbrain.decoders.transducer.TransducerBeamSearcher.transducer_greedy_decode_streaming
- !ref <Greedysearcher> # self
fea_streaming_extractor: !new:speechbrain.lobes.features.StreamingFeatureWrapper
module: !new:speechbrain.nnet.containers.LengthsCapableSequential
- !ref <compute_features>
- !ref <normalize>
- !ref <CNN>
# don't consider normalization as part of the input filter chain.
# normalization will operate at chunk level, which mismatches training
# somewhat, but does not appear to result in noticeable degradation.
properties: !apply:speechbrain.utils.filter_analysis.stack_filter_properties
- [!ref <compute_features>, !ref <CNN>]
根据前面的细节,这里应该没有什么特别令人惊讶的地方。但更详细地说,这个想法是通过超参数文件给模型提供一定程度的灵活性。我们实际上需要定义:
fea_streaming_extractor是一个StreamingFeatureWrapper(或任何具有兼容API的东西),并处理输入波形(同时提供滤波器属性等)modules.enc和modules.proj_enc,实际的编码器,查看StreamingASR.encode_chunk的源代码decoding_function可以调用为hparams.decoding_function(output_of_enc, context=decoding_context),其中……
decoding_context是从hparams.make_decoder_streaming_context()初始化的tokenizer_decode_streaming和make_decoder_streaming_context,查看StreamingASR.decode_chunk的源代码
至于训练后需要从保存目录移动的文件,到一个典型的流式Conformer模型目录中,用于StreamingASR,这些基本上是:
hyperparams.yaml(已修改用于推理)model.ckptnormalizer.ckpttokenizer.ckpt
使用StreamingASR进行推理
让我们利用speechbrain/asr-streaming-conformer-librispeech来演示流式音频解码。
from speechbrain.inference.ASR import StreamingASR
from speechbrain.utils.dynamic_chunk_training import DynChunkTrainConfig
asr_model = StreamingASR.from_hparams("speechbrain/asr-streaming-conformer-librispeech")
INFO:speechbrain.utils.fetching:Fetch hyperparams.yaml: Fetching from HuggingFace Hub 'speechbrain/asr-streaming-conformer-librispeech' if not cached
INFO:speechbrain.utils.fetching:Fetch custom.py: Fetching from HuggingFace Hub 'speechbrain/asr-streaming-conformer-librispeech' if not cached
INFO:speechbrain.utils.fetching:Fetch model.ckpt: Fetching from HuggingFace Hub 'speechbrain/asr-streaming-conformer-librispeech' if not cached
INFO:speechbrain.utils.fetching:Fetch model.ckpt: Fetching from HuggingFace Hub 'speechbrain/asr-streaming-conformer-librispeech' if not cached
INFO:speechbrain.utils.fetching:Fetch normalizer.ckpt: Fetching from HuggingFace Hub 'speechbrain/asr-streaming-conformer-librispeech' if not cached
INFO:speechbrain.utils.fetching:Fetch normalizer.ckpt: Fetching from HuggingFace Hub 'speechbrain/asr-streaming-conformer-librispeech' if not cached
INFO:speechbrain.utils.fetching:Fetch tokenizer.ckpt: Fetching from HuggingFace Hub 'speechbrain/asr-streaming-conformer-librispeech' if not cached
INFO:speechbrain.utils.fetching:Fetch tokenizer.ckpt: Fetching from HuggingFace Hub 'speechbrain/asr-streaming-conformer-librispeech' if not cached
INFO:speechbrain.utils.parameter_transfer:Loading pretrained files for: model, normalizer, tokenizer
这是一个简单的转录示例,它确实执行分块推理:
asr_model.transcribe_file(
"speechbrain/asr-streaming-conformer-librispeech/test-en.wav",
# select a chunk size of ~960ms with 4 chunks of left context
DynChunkTrainConfig(24, 4),
# disable torchaudio streaming to allow fetching from HuggingFace
# set this to True for your own files or streams to allow for streaming file decoding
use_torchaudio_streaming=False,
)
INFO:speechbrain.utils.fetching:Fetch test-en.wav: Fetching from HuggingFace Hub 'speechbrain/asr-streaming-conformer-librispeech' if not cached
'THE BIRCH CANOE SLID ON THE SMOOTH PLANKS'
让我们尝试一个更具挑战性的例子:转录一个长达数分钟的音频文件。这通常会导致一个序列过长,由于长序列上变换器的内存和计算成本,无法进行处理。
这次,我们使用transcribe_file_streaming。这个方法使我们能够在处理转录块时对其进行迭代。
from speechbrain.utils.fetching import fetch
long_audio_fname = fetch("Economics-of-coffee.ogg", "https://upload.wikimedia.org/wikipedia/commons/8/81", savedir=".")
long_audio_chunks = []
for i, decoded_chunk in enumerate(asr_model.transcribe_file_streaming(long_audio_fname, DynChunkTrainConfig(16, 4))):
print(f"{i:>3}: \"{decoded_chunk}\"")
long_audio_chunks.append(decoded_chunk)
# let's just process the 20 first chunks as a demo
if i >= 20:
break
INFO:speechbrain.utils.fetching:Fetch Economics-of-coffee.ogg: Using existing file/symlink in /home/sdelang/projects/src/python/speechbrain/docs/tutorials/nn/Economics-of-coffee.ogg
0: ""
1: ""
2: "ECONOMICS"
3: " OF COFFEE"
4: ""
5: " FROM"
6: " WICKPEDIA"
7: " THE FREE"
8: " SECLOPAEDIA"
9: ""
10: ""
11: " COFFEE"
12: " IS AN IMPORTAN"
13: "T COM"
14: "MODITY"
15: " AND A POPULAR"
16: " BEVERAGE"
17: ""
18: " OVER A TWO POINT"
19: " TWO FIVE BILL"
20: "ION CUPS"
模型犯了一些错误(考虑到它的训练内容和我们测试推理的内容,这并不特别令人惊讶),但除此之外,流式处理似乎工作得很好,跨越块的单词转录看起来也没有混乱。
ffmpeg 直播功能
StreamingASR 支持 torchaudio 的 ffmpeg 流功能。这意味着你可以轻松地做一些事情,比如转录网络广播流:
audio_stream_url = "http://as-hls-ww-live.akamaized.net/pool_904/live/ww/bbc_radio_fourfm/bbc_radio_fourfm.isml/bbc_radio_fourfm-audio%3d96000.norewind.m3u8"
for i, decoded_chunk in enumerate(asr_model.transcribe_file_streaming(audio_stream_url, DynChunkTrainConfig(16, 4))):
print(decoded_chunk, end="")
# let's just process the 20 first chunks as a demo
if i >= 20:
break
THEY WERE SO QUICK THEY DID THIS AIM AND THEN IT TOOK THEM TWO DAYS TO INSTALL THE SECOND DAY THEY WORKED UNTIL AFTER SEVEN P M AND THAT WAS IT I MEAN YET LIKE
手动转录块
更多示例可在HuggingFace页面上找到。特别是,Gradio示例展示了如何绕过音频加载功能,自行处理任意音频块流。
替代方案和进一步阅读
本教程介绍了对基本Conformer模型进行修改以支持分块流式处理。
多年来,为了提升准确性、提高运行时性能、降低内存使用、减少实际延迟或添加其他功能,已经开发了Conformer模型的替代方案和改进版本。
以下远非完整列表,并且不仅包括已成功适应流式处理环境的架构。
FastConformer(尽管简单,但截至2024年仍被NVIDIA广泛使用,并且易于从普通的Conformer迁移)
在训练或推理管道的其他部分也有很多研究。我们未来可能会扩展这个列表,加入更多的参考资料:
引用SpeechBrain
如果您在研究中或业务中使用SpeechBrain,请使用以下BibTeX条目引用它:
@misc{speechbrainV1,
title={Open-Source Conversational AI with {SpeechBrain} 1.0},
author={Mirco Ravanelli and Titouan Parcollet and Adel Moumen and Sylvain de Langen and Cem Subakan and Peter Plantinga and Yingzhi Wang and Pooneh Mousavi and Luca Della Libera and Artem Ploujnikov and Francesco Paissan and Davide Borra and Salah Zaiem and Zeyu Zhao and Shucong Zhang and Georgios Karakasidis and Sung-Lin Yeh and Pierre Champion and Aku Rouhe and Rudolf Braun and Florian Mai and Juan Zuluaga-Gomez and Seyed Mahed Mousavi and Andreas Nautsch and Xuechen Liu and Sangeet Sagar and Jarod Duret and Salima Mdhaffar and Gaelle Laperriere and Mickael Rouvier and Renato De Mori and Yannick Esteve},
year={2024},
eprint={2407.00463},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2407.00463},
}
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}