![]() 要在GitHub上执行或查看/下载此笔记本
要在GitHub上执行或查看/下载此笔记本
语音活动检测
语音活动检测(VAD)的目标是检测音频录音中包含语音的片段。
如下图所示,VAD的输入是一个音频信号(或其对应的特征)。输出可能是一个序列,其中包含语音的时间帧为“1”,非语音帧为“0”。

作为替代方案,VAD 可以在输出中提供检测到语音活动的边界。例如:
segment_001 0.00 2.57 NON_SPEECH
segment_002 2.57 8.20 SPEECH
segment_003 8.20 9.10 NON_SPEECH
segment_004 9.10 10.93 SPEECH
segment_005 10.93 12.00 NON_SPEECH
segment_006 12.00 14.40 SPEECH
segment_007 14.40 15.00 NON_SPEECH
VAD 有什么用处?
VAD在许多语音处理流程中扮演着关键角色。当我们希望仅对录音中的语音部分应用处理算法时,就会使用它。
例如,它通常被用作语音识别、语音增强、说话人分割等许多系统的预处理步骤。
为什么具有挑战性?
区分语音和非语音信号对人类来说是非常自然的。然而,对于机器来说,这要复杂得多。一个好的语音活动检测(VAD)应该能够在嘈杂和混响的条件下精确检测语音活动。在现实生活中,可能的噪声源非常多(例如,音乐、电话铃声、警报等),这使得这个问题对机器来说具有挑战性。
此外,一个好的VAD应该能够处理短的和非常长的录音(例如,会议),并且理想情况下,计算成本不应该太高。
管道描述
鲁棒语音活动检测几十年来一直是一个非常活跃的研究领域。如今,深度学习在这个问题中也扮演着至关重要的角色。
在本教程中,我们使用了一个神经网络,它为每个输入帧提供语音/非语音预测。然后对帧级后验概率进行后处理以检索最终的语音边界,如下图所示:

更准确地说,我们在这里计算标准的FBANK特征,并将它们插入到CRDNN模型中(该模型结合了卷积层、循环层和全连接层)。输出通过sigmoid函数进行处理,以执行二分类。网络使用二元交叉熵进行训练。预测结果对于语音帧将接近1,对于非语音帧将接近0。
在推理时,二进制预测会进行后处理。例如,我们对它们应用一个阈值来识别候选语音区域。之后,我们可以应用其他类型的后处理,例如合并接近的片段或删除太短的片段。我们将在推理部分详细描述这一点。
现在,让我们简要讨论一下如何使用SpeechBrain训练这样的模型。
培训
SpeechBrain 提供了一个使用 LibriParty 数据集 训练 VAD 的配方。这是我们为 VAD 训练等任务创建的数据集。它包含多个模拟的声学场景,其中有周期性的语音和噪声序列(单独或同时)活跃。
除此之外,训练配方还使用Musan(包含语音、噪声和音乐信号)、CommonLanguage(包含48种语言的语音)和open-rir(包含噪声和脉冲响应)动态创建了几个其他模拟声学场景。
实时模拟的声学场景探索了不同的情景,例如噪音+语音、语音到噪音的过渡、噪音到语音的过渡等。
与其他SpeechBrain配方类似,可以使用以下命令训练模型:
cd recipes/LibriParty/VAD
python train.py hparams/train.yaml
请遵循配方中提供的README文件,并确保在开始训练之前已下载所有数据。
除了大量使用语音增强/污染之外,这个配方没有什么特别之处。因此,让我们更多地关注推理部分,它依赖于一些自定义组件。
推理
我们现在可以专注于推理部分。推理部分比平常稍微复杂一些,因为我们设计它能够在长时间录音上工作,并支持多种后处理网络预测的技术。
我们将解决所有上述方面。但是,让我们首先安装speechbrain:
%%capture
# Installing SpeechBrain via pip
BRANCH = 'develop'
!python -m pip install git+https://github.com/speechbrain/speechbrain.git@$BRANCH
%%capture
!wget -O /content/example_vad_music.wav "https://www.dropbox.com/scl/fi/vvffxbkkuv79g0d4c7so3/example_vad_music.wav?rlkey=q5m5wc6y9fsfvt43x5yy8ohrf&dl=1"
让我们读取一个语音信号:
import torch
import torchaudio
import matplotlib.pyplot as plt
audio_file = "/content/example_vad_music.wav"
signal, fs = torchaudio.load(audio_file)
signal = signal.squeeze()
time = torch.linspace(0, signal.shape[0]/fs, steps=signal.shape[0])
plt.plot(time, signal)
from IPython.display import Audio
Audio(audio_file)
<IPython.lib.display.Audio object>
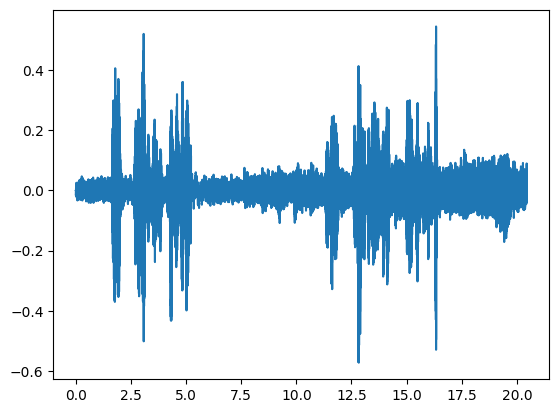
我们现在可以按照以下方式使用在上一步训练的VAD:
from speechbrain.inference.VAD import VAD
VAD = VAD.from_hparams(source="speechbrain/vad-crdnn-libriparty", savedir="pretrained_models/vad-crdnn-libriparty")
boundaries = VAD.get_speech_segments(audio_file)
VAD.save_boundaries(boundaries)
segment_001 0.00 0.23 NON_SPEECH
segment_002 0.23 5.58 SPEECH
segment_003 5.58 10.90 NON_SPEECH
segment_004 10.90 16.63 SPEECH
如你所见,两个语音部分被正确检测出来。音乐部分被正确分类为非语音片段,而同时存在音乐和语音的部分被分类为语音。
推理管道(详情)
检测语音片段的流程如下:
计算帧级别的后验概率。
在后验概率上应用一个阈值。
在此基础上推导候选语音段。
在每个候选段内应用能量VAD(可选)。
合并过于接近的段。
移除太短的片段。
双重检查语音片段(可选)。
为了使调试更容易,界面更加模块化和透明,我们允许用户访问这些中间步骤的输出。
在某些情况下,这些步骤并不都是必需的。用户可以自由定制管道及其超参数,以提高其数据的性能。
让我们从后验计算开始。
1- 后验计算
神经模型提供的输出对于非语音帧应接近零,对于语音帧应接近1。
时间分辨率取决于特征提取部分和所采用的神经模型。在这种情况下,我们每10毫秒进行一次预测(这在语音处理中是非常标准的)。
要计算后验概率,您可以使用以下命令:
prob_chunks = VAD.get_speech_prob_file(audio_file)
plt.plot(prob_chunks.squeeze())
[<matplotlib.lines.Line2D at 0x7f301f0de980>]
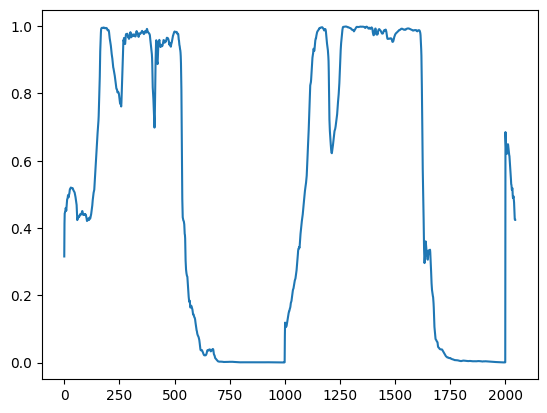
正如预期的那样,语音区域的值较高,而音乐区域的值较低。
get_speech_prob_file function 旨在处理长音频录音。它计算大块(例如30秒)的后验概率,这些大块按顺序读取以避免在内存中存储长信号。
每个大块又被分割成更小的块(例如10秒),这些小块并行处理。
您可以根据内存限制调整large_chunk_size和small_chunk_size。如果您有足够的内存,可以使用它来存储更大的信号块(例如,5分钟)。这可以通过增加large_chunk_size来实现,并且会使VAD(稍微)更快。
2- 应用阈值
现在,我们可以通过应用阈值来检测候选语音段。
要做到这一点,你可以使用以下函数:
prob_th = VAD.apply_threshold(prob_chunks, activation_th=0.5, deactivation_th=0.25).float()
plt.plot(prob_th.squeeze())
[<matplotlib.lines.Line2D at 0x7f301f131450>]
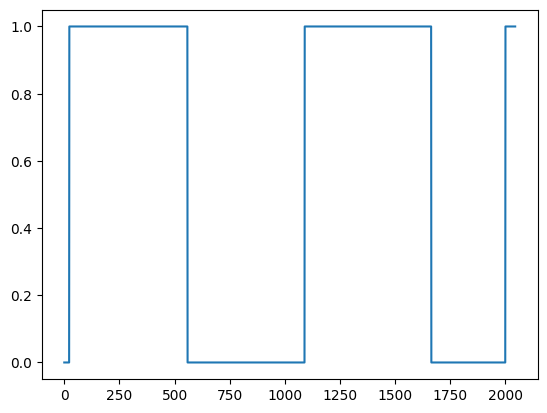
我们允许用户设置两个不同的阈值,而不是应用单一阈值(例如,0.5),一个用于决定何时开始语音段(activation_th),另一个用于检测何时停止语音段(deactivation_th)。
根据我们的经验,将activation_th设置为高于deactivation_th是有意义的(例如,aactivation_th=0.5,deactivation_th=0.25)。
然而,用户可以调整这些超参数,使VAD或多或少的具有选择性。
3- 获取边界
现在,我们可以从阈值化的后验概率中推导出语音片段的边界:
boundaries = VAD.get_boundaries(prob_th)
VAD.save_boundaries(boundaries, audio_file=audio_file)
segment_001 0.00 0.23 NON_SPEECH
segment_002 0.23 5.58 SPEECH
segment_003 5.58 10.90 NON_SPEECH
segment_004 10.90 16.63 SPEECH
segment_005 16.63 20.00 NON_SPEECH
segment_006 20.00 20.43 SPEECH
segment_007 20.43 20.45 NON_SPEECH
boundaries 张量包含每个语音片段的开始和结束秒数。
方法 save_boundaries 可用于以人类可读的格式绘制边界和/或将它们保存到文件中(使用 save_path 参数)。
4- 基于能量的VAD(可选)
训练好的神经VAD倾向于检测较大的语音片段,其中彼此接近的较小语音片段会被合并。
如果用户需要更高的分辨率,一种可能的方法是在检测到的语音段内应用基于能量的VAD。基于能量的VAD通过滑动窗口处理语音段,计算每个块内的能量。能量分布被归一化,使得我们有0.5和+-0.5的标准差。然后我们应用一个阈值并将原始语音段分割成更小的部分。
这是通过以下方式完成的:
boundaries = VAD.energy_VAD(audio_file,boundaries, activation_th=0.8, deactivation_th=0.0)
VAD.save_boundaries(boundaries, audio_file=audio_file)
segment_001 0.00 1.66 NON_SPEECH
segment_002 1.66 2.13 SPEECH
segment_003 2.13 2.70 NON_SPEECH
segment_004 2.70 4.03 SPEECH
segment_005 4.03 4.27 NON_SPEECH
segment_006 4.27 5.26 SPEECH
segment_007 5.26 11.37 NON_SPEECH
segment_008 11.37 11.94 SPEECH
segment_009 11.94 12.63 NON_SPEECH
segment_010 12.63 13.12 SPEECH
segment_011 13.12 13.26 NON_SPEECH
segment_012 13.26 14.28 SPEECH
segment_013 14.28 14.99 NON_SPEECH
segment_014 14.99 15.67 SPEECH
segment_015 15.67 15.79 NON_SPEECH
segment_016 15.79 16.06 SPEECH
segment_017 16.06 16.30 NON_SPEECH
segment_018 16.30 16.42 SPEECH
segment_019 16.42 20.02 NON_SPEECH
segment_020 20.02 20.10 SPEECH
segment_021 20.10 20.18 NON_SPEECH
segment_022 20.18 20.18 SPEECH
segment_023 20.18 20.22 NON_SPEECH
segment_024 20.22 20.22 SPEECH
segment_025 20.22 20.29 NON_SPEECH
segment_026 20.29 20.35 SPEECH
segment_027 20.35 20.37 NON_SPEECH
segment_028 20.37 20.37 SPEECH
segment_029 20.37 20.42 NON_SPEECH
segment_030 20.42 20.42 SPEECH
segment_031 20.42 20.45 NON_SPEECH
用户可以通过调整activation_th和deactivation_th来拥有一个或多或少的选择性VAD。
与神经VAD不同,能量VAD倾向于对输入进行过度分割。我们通过后处理边界来改进这一点,如下所示。
5- 合并接近的段
用户可能需要为VAD选择所需的分辨率(最佳粒度级别可能取决于任务)。
例如,合并彼此过于接近的段可能是有意义的。
这是通过以下方法完成的:
# 5- Merge segments that are too close
boundaries = VAD.merge_close_segments(boundaries, close_th=0.250)
VAD.save_boundaries(boundaries, audio_file=audio_file)
segment_001 0.00 1.66 NON_SPEECH
segment_002 1.66 2.13 SPEECH
segment_003 2.13 2.70 NON_SPEECH
segment_004 2.70 5.26 SPEECH
segment_005 5.26 11.37 NON_SPEECH
segment_006 11.37 11.94 SPEECH
segment_007 11.94 12.63 NON_SPEECH
segment_008 12.63 14.28 SPEECH
segment_009 14.28 14.99 NON_SPEECH
segment_010 14.99 16.42 SPEECH
segment_011 16.42 20.02 NON_SPEECH
segment_012 20.02 20.42 SPEECH
segment_013 20.42 20.45 NON_SPEECH
在这种情况下,我们合并了间隔小于250毫秒的片段。用户可以调整close_th并根据自己的需求进行调优。
6- 移除短片段
移除可能被错误分类为语音的短孤立片段也是有意义的:
# 6- Remove segments that are too short
boundaries = VAD.remove_short_segments(boundaries, len_th=0.250)
VAD.save_boundaries(boundaries, audio_file=audio_file)
segment_001 0.00 1.66 NON_SPEECH
segment_002 1.66 2.13 SPEECH
segment_003 2.13 2.70 NON_SPEECH
segment_004 2.70 5.26 SPEECH
segment_005 5.26 11.37 NON_SPEECH
segment_006 11.37 11.94 SPEECH
segment_007 11.94 12.63 NON_SPEECH
segment_008 12.63 14.28 SPEECH
segment_009 14.28 14.99 NON_SPEECH
segment_010 14.99 16.42 SPEECH
segment_011 16.42 20.02 NON_SPEECH
segment_012 20.02 20.42 SPEECH
segment_013 20.42 20.45 NON_SPEECH
在这种情况下,我们移除短于250毫秒的片段。请注意,我们首先合并了相近的片段,然后才移除较短的片段。这有助于仅移除孤立的短片段。
7- 双重检查语音片段(可选)
此时,我们可以获取经过后处理的语音片段,并再次检查它们是否真的包含语音。这是通过以下方式完成的:
# 7- Double-check speech segments (optional).
boundaries = VAD.double_check_speech_segments(boundaries, audio_file, speech_th=0.5)
VAD.save_boundaries(boundaries, audio_file=audio_file)
segment_001 0.00 1.66 NON_SPEECH
segment_002 1.66 2.13 SPEECH
segment_003 2.13 2.70 NON_SPEECH
segment_004 2.70 5.26 SPEECH
segment_005 5.26 11.37 NON_SPEECH
segment_006 11.37 11.94 SPEECH
segment_007 11.94 12.63 NON_SPEECH
segment_008 12.63 14.28 SPEECH
segment_009 14.28 14.99 NON_SPEECH
segment_010 14.99 16.42 SPEECH
segment_011 16.42 20.45 NON_SPEECH
该方法在检测到的语音段上再次使用神经VAD。如果段内的平均后验概率大于speech_th(在这种情况下,speech_th=0.5),则确认该语音段。否则,将其移除。
可视化
我们还实现了一些实用工具来帮助用户可视化VAD的输出:
upsampled_boundaries = VAD.upsample_boundaries(boundaries, audio_file)
此函数创建一个与原始音频记录具有相同维度的“VAD信号”。这样,可以将它们一起绘制:
time = torch.linspace(0, signal.shape[0]/fs, steps=signal.shape[0])
plt.plot(time, signal)
plt.plot(time, upsampled_boundaries.squeeze())
[<matplotlib.lines.Line2D at 0x7f301f0b5fc0>]

有关更多详细信息,还可以对VAD分数进行上采样和可视化:
upsampled_vad_scores = VAD.upsample_VAD(prob_chunks, audio_file)
plt.plot(time, signal)
plt.plot(time, upsampled_boundaries.squeeze())
plt.plot(time, upsampled_vad_scores.squeeze())
[<matplotlib.lines.Line2D at 0x7f301f105330>]
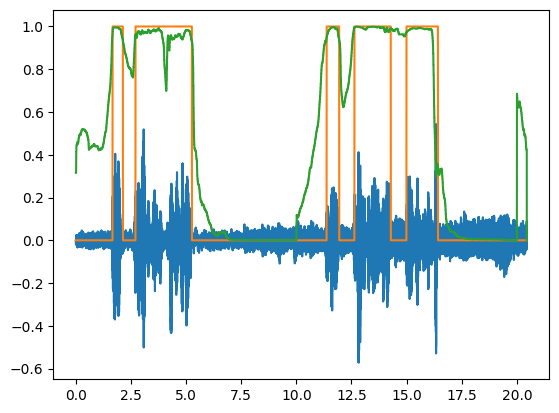
作为替代方案,用户可以将VAD文件保存并使用音频可视化软件(如audacity)与原始文件一起打开。
就这样!祝您VAD愉快!
附录:关于使用基于能量的VAD
如果使用基于能量的VAD,合并、移除、双重检查操作的顺序很重要。让我们在基于能量的VAD之后立即使用double_check_speech_segments,然后使用merge_close_segments。一些语音帧被丢弃了:
# plotted boundaries may be scaled down to compare many at once
def plot_boundaries(b, color):
upsampled = VAD.upsample_boundaries(b, audio_file)
plt.plot(time, upsampled.squeeze(), color)
# first figures - from CRDNN VAD to energy VAD
fig, axs = plt.subplots(3, 3, figsize=(16, 12))
plt.sca(axs[0, 0])
plt.title('1a. CRDNN VAD scores')
plt.plot(time, signal)
plt.plot(time, upsampled_vad_scores.squeeze(), 'green')
# CRDNN boundaries
plt.sca(axs[1, 0])
plt.title('1b. CRDNN VAD boundaries')
plt.plot(time, signal)
boundaries = VAD.get_boundaries(prob_th)
plot_boundaries(boundaries, 'orange')
# energy VAD boundaries
plt.sca(axs[2, 0])
plt.title('1c. Energy VAD boundaries based on CRDNN')
plt.plot(time, signal)
boundaries_energy = VAD.energy_VAD(audio_file, boundaries, activation_th=0.8, deactivation_th=0.0)
plot_boundaries(boundaries_energy, 'purple')
# second figure - double-check, then merge
plt.sca(axs[0, 1])
plt.title('2a. Energy VAD (same as 1c)')
plt.plot(time, signal)
plot_boundaries(boundaries_energy, 'purple')
# double-check
plt.sca(axs[1, 1])
plt.title('2b. Double-check (too early)')
plt.plot(time, signal)
boundaries = VAD.double_check_speech_segments(boundaries_energy, audio_file, speech_th=0.5)
plot_boundaries(boundaries, 'red')
# merge (too late)
plt.sca(axs[2, 1])
plt.title('2c. Merge short segments (too late)')
plt.plot(time, signal)
boundaries = VAD.merge_close_segments(boundaries, close_th=0.250)
plot_boundaries(boundaries, 'black')
# third figure - merge, remove, double-check
plt.sca(axs[0, 2])
plt.title('3a. Energy VAD (same as 1c)')
plt.plot(time, signal)
plot_boundaries(boundaries_energy, 'purple')
# merge
plt.sca(axs[1, 2])
plt.title('3b. Merge short segments (as above)')
plt.plot(time, signal)
boundaries = VAD.merge_close_segments(boundaries_energy, close_th=0.250)
plot_boundaries(boundaries, 'black')
# merge
plt.sca(axs[2, 2])
plt.title('3c. Remove short segments & double-check (as above)')
plt.plot(time, signal)
boundaries = VAD.remove_short_segments(boundaries, len_th=0.250)
boundaries = VAD.double_check_speech_segments(boundaries, audio_file, speech_th=0.5)
plot_boundaries(boundaries, 'red')
Exception ignored in: <function _xla_gc_callback at 0x7f3035dbd750>
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/jax/_src/lib/__init__.py", line 97, in _xla_gc_callback
def _xla_gc_callback(*args):
KeyboardInterrupt:
引用SpeechBrain
如果您在研究中或业务中使用SpeechBrain,请使用以下BibTeX条目引用它:
@misc{speechbrainV1,
title={Open-Source Conversational AI with {SpeechBrain} 1.0},
author={Mirco Ravanelli and Titouan Parcollet and Adel Moumen and Sylvain de Langen and Cem Subakan and Peter Plantinga and Yingzhi Wang and Pooneh Mousavi and Luca Della Libera and Artem Ploujnikov and Francesco Paissan and Davide Borra and Salah Zaiem and Zeyu Zhao and Shucong Zhang and Georgios Karakasidis and Sung-Lin Yeh and Pierre Champion and Aku Rouhe and Rudolf Braun and Florian Mai and Juan Zuluaga-Gomez and Seyed Mahed Mousavi and Andreas Nautsch and Xuechen Liu and Sangeet Sagar and Jarod Duret and Salima Mdhaffar and Gaelle Laperriere and Mickael Rouvier and Renato De Mori and Yannick Esteve},
year={2024},
eprint={2407.00463},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2407.00463},
}
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}