通过邻居采样扩展GNNs
图神经网络(Graph Neural Networks)面临的挑战之一是如何将其扩展到大型图,例如在工业和社会应用中。传统的深度神经网络通过将训练损失分解为单个样本(称为小批量)并随机近似精确梯度,已知能够很好地扩展到大量数据。相比之下,在图神经网络中应用随机小批量训练是具有挑战性的,因为给定节点的嵌入递归地依赖于其所有邻居的嵌入,导致节点之间的高度相互依赖性,这种依赖性随着层数的增加呈指数增长。这种现象通常被称为邻居爆炸。作为一种简单的解决方法,图神经网络通常以全批量的方式执行(参见这里的示例),其中图神经网络可以访问其所有层中的所有隐藏节点表示。然而,由于内存限制和收敛速度慢,这在大型图中是不可行的。
可扩展性技术对于将GNN应用于大规模图以减轻由小批量训练引起的邻居爆炸问题是不可或缺的,即 节点级、层级或子图级采样技术,或将传播与预测解耦。 在本教程中,我们将更详细地介绍最常见的节点级采样方法,最初在“Inductive Representation Learning on Large Graphs”论文中引入。
邻居采样
PyG 通过其 torch_geometric.loader.NeighborLoader 类实现了邻居采样。
邻居采样的工作原理是递归地为节点 \(v \in \mathcal{V}\) 采样最多 \(k\) 个邻居,即 \(\tilde{\mathcal{N}}(v) \subset \mathcal{N}(v)\) 且 \(|\tilde{\mathcal{N}}| \le k\),从而使得整体的 \(L\) 跳邻域大小限制在 \(\mathcal{O}(k^L)\)。
也就是说,从一组种子节点 \(\mathcal{B} \subset \mathcal{V}\) 开始,我们为每个节点 \(v \in \mathcal{B}\) 采样最多 \(k\) 个邻居,然后继续为前一跳中的每个采样节点采样邻居,依此类推。
生成的图结构在每个节点 \(v \in \mathcal{B}\) 周围包含一个有向的 \(L\) 跳子图,保证每个节点至少有一条长度不超过 \(L\) 的路径连接到至少一个种子节点 \(\mathcal{B}\)。
因此,具有 \(L\) 层的消息传递 GNN 将在其计算图中包含所有采样节点。
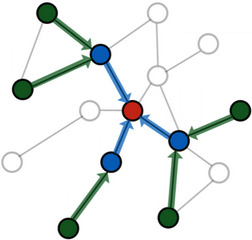
需要注意的是,邻居采样只能在某种程度上缓解邻居爆炸问题,因为整体邻居大小仍然随着层数的增加呈指数增长。 因此,通常进行超过两到三次迭代的采样是不可行的。
通常情况下,采样的跳数和消息传递层数保持同步。
具体来说,如果采样的跳数超过了消息传递层数,这将非常浪费,因为GNN将永远无法将后续跳中采样的节点特征整合到其种子节点的最终节点表示中。
然而,仍然可以使用更深的GNN,但需要注意将采样的子图转换为双向变体,以确保正确的消息传递流。
PyG通过在NeighborLoader中提供一个额外的参数来支持这一点,而其他小批量技术则是为这种用例设计的,例如,ClusterLoader,GraphSAINTSampler和ShaDowKHopSampler。
Basic Usage
注意
在本教程的这一部分中,我们将学习如何利用 Node2Vec 类在 PyG 中以小批量方式训练单图上的 GNN。
一个在大规模真实数据上完全可用的示例可以在 examples/reddit.py 中找到。
NeighborLoader 是从一个 PyG Data 或 HeteroData 对象初始化的,并定义了应如何执行采样:
input_nodes定义了我们要从中开始采样的种子节点集合。num_neighbors定义了在每个跳数中为每个节点采样的邻居数量。batch_size定义了我们一次想要考虑的种子节点的大小。replace定义了是否进行有放回或无放回的抽样。shuffle定义了在每个epoch是否应该打乱种子节点。
import torch
from torch_geometric.data import Data
from torch_geometric.loader import NeighborLoader
x = torch.randn(8, 32) # Node features of shape [num_nodes, num_features]
y = torch.randint(0, 4, (8, )) # Node labels of shape [num_nodes]
edge_index = torch.tensor([
[2, 3, 3, 4, 5, 6, 7],
[0, 0, 1, 1, 2, 3, 4]],
)
# 0 1
# / \/ \
# 2 3 4
# | | |
# 5 6 7
data = Data(x=x, y=y, edge_index=edge_index)
loader = NeighborLoader(
data,
input_nodes=torch.tensor([0, 1]),
num_neighbors=[2, 1],
batch_size=1,
replace=False,
shuffle=False,
)
在这里,我们初始化了NeigborLoader来为前两个节点采样子图,其中我们希望在第一次跳中采样2个邻居,在第二次跳中采样1个邻居。
我们的batch_size设置为1,这样input_nodes将被分割成大小为1的块。
在执行NeighborLoader时,我们期望种子节点0在第一跳中采样节点2和3。在第二跳中,节点2采样节点5,节点3采样节点6。
让我们通过查看loader的输出来确认:
batch = next(iter(loader))
batch.edge_index
>>> tensor([[1, 2, 3, 4],
[0, 0, 1, 2]])
batch.n_id
>>> tensor([0, 2, 3, 5, 6])
batch.batch_size
>>> 1
NeighborLoader 将返回一个 Data 对象,该对象包含以下属性:
batch.edge_index包含子图的边索引。batch.n_id包含所有采样节点的原始节点索引。batch.batch_size包含种子节点的数量/批次大小。
此外,节点和边的特征将被过滤,仅分别包含采样节点/边的特征。
重要的是,batch.edge_index 包含了重新标记节点索引的采样子图,因此其索引范围从 0 到 batch.num_nodes - 1。
如果你想重建 batch.edge_index 的原始节点索引,请执行以下操作:
batch.n_id[batch.edge_index]
>>> tensor([[2, 3, 5, 6],
[0, 0, 2, 3]])
此外,虽然NeighborLoader从种子节点开始采样,生成的子图将包含指向种子节点的边。
这与默认的PyG消息传递流程从源节点到目标节点非常吻合。
最后,NeighborLoader 输出中的节点保证是排序的。
特别是,前 batch_size 个采样节点将与用于采样的种子节点完全匹配:
batch.n_id[:batch.batch_size]
>>> tensor([0])
之后,我们可以使用 NeighborLoader 作为数据加载例程,以在小批量方式下训练大规模图上的GNNs。
为此,让我们创建一个简单的两层 GraphSAGE 模型:
from torch_geometric.nn import GraphSAGE
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GraphSAGE(
in_channels=32,
hidden_channels=64,
out_channels=4,
num_layers=2
).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
我们现在可以结合loader和model来定义我们的训练流程:
import torch.nn.functional as F
for batch in loader:
optimizer.zero_grad()
batch = batch.to(device)
out = model(batch.x, batch.edge_index)
# NOTE Only consider predictions and labels of seed nodes:
y = batch.y[:batch.batch_size]
out = out[:batch.batch_size]
loss = F.cross_entropy(out, y)
loss.backward()
optimizer.step()
训练循环遵循与任何其他PyTorch训练循环类似的设计。
唯一重要的区别是,默认情况下模型将输出形状为[batch.num_nodes, *]的矩阵,而我们只对种子节点的预测感兴趣。
因此,我们可以在节点预测和真实信息batch.y上使用高效的切片,仅获取实际种子节点的预测和真实信息。
这确保了我们仅使用前batch_size个节点进行损失和指标计算。
层次扩展
Neighborloader的一个缺点是,它会在网络的所有深度为所有采样的节点计算表示。
然而,在后续跳数中采样的节点不再对种子节点在后续GNN层中的表示有贡献,因此进行了无用的计算。
NeighborLoader会稍微慢一些,因为我们正在计算不再需要的节点的嵌入。
这是我们为了获得一个干净、模块化且易于实验的GNN设计所做的权衡,该设计不将模型的定义与其使用的数据加载器例程绑定在一起。
分层邻域采样教程展示了如何消除这种开销并进一步加速小批量GNN的训练和推理。
高级选项
NeighborLoader 提供了更多高级使用的功能。特别是,
NeighborLoader支持在异构图和同构图上进行采样。 对于在异构图上的采样,只需使用HeteroData对象初始化它即可。 通过NeighborLoader在异构图上进行采样,可以精细控制采样参数,例如,它允许为每种边类型单独指定采样的邻居数量。 更多信息,请查看 异构图学习 教程。默认情况下,
NeighborLoader将不同种子节点的采样节点融合到一个子图中。 这样,种子节点的共享邻居在生成的子图中不会被重复,从而节省内存。 你可以通过将disjoint=True选项传递给NeighborLoader来禁用此行为。默认情况下,从
NeighborLoader返回的子图将是有向的,这限制了其使用于具有与采样跳数相同深度的GNNs。 如果你想使用更深的GNNs,请指定subgraph_type选项。 如果设置为"bidirectional",采样的边将被转换为双向边。 如果设置为"induced",返回的子图将包含所有采样节点的诱导子图。NeighborLoader旨在从单个种子节点执行采样。因此,它不直接适用于链接预测场景。对于这种用例,我们开发了LinkNeighborLoader,它期望一组输入边,并将返回通过从源节点和目标节点进行邻居采样创建的子图。