点云处理
本教程解释了如何利用图神经网络(GNNs)对点云数据进行操作和训练。 尽管点云默认不带有图结构,但我们可以利用PyG转换使其适用于PyG中提供的全套GNNs。 关键思想是从点云中创建一个合成图,通过GNN的消息传递方案从中学习有意义的局部几何结构。 这些点表示随后可以用于,例如,执行点云分类或分割。
3D点云数据集
PyG 提供了多个点云数据集,例如 PCPNetDataset、S3DIS 和 ShapeNet 数据集。
为了帮助入门,我们还提供了 GeometricShapes 数据集,这是一个包含各种几何形状(如立方体、球体或金字塔)的玩具数据集。
值得注意的是,GeometricShapes 数据集默认包含的是网格而不是点云,通过 pos 和 face 属性来表示,分别保存了顶点及其三角连接的信息:
from torch_geometric.datasets import GeometricShapes
dataset = GeometricShapes(root='data/GeometricShapes')
print(dataset)
>>> GeometricShapes(40)
data = dataset[0]
print(data)
>>> Data(pos=[32, 3], face=[3, 30], y=[1])
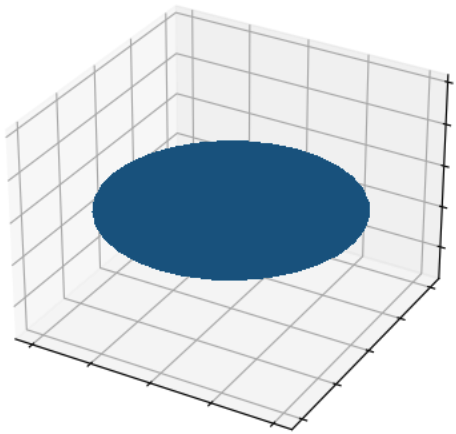
当可视化数据集中的第一个网格时,我们可以看到它代表一个圆:
由于我们对点云感兴趣,我们可以通过使用torch_geometric.transforms将我们的网格转换为点。
特别是,PyG提供了SamplePoints转换,它将根据网格面的面积均匀地采样固定数量的点。
我们可以通过简单地设置dataset.transform = SamplePoints(num=...)来将此转换添加到数据集中。
每次从数据集中访问一个示例时,都会调用转换过程,将我们的网格转换为点云。
请注意,采样点是随机的,因此每次访问时都会收到一个新的点云:
import torch_geometric.transforms as T
dataset.transform = T.SamplePoints(num=256)
data = dataset[0]
print(data)
>>> Data(pos=[256, 3], y=[1])
请注意,在我们的示例中,我们现在有256个点,并且存储在face中的三角形连接已被移除。
现在可视化这些点表明我们已经在初始网格的表面上正确采样了这些点:

最后,让我们将点云转换为图。
由于我们对学习局部几何结构感兴趣,我们希望以这样一种方式构建图,使得附近的点相互连接。
通常,这是通过\(k\)-最近邻搜索或通过球查询(连接所有在查询点一定半径内的点)来完成的。
PyG 提供了通过 KNNGraph 和 RadiusGraph 转换来生成此类图的工具。
from torch_geometric.transforms import SamplePoints, KNNGraph
dataset.transform = T.Compose([SamplePoints(num=256), KNNGraph(k=6)])
data = dataset[0]
print(data)
>>> Data(pos=[256, 3], edge_index=[2, 1536], y=[1])
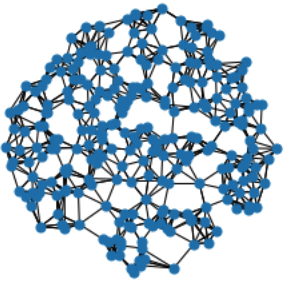
你可以看到data对象现在也包含一个edge_index表示,总共包含1536条边,每个256个点有6条边。
我们可以通过以下可视化确认我们的图看起来不错:
PointNet++ 实现
PointNet++ 是一项开创性的工作,提出了一种用于点云分类和分割的图神经网络架构。 PointNet++ 通过遵循简单的分组、邻域聚合和下采样方案来迭代处理点云:
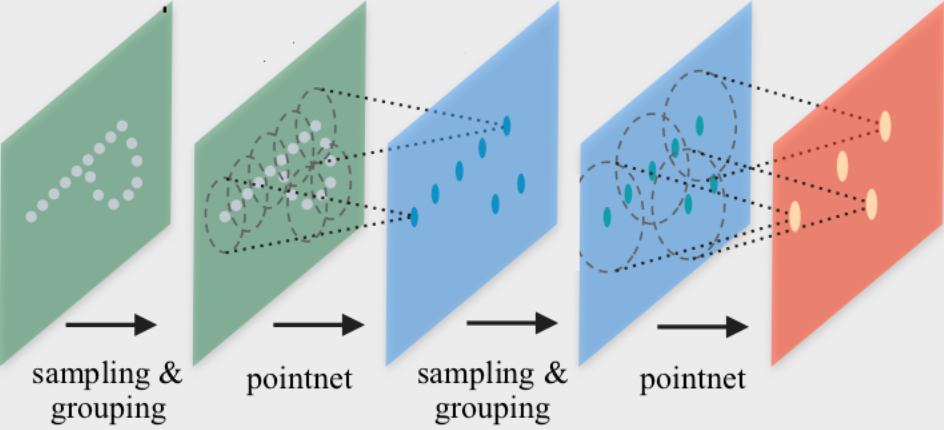
分组阶段构建了一个图,通过\(k\)-最近邻搜索或如上所述的球查询来实现。
邻域聚合阶段执行一个GNN层,对于每个点,从其直接邻居(由前一阶段构建的图给出)聚合信息。这使得PointNet++能够在不同尺度上捕捉局部上下文。
下采样阶段实现了一种适用于可能具有不同大小的点云的池化方案。 由于简单起见,我们现在将忽略这个阶段。 我们建议查看examples/pointnet2_classification.py以获取如何实现此步骤的指导。
邻居聚合
PointNet++ 层遵循一个简单的神经消息传递方案,该方案通过以下方式定义:
其中
\(\mathbf{h}_i^{(\ell)} \in \mathbb{R}^d\) 表示第 \(\ell\) 层中点 \(i\) 的隐藏特征,并且
\(\mathbf{p}_i \in \mathbf{R}^3$\) 表示点 \(i\) 的位置。
我们可以利用MessagePassing接口在PyG中从头实现这一层。
MessagePassing接口通过自动处理消息传播,帮助我们创建消息传递图神经网络。
在这里,我们只需要定义它的message()函数以及我们想要使用的聚合方案,例如,aggr="max"(参见这里的配套教程):
from torch import Tensor
from torch.nn import Sequential, Linear, ReLU
from torch_geometric.nn import MessagePassing
class PointNetLayer(MessagePassing):
def __init__(self, in_channels: int, out_channels: int):
# Message passing with "max" aggregation.
super().__init__(aggr='max')
# Initialization of the MLP:
# Here, the number of input features correspond to the hidden
# node dimensionality plus point dimensionality (=3).
self.mlp = Sequential(
Linear(in_channels + 3, out_channels),
ReLU(),
Linear(out_channels, out_channels),
)
def forward(self,
h: Tensor,
pos: Tensor,
edge_index: Tensor,
) -> Tensor:
# Start propagating messages.
return self.propagate(edge_index, h=h, pos=pos)
def message(self,
h_j: Tensor,
pos_j: Tensor,
pos_i: Tensor,
) -> Tensor:
# h_j: The features of neighbors as shape [num_edges, in_channels]
# pos_j: The position of neighbors as shape [num_edges, 3]
# pos_i: The central node position as shape [num_edges, 3]
edge_feat = torch.cat([h_j, pos_j - pos_i], dim=-1)
return self.mlp(edge_feat)
正如人们所见,在PyG中实现PointNet++层相当直接。
在__init__()函数中,我们首先定义了我们想要应用最大聚合,然后初始化一个MLP,该MLP负责将邻居的节点特征和源节点与目标节点之间的空间关系转换为(可训练的)消息。
在forward()函数中,我们可以开始基于edge_index进行消息传播,并传入创建消息所需的所有内容。
在message()函数中,我们现在可以通过*_j和*_i后缀分别访问邻居和中心节点信息,并为每条边返回一个消息。
网络架构
我们可以利用上面的PointNetLayer来定义我们的网络架构(或者直接使用其等效的torch_geometric.nn.conv.PointNetConv,它已经直接集成在PyG中)。
这样,我们的整体PointNet架构如下所示:
from torch_geometric.nn import global_max_pool
class PointNet(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = PointNetLayer(3, 32)
self.conv2 = PointNetLayer(32, 32)
self.classifier = Linear(32, dataset.num_classes)
def forward(self,
pos: Tensor,
edge_index: Tensor,
batch: Tensor,
) -> Tensor:
# Perform two-layers of message passing:
h = self.conv1(h=pos, pos=pos, edge_index=edge_index)
h = h.relu()
h = self.conv2(h=h, pos=pos, edge_index=edge_index)
h = h.relu()
# Global Pooling:
h = global_max_pool(h, batch) # [num_examples, hidden_channels]
# Classifier:
return self.classifier(h)
model = PointNet()
如果我们检查模型,我们可以看到所有内容都已正确初始化:
print(model)
>>> PointNet(
... (conv1): PointNetLayer()
... (conv2): PointNetLayer()
... (classifier): Linear(in_features=32, out_features=40, bias=True)
... )
在这里,我们通过继承torch.nn.Module来创建我们的网络架构,并在其构造函数中初始化两个 PointNetLayer 模块和一个最终的线性分类器。
在forward()方法中,我们应用了两个基于图的卷积算子,并通过ReLU非线性增强它们。
第一个算子接收3个输入特征(节点的位置)并将它们映射到32个输出特征。
之后,每个点都包含其2跳邻域的信息,并且应该已经能够区分简单的局部形状。
接下来,我们应用一个全局图读取函数,即global_max_pool(),该函数沿节点维度为每个示例取最大值。
为了将不同的节点映射到它们对应的示例,我们使用batch向量,该向量在使用小批量torch_geometric.loader.DataLoader时会自动创建以供使用。
最后,我们应用一个线性分类器将每个点云的全局32个特征映射到40个类别之一。
训练过程
我们现在准备编写两个简单的程序,分别在训练和测试数据集上训练和测试我们的模型。 如果你对PyTorch不陌生,这个方案对你来说应该很熟悉。 否则,PyTorch文档提供了一个关于如何在PyTorch中训练神经网络的良好介绍:
from torch_geometric.loader import DataLoader
train_dataset = GeometricShapes(root='data/GeometricShapes', train=True)
train_dataset.transform = T.Compose([SamplePoints(num=256), KNNGraph(k=6)])
test_dataset = GeometricShapes(root='data/GeometricShapes', train=False)
test_dataset.transform = T.Compose([SamplePoints(num=256), KNNGraph(k=6)])
train_loader = DataLoader(train_dataset, batch_size=10, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=10)
model = PointNet()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
total_loss = 0
for data in train_loader:
optimizer.zero_grad()
logits = model(data.pos, data.edge_index, data.batch)
loss = criterion(logits, data.y)
loss.backward()
optimizer.step()
total_loss += float(loss) * data.num_graphs
return total_loss / len(train_loader.dataset)
@torch.no_grad()
def test():
model.eval()
total_correct = 0
for data in test_loader:
logits = model(data.pos, data.edge_index, data.batch)
pred = logits.argmax(dim=-1)
total_correct += int((pred == data.y).sum())
return total_correct / len(test_loader.dataset)
for epoch in range(1, 51):
loss = train()
test_acc = test()
print(f'Epoch: {epoch:02d}, Loss: {loss:.4f}, Test Acc: {test_acc:.4f}')
使用此设置,即使每个类别仅训练一个示例,您也应该获得大约75%-80%的测试集准确率。