通过合并进行聚合#
空间数据通常比所需的更为详细。例如,您可能拥有关于次国家单位的数据,但您实际上对研究国家级别的模式更感兴趣。
在非空间环境中,当您需要数据的汇总统计时,可以使用groupby()函数聚合数据。但是对于空间数据,您有时还需要聚合几何特征。在GeoPandas库中,您可以使用dissolve()函数聚合几何特征。
dissolve() 可以被认为是做三件事情:
它将给定组内的所有几何体合并为一个单一的几何特征(使用
union_all()方法),并且它使用 groupby.aggregate 聚合一组中的所有数据行,且
它将这两个结果结合在一起。
dissolve() 示例#
以尼泊尔的行政区域为例。你有地区,它们较小,还有区域,它们较大。一组地区总是组成一个单独的区域。假设你对尼泊尔的区域感兴趣,但你只有尼泊尔的区级数据,如包含在geodatasets中的geoda.nepal数据集。你可以轻松地将其转换为区域级数据集。
首先,我们来看最简单的情况,您只想要区域形状和名称。
In [1]: import geodatasets
In [2]: nepal = geopandas.read_file(geodatasets.get_path('geoda.nepal'))
In [3]: nepal = nepal.rename(columns={"name_2": "zone"}) # rename to remember the column
In [4]: nepal[["zone", "geometry"]].head()
Out[4]:
zone geometry
0 Dhaualagiri POLYGON ((83.10834 28.6202, 83.1056 28.60976, ...
1 Dhaualagiri POLYGON ((83.99726 29.31675, 84 29.31576, 84 2...
2 Dhaualagiri POLYGON ((83.50688 28.79306, 83.51024 28.78809...
3 Dhaualagiri POLYGON ((83.70261 28.39837, 83.70435 28.39452...
4 Bagmati POLYGON ((85.52173 27.71822, 85.52359 27.71375...
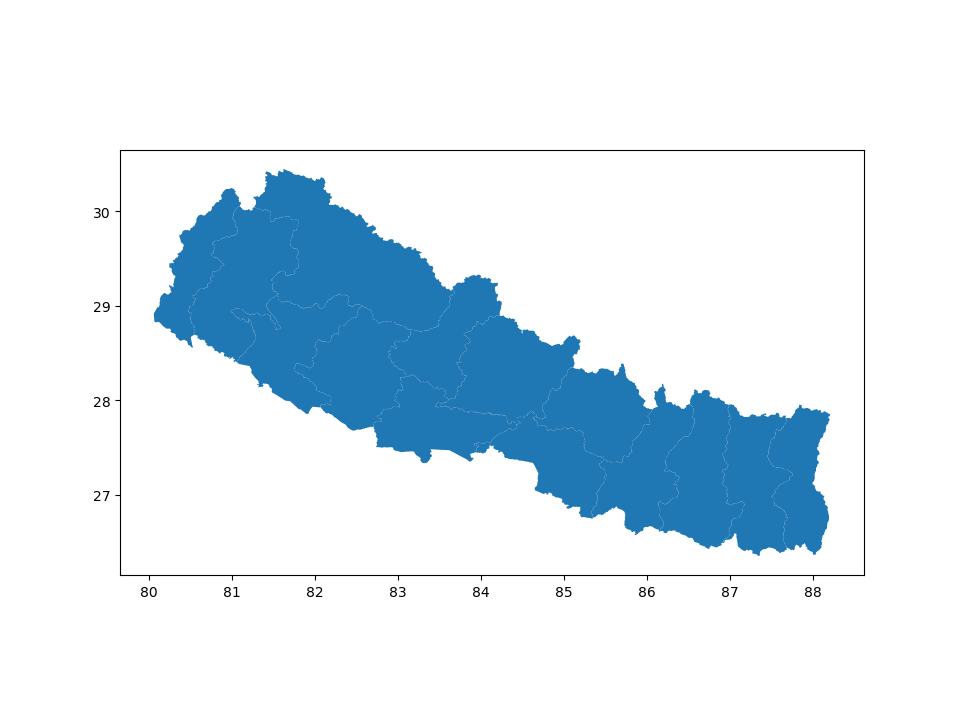
默认情况下, dissolve() 将会传递 'first' 给 groupby.aggregate。
In [5]: nepal_zone = nepal[['zone', 'geometry']]
In [6]: zones = nepal_zone.dissolve(by='zone')
In [7]: zones.plot();
In [8]: zones.head()
Out[8]:
geometry
zone
Bagmati POLYGON ((85.87653 27.61234, 85.87355 27.60861...
Bheri POLYGON ((81.75089 28.31038, 81.75562 28.3074,...
Dhaualagiri POLYGON ((83.70647 28.39278, 83.70721 28.38781...
Gandaki POLYGON ((84.49995 28.74099, 84.50443 28.7441,...
Janakpur POLYGON ((86.26166 26.91417, 86.2588 26.91144,...
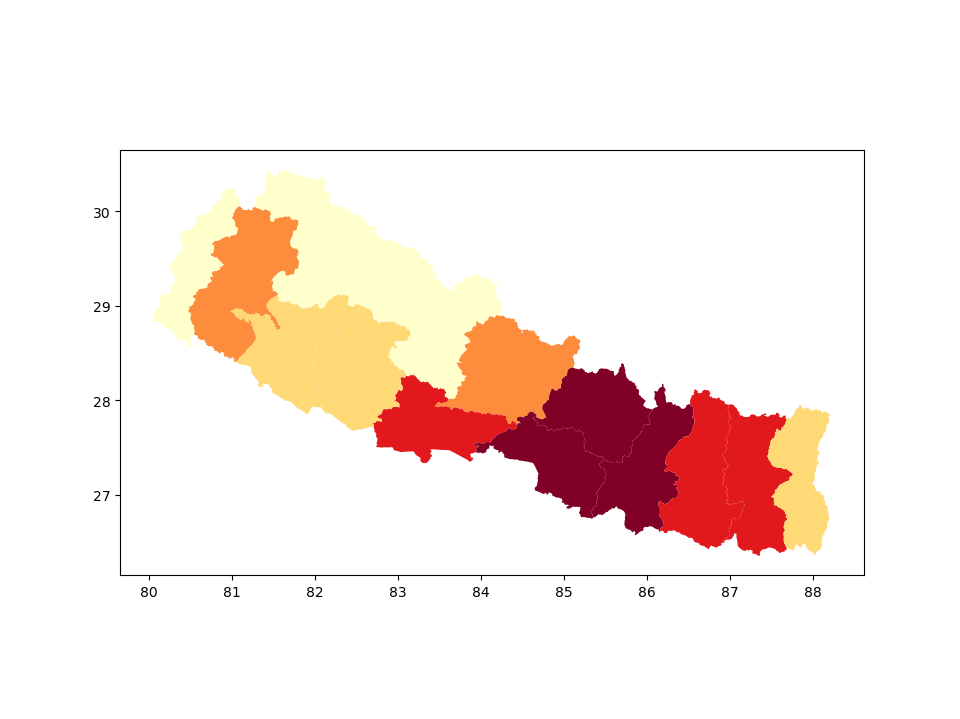
然而,如果您对聚合人口感兴趣,可以将不同的函数传递给 dissolve() 方法,以使用 aggfunc = 参数聚合人口:
In [9]: nepal_pop = nepal[['zone', 'geometry', 'population']]
In [10]: zones = nepal_pop.dissolve(by='zone', aggfunc='sum')
In [11]: zones.plot(column = 'population', scheme='quantiles', cmap='YlOrRd');
In [12]: zones.head()
Out[12]:
geometry population
zone
Bagmati POLYGON ((85.87653 27.61234, 85.87355 27.60861... 3750441
Bheri POLYGON ((81.75089 28.31038, 81.75562 28.3074,... 1463510
Dhaualagiri POLYGON ((83.70647 28.39278, 83.70721 28.38781... 516905
Gandaki POLYGON ((84.49995 28.74099, 84.50443 28.7441,... 1530310
Janakpur POLYGON ((86.26166 26.91417, 86.2588 26.91144,... 2818356
合并参数#
aggfunc = 参数默认值为 'first',这意味着在溶解过程中找到的第一行属性值将被分配到结果的溶解地理数据框中。 但是,它还接受其他由 pandas.groupby 允许的汇总统计选项,包括:
‘first’
‘最后’
‘最小值’
‘最大值’
‘和’
‘平均值’
‘中位数’
函数
字符串函数名称
函数和/或函数名称的列表,例如 [np.sum, ‘mean’]
轴标签的字典 -> 函数、函数名称或此类的列表。
例如,要获取每个大陆上的国家数量,以及每个大陆上最大和最小国家的人口,可以使用 'count' 聚合 'name' 列,使用 'min' 和 'max' 聚合 'pop_est' 列:
In [13]: zones = nepal.dissolve(
....: by="zone",
....: aggfunc={
....: "district": "count",
....: "population": ["min", "max"],
....: },
....: )
....: zones.head()
....:
Out[13]:
geometry ... (population, max)
zone ...
Bagmati POLYGON ((85.87653 27.61234, 85.87355 27.60861... ... 1688131
Bheri POLYGON ((81.75089 28.31038, 81.75562 28.3074,... ... 422812
Dhaualagiri POLYGON ((83.70647 28.39278, 83.70721 28.38781... ... 250065
Gandaki POLYGON ((84.49995 28.74099, 84.50443 28.7441,... ... 480851
Janakpur POLYGON ((86.26166 26.91417, 86.2588 26.91144,... ... 765959
[5 rows x 4 columns]