
生存分析简介¶
应用¶
传统上,生存分析被开发用来衡量个体的寿命。 精算师或健康专业人士会问这样的问题 “这个群体的寿命有多长?”,并使用生存分析来回答。 例如,群体可能是一个国家的人口(对于精算师), 或一个被疾病困扰的群体(在医疗专业人士的情况下)。 传统上,这是一个有点病态的主题。
但生存分析不仅可以应用于出生和死亡,还可以应用于任何持续时间。医疗专业人员可能对两次分娩之间的时间感兴趣,在这种情况下,出生是指生孩子的过程,而死亡则是指再次怀孕!(显然,我们对出生和死亡的定义比较宽松)另一个例子是用户订阅服务:出生是指用户加入服务,而死亡是指用户离开服务。
审查¶
当您想要对持续时间进行推断时,可能并非所有的死亡事件都已经发生。例如,医疗专业人员不会等待研究中的每个人50年后去世才开始调查——他或她感兴趣的是在仅仅几年或几个月后做出决策。
在人口中未经历死亡事件的个体被标记为右删失,即由于某些外部情况,我们未能(或无法)观察到他们剩余的生命历程。我们关于这些个体的所有信息都是他们当前的生存时间(这自然少于他们的实际生存时间)。
注意
还有左截尾和区间截尾,这些将在后面进一步展开。
数据分析师常犯的一个错误是选择忽略右删失的个体。我们接下来将看到为什么这是一个错误。
考虑一个情况,其中人口实际上由两个子群体组成,\(A\) 和 \(B\)。群体 \(A\) 的寿命非常短,平均为2个月,而群体 \(B\) 的寿命则长得多,平均为12个月。我们事先并不知道这种区别。在 \(t=10\) 时,我们希望调查整个群体的平均寿命。
在下图中,红线表示已观察到死亡事件的个体的寿命,蓝线表示右删失个体的寿命(未观察到死亡)。如果我们被要求估计我们人口的平均寿命,并且我们天真地决定不包括右删失的个体,显然我们会严重低估真实的平均寿命。
from lifelines.plotting import plot_lifetimes
import numpy as np
from numpy.random import uniform, exponential
N = 25
CURRENT_TIME = 10
actual_lifetimes = np.array([
exponential(12) if (uniform() < 0.5) else exponential(2) for i in range(N)
])
observed_lifetimes = np.minimum(actual_lifetimes, CURRENT_TIME)
death_observed = actual_lifetimes < CURRENT_TIME
ax = plot_lifetimes(observed_lifetimes, event_observed=death_observed)
ax.set_xlim(0, 25)
ax.vlines(10, 0, 30, lw=2, linestyles='--')
ax.set_xlabel("time")
ax.set_title("Births and deaths of our population, at $t=10$")
print("Observed lifetimes at time %d:\n" % (CURRENT_TIME), observed_lifetimes)
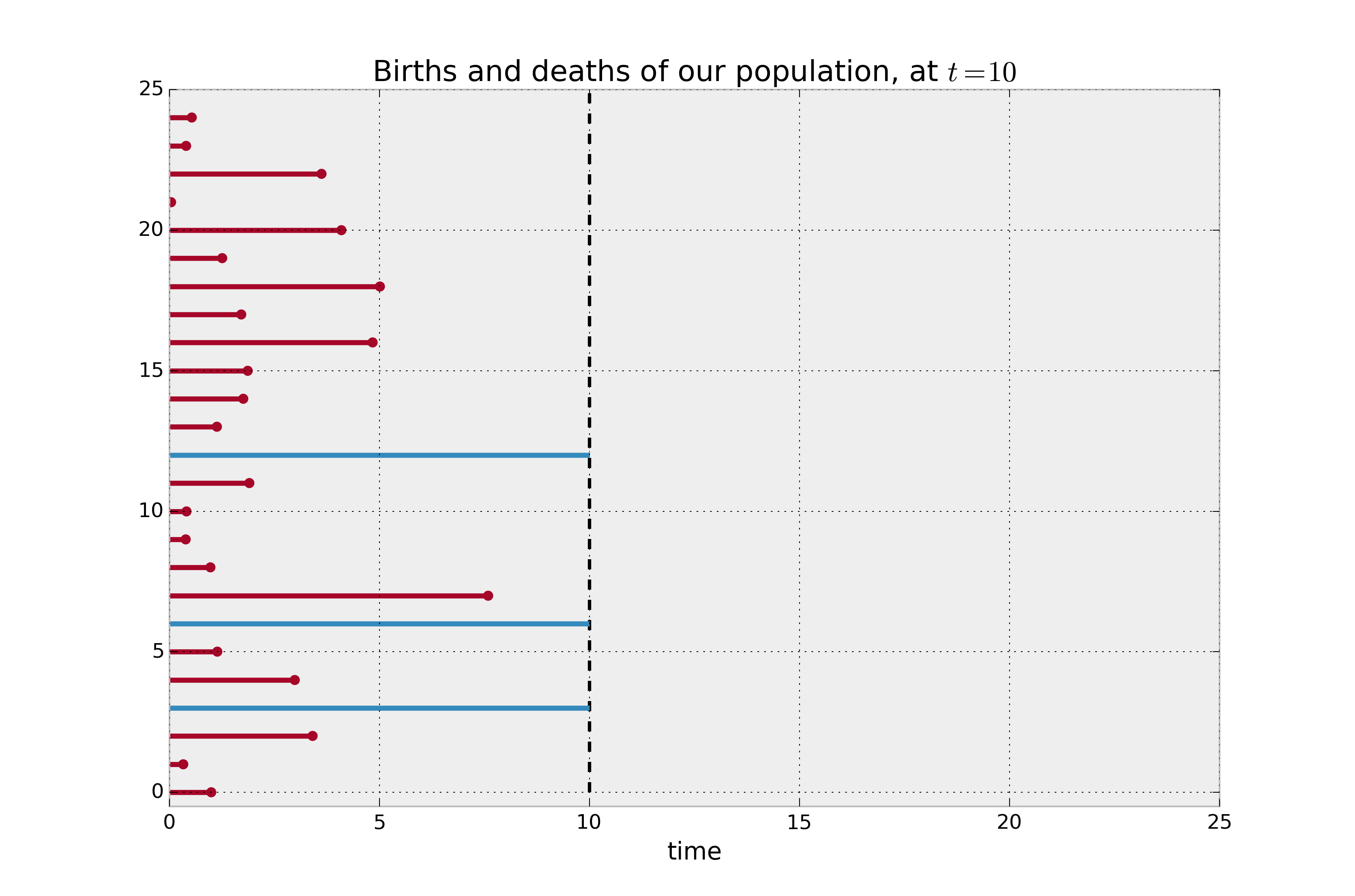
个体的生存时间示例。我们只观察到时间10,但蓝色的个体尚未死亡(即它们被删失)。¶
Observed lifetimes at time 10:
[10. 1.1 8. 10. 3.43 0.63 6.28 1.03 2.37 6.17 10.
0.21 2.71 1.25 10. 3.4 0.62 1.94 0.22 7.43 6.16 10.
9.41 10. 10.]
此外,如果我们简单地取所有寿命的平均值,包括右删失实例的当前寿命,我们仍然会低估真实的平均寿命。下面我们绘制了所有实例的实际寿命(回想一下,在\(t=10\)时我们看不到这些信息)。
ax = plot_lifetimes(actual_lifetimes, event_observed=death_observed)
ax.vlines(10, 0, 30, lw=2, linestyles='--')
ax.set_xlim(0, 25)
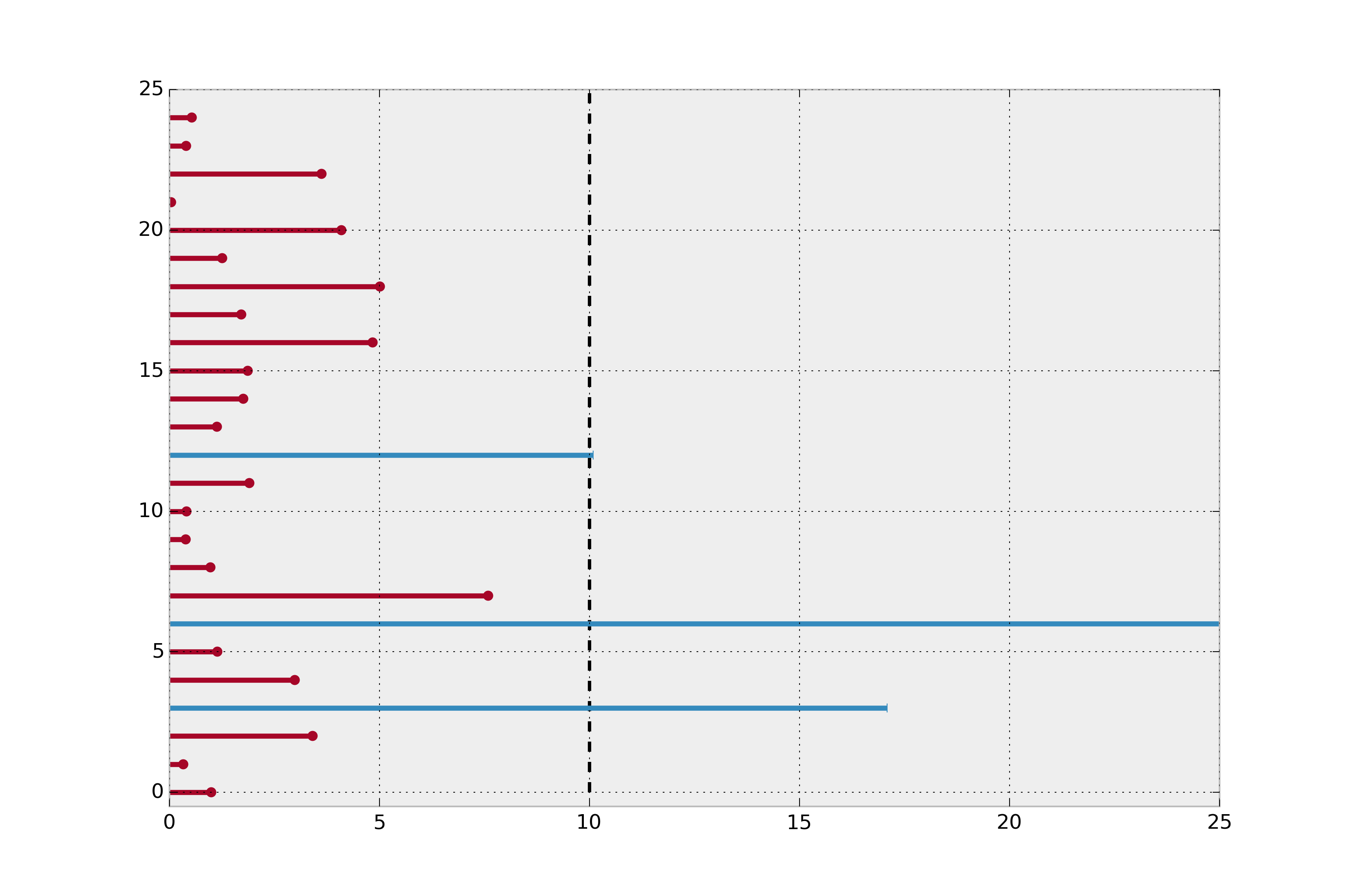
揭示个体的实际寿命。¶
生存分析最初是为了解决这类问题而开发的,即当我们的数据是右删失时进行处理。然而,即使在所有事件都被观察到的情况下,即没有删失,生存分析仍然是理解持续时间和比率的一个非常有用的工具。
观察不一定总是从零开始。在上面的例子中这样做只是为了理解。考虑一个例子,顾客进入商店是一个出生事件:顾客可以在任何时间进入,不一定在时间零。在生存分析中,持续时间是相对的:个体可能在不同的时间开始。 (我们实际上只需要观察的持续时间,而不一定需要开始和结束时间。)
接下来我们介绍生存分析中的三个基本对象,生存函数、风险函数和累积风险函数。
生存函数¶
让\(T\)表示从研究群体中抽取的(可能是无限的,但总是非负的)随机寿命。例如,一对夫妇结婚的时间。或者用户进入网页所需的时间(如果他们从未进入,则为无限时间)。群体的生存函数 - \(S(t)\) - 定义为
简单来说,生存函数定义了在时间\(t\)时死亡事件尚未发生的概率,或者说,存活超过时间\(t\)的概率。注意生存函数的以下属性:
\(0 \le S(t) \le 1\)
\(F_T(t) = 1 - S(t)\), 其中 \(F_T(t)\) 是 \(T\) 的累积分布函数,这意味着
\(S(t)\) 是 \(t\) 的非增函数。
这是一个生存函数的示例:
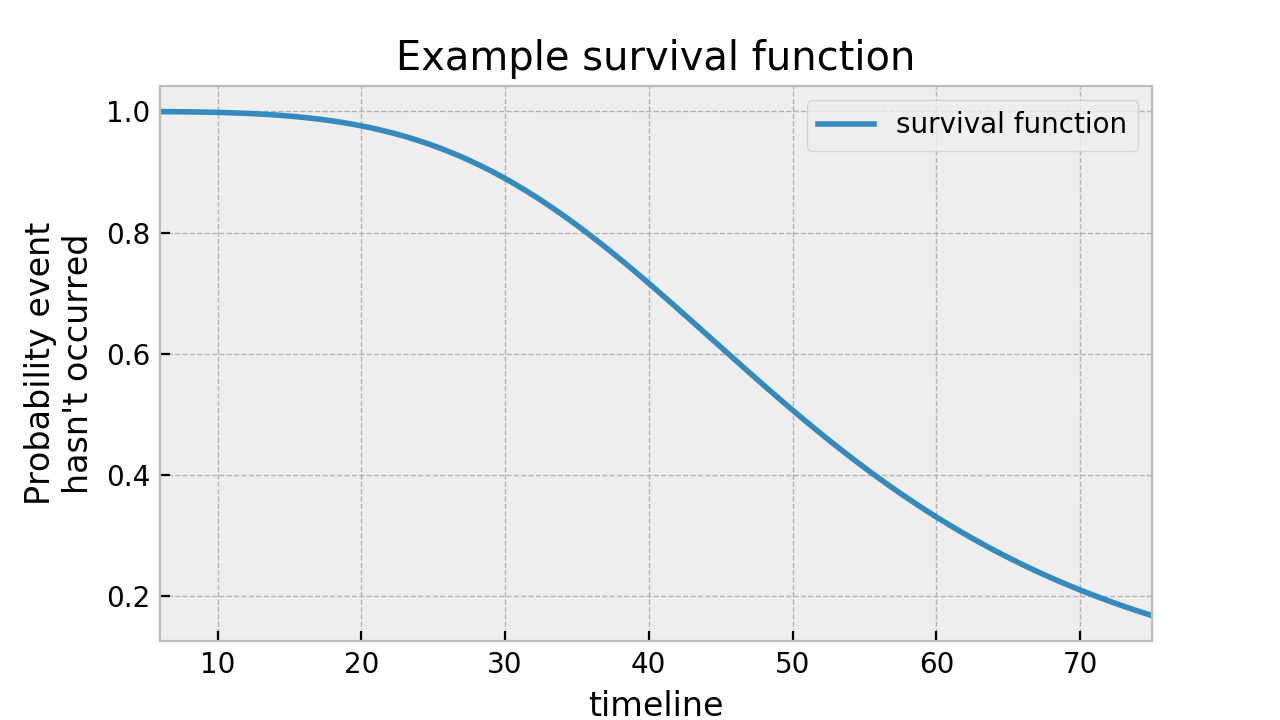
从这张图中可以看出,在时间40时,大约75%的人口仍然存活。
风险函数¶
我们还对在时间\(t\)发生死亡事件的概率感兴趣,前提是死亡事件尚未发生。数学上,这表示为:
随着\(\delta t\)的缩小,这个量趋近于0,因此我们将其除以间隔\(\delta t\)(就像我们在微积分中可能做的那样)。这定义了时间\(t\)处的风险函数\(h(t)\):
可以证明这等于:
并解这个微分方程(很酷,它是一个微分方程!),我们得到:
积分有一个更常见的名称:累积风险函数,表示为\(H(t)\)。我们可以将上述内容重写为:
因此,下图分别表示上图中生存函数的危险和累积危险。
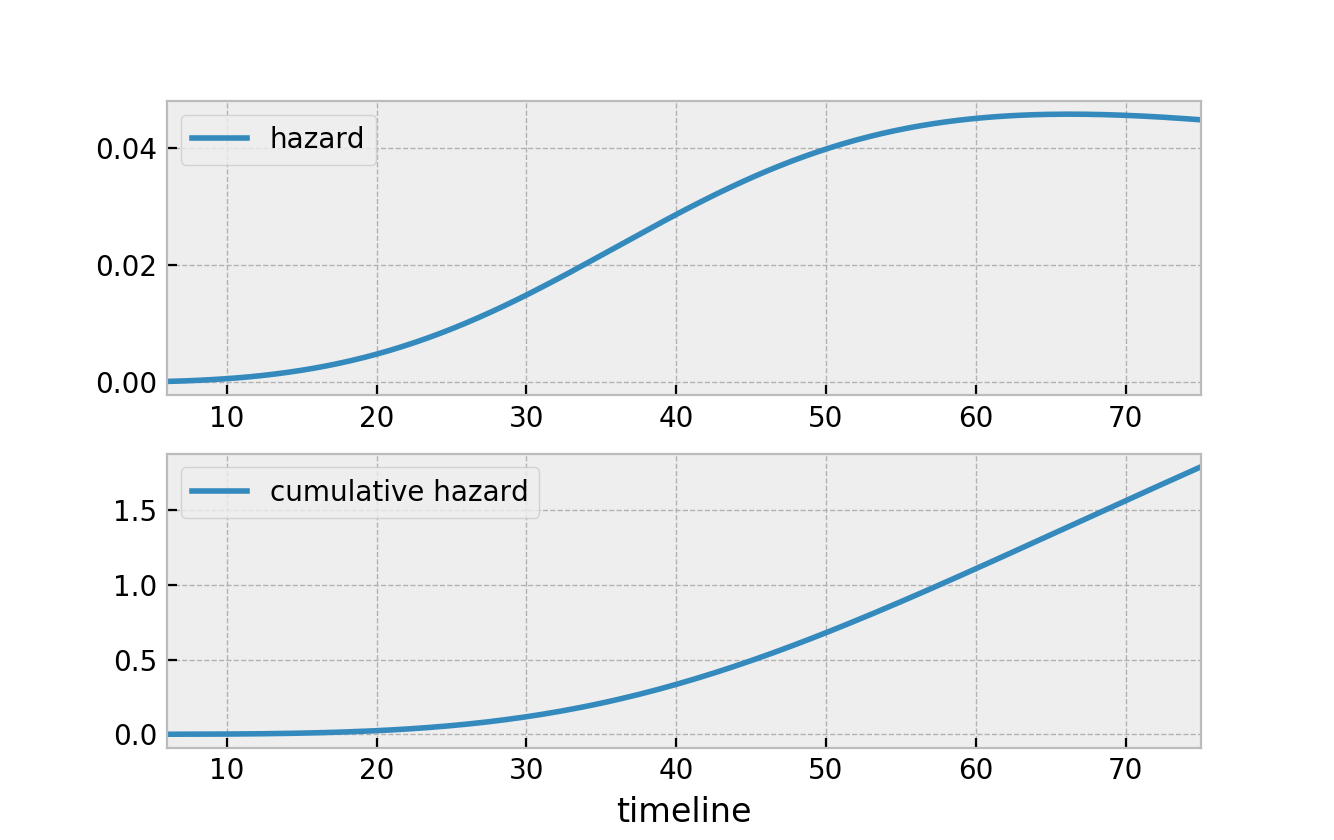
我喜欢上述关系的原因是它定义了所有生存函数。注意,我们现在可以谈论生存函数\(S(t)\)、风险函数\(h(t)\)或累积风险函数\(H(t)\),并且我们可以很容易地在它们之间进行转换。下面是这些量之间所有关系的图形表示。

生存分析中使用的数学实体及其之间的转换图。 别担心:lifelines 会为你完成这一切。¶
下一步¶
当然,我们无法观察到人口的真实生存函数或风险。我们必须使用观察到的数据来估计它。有许多方法可以估计生存函数和风险函数,这使我们进入了使用lifelines进行估计。