
Apache Airflow¶
Apache Airflow 是一个流行的开源工作流管理平台。它是编排和执行由Kedro创建的管道的合适引擎,因为Airflow中的工作流被建模和组织为DAGs。
简介与策略¶
在Apache Airflow上部署Kedro管道的通用策略是将每个Kedro节点作为Airflow任务运行,同时将整个管道转换为一个Airflow DAG。这种方法体现了在分布式环境中运行Kedro的原则。
每个节点将在新的Kedro会话中执行,这意味着MemoryDataset不能作为节点中间结果的存储。相反,所有数据集必须在DataCatalog中注册并存储在持久化存储中。这种方法使得节点能够访问前驱节点的结果。
本指南提供了在不同Airflow平台上运行Kedro管道的操作说明。您可以通过点击下方链接跳转到具体章节,了解如何在以下平台运行Kedro管道:
如何在Apache Airflow上使用Astronomer运行Kedro管道¶
本教程将展示如何使用Astro CLI(由Astronomer开发的命令行工具,可简化本地Airflow项目创建过程)在Apache Airflow上部署示例项目Spaceflights Kedro project。您将首先在本地部署,然后迁移至Astro云端环境。
Astronomer是一个托管的Airflow平台,允许用户在生产环境中快速部署和运行Airflow集群。此外,它还提供了一套工具,帮助用户以最简单的方式在本地开始使用Airflow。
先决条件¶
要学习本教程,请确保您具备以下条件:
已安装Astro CLI
容器服务如 Docker Desktop (v18.09 或更高版本)
kedro>=0.19已安装kedro-airflow>=0.8已安装。我们将使用此插件将Kedro流水线转换为Airflow DAG。
创建、准备并打包示例Kedro项目¶
在本节中,您将创建一个新的Kedro项目,该项目配备了一个示例管道,旨在解决典型的数据科学任务:预测太空飞行价格。您需要自定义此项目以确保与Airflow兼容,包括通过丰富Kedro DataCatalog来存储原先仅存在于内存中的数据集,并通过自定义设置简化日志记录。完成这些修改后,您将打包项目以便安装到Airflow Docker容器中,并生成一个与Kedro管道相对应的Airflow DAG。
要创建一个新的Kedro项目,选择
example=yes选项以包含示例代码。此外,如需实现自定义日志记录,请选择tools=log。使用默认项目名称继续,但也可以根据需要添加其他工具:kedro new --example=yes --name=new-kedro-project --tools=log
导航到您的项目目录,为Airflow特定配置创建一个新的
conf/airflow目录,并将catalog.yml文件从conf/base复制到conf/airflow。此设置允许您自定义DataCatalog以与Airflow一起使用:cd new-kedro-project mkdir conf/airflow cp conf/base/catalog.yml conf/airflow/catalog.yml
打开
conf/airflow/catalog.yml查看项目中使用的数据集列表。请注意,额外的中间数据集(X_train,X_test,y_train,y_test)仅存储在内存中。您可以在/src/new_kedro_project/pipelines/data_science/pipeline.py下的管道描述中找到这些数据集。为了确保这些数据集在Airflow的不同任务中得以保留并可访问,我们需要将它们包含在我们的DataCatalog中。为了避免为每个数据集重复类似的代码,您可以使用Dataset Factories,这是一种特殊语法,允许定义一个通配模式来覆盖默认的MemoryDataset创建。将此代码添加到文件末尾:
"{base_dataset}":
type: pandas.CSVDataset
filepath: data/02_intermediate/{base_dataset}.csv
在此示例中,我们假设所有Airflow任务共享一个磁盘,但对于分布式环境,您需要使用非本地文件路径。
从kedro-airflow 0.9.0版本开始,您可以选择采用不同的策略,而无需遵循步骤2-3:将使用中间MemoryDataset的节点分组为更大的任务。这种方法允许在单个任务内进行中间数据处理,无需在节点间传输数据。您可以通过在第6步运行kedro airflow create时添加--group-in-memory标志来实现这一点。
打开
conf/logging.yml并修改文件末尾的root: handlers部分为[console]。默认情况下,Kedro 使用 Rich 库通过复杂格式化来增强日志输出。但包括 Airflow 在内的某些部署系统与 Rich 兼容性不佳,因此我们将日志调整为更简单的控制台版本。有关 Kedro 日志记录的更多信息,可参阅 Kedro 文档。
root:
handlers: [console]
将Kedro流水线打包为Python包,以便稍后可以将其安装到Airflow容器中:
kedro package
此步骤应生成一个名为new_kedro_project-0.1-py3-none-any.whl的wheel文件,位于dist/目录下。
使用
kedro airflow将Kedro管道转换为Airflow DAG
kedro airflow create --target-dir=dags/ --env=airflow
此步骤应生成一个名为new_kedro_project_airflow_dag.py的.py文件,位于dags/目录下。
使用Astro CLI进行部署流程¶
在本节中,您将首先使用Astro设置一个新的空白Airflow项目,然后从前一节的Kedro项目中复制准备好的文件。接下来,您需要自定义Dockerfile以增强日志功能并管理Kedro包的安装。最后,您将能够运行和探索Airflow集群。
要完成本部分内容,你需要同时安装Astro CLI和Docker Desktop。
使用Astro初始化一个Airflow项目,在Kedro项目外的新文件夹中。我们将其命名为
kedro-airflow-spaceflightscd .. mkdir kedro-airflow-spaceflights cd kedro-airflow-spaceflights astro dev init
文件夹
kedro-airflow-spaceflights将在 Airflow 容器内执行。要在其中运行 Kedro 项目,您需要将前一部分的几个项目复制到其中:
来自步骤1的
/data文件夹,包含我们管道的示例输入数据集。该文件夹还将存储输出结果。来自步骤2-4的
/conf文件夹,包含我们的DataCatalog、参数和自定义日志文件。这些文件将在Kedro于Airflow容器中执行时使用。第5步中的
.whl文件,您需要将其安装在Airflow Docker容器中以逐个执行我们的项目节点。第6步中用于在Airflow集群部署的Airflow DAG。
cd .. cp -r new-kedro-project/data kedro-airflow-spaceflights/data cp -r new-kedro-project/conf kedro-airflow-spaceflights/conf mkdir -p kedro-airflow-spaceflights/dist/ cp new-kedro-project/dist/new_kedro_project-0.1-py3-none-any.whl kedro-airflow-spaceflights/dist/ cp new-kedro-project/dags/new_kedro_project_airflow_dag.py kedro-airflow-spaceflights/dags/
如果你的项目需要频繁更新、重新创建DAG和重新打包,可以完全将new-kedro-project复制到kedro-airflow-spaceflights中。这种方法允许你在单个文件夹中同时处理kedro和astro项目,无需为每个开发迭代复制kedro文件。但请注意,两个项目将共享一些公共文件,如requirements.txt、README.md和.gitignore。
在
kedro-airflow-spaceflights文件夹中的Dockerfile添加几行代码,将环境变量KEDRO_LOGGING_CONFIG设置为指向conf/logging.yml以启用Kedro中的自定义日志记录(注意从Kedro 0.19.6开始,此步骤不再需要,因为Kedro默认使用conf/logging.yml文件),并将我们准备好的Kedro项目的.whl文件安装到Airflow容器中:
ENV KEDRO_LOGGING_CONFIG="conf/logging.yml" # This line is not needed from Kedro 0.19.6
RUN pip install --user dist/new_kedro_project-0.1-py3-none-any.whl
导航到
kedro-airflow-spaceflights文件夹并使用 Astronomer 启动本地 Airflow 集群
cd kedro-airflow-spaceflights
astro dev start
访问Airflow Webserver UI的默认地址http://localhost:8080,使用默认登录凭证:用户名和密码均为
admin。在那里,您将看到所有DAG的列表。导航至new-kedro-projectDAG,然后点击Trigger DAG播放按钮以启动它。随后您可以观察项目各步骤的成功运行情况:
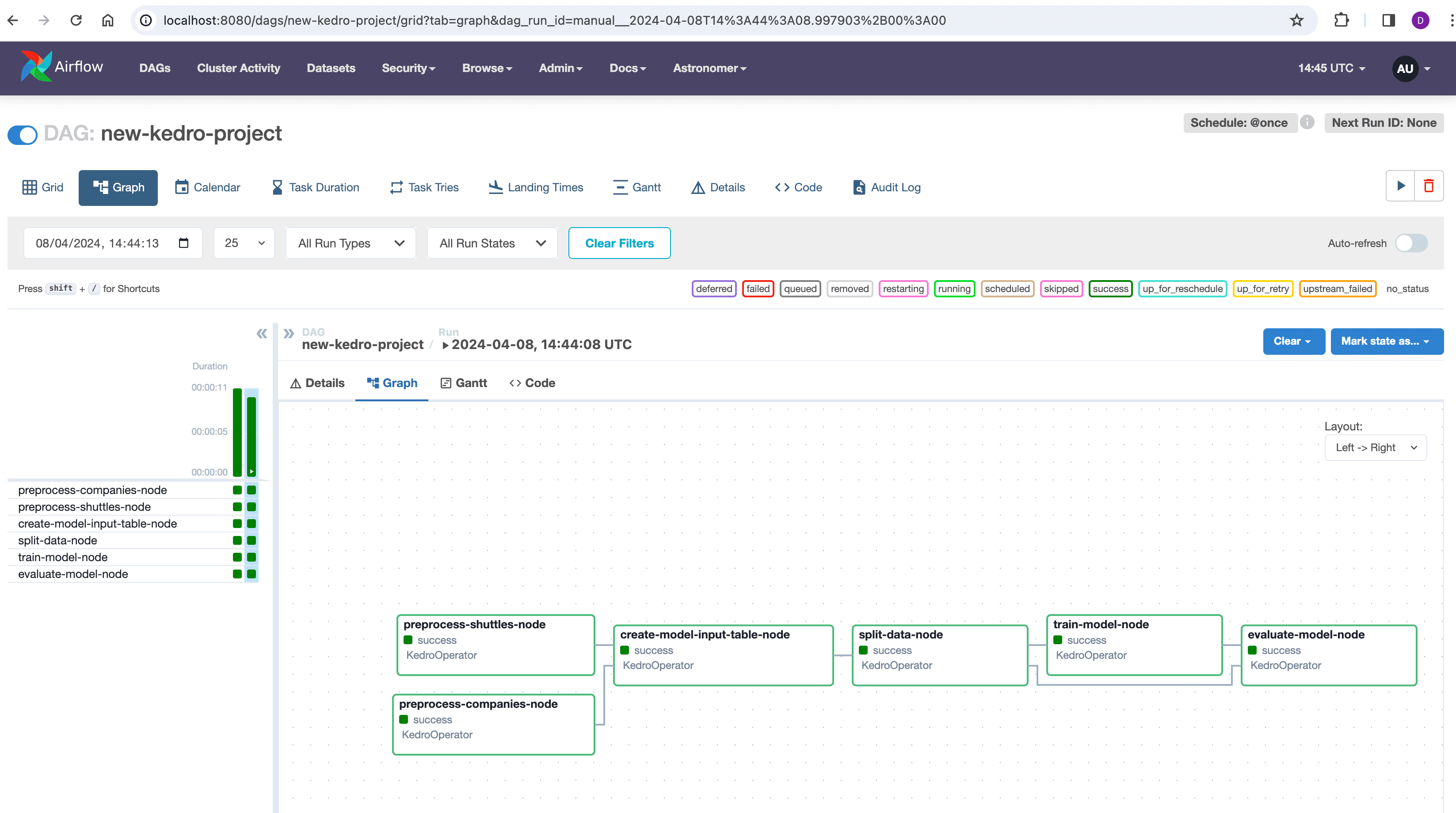
Kedro项目是在Airflow Docker容器内运行的,结果也存储在其中。要将这些结果复制到主机上,首先通过列出相关Docker容器来识别它们:
docker ps
选择充当调度程序的容器并记下其ID。然后,使用以下命令复制结果,将d36ef786892a替换为实际的容器ID:
docker cp d36ef786892a:/usr/local/airflow/data/ ./data/
要停止Astro Airflow环境,可以使用以下命令:
astro dev stop
部署到Astro云端¶
您可以按照以下步骤,轻松在Astro Cloud(由Astronomer提供的云基础设施)上部署和运行您的项目:
登录您在Astronomer门户上的账户,如果还没有部署的话请新建一个:

使用Astro CLI登录您的Astro Cloud账户:
astro auth
您将被重定向至浏览器输入登录凭据。成功登录表示您的终端现已关联至Astro Cloud账户:
要将本地项目部署到云端,请导航至
kedro-airflow-spaceflights文件夹并运行:
astro deploy
在部署过程结束时,将提供一个链接。使用此链接在云端管理和监控您的项目:
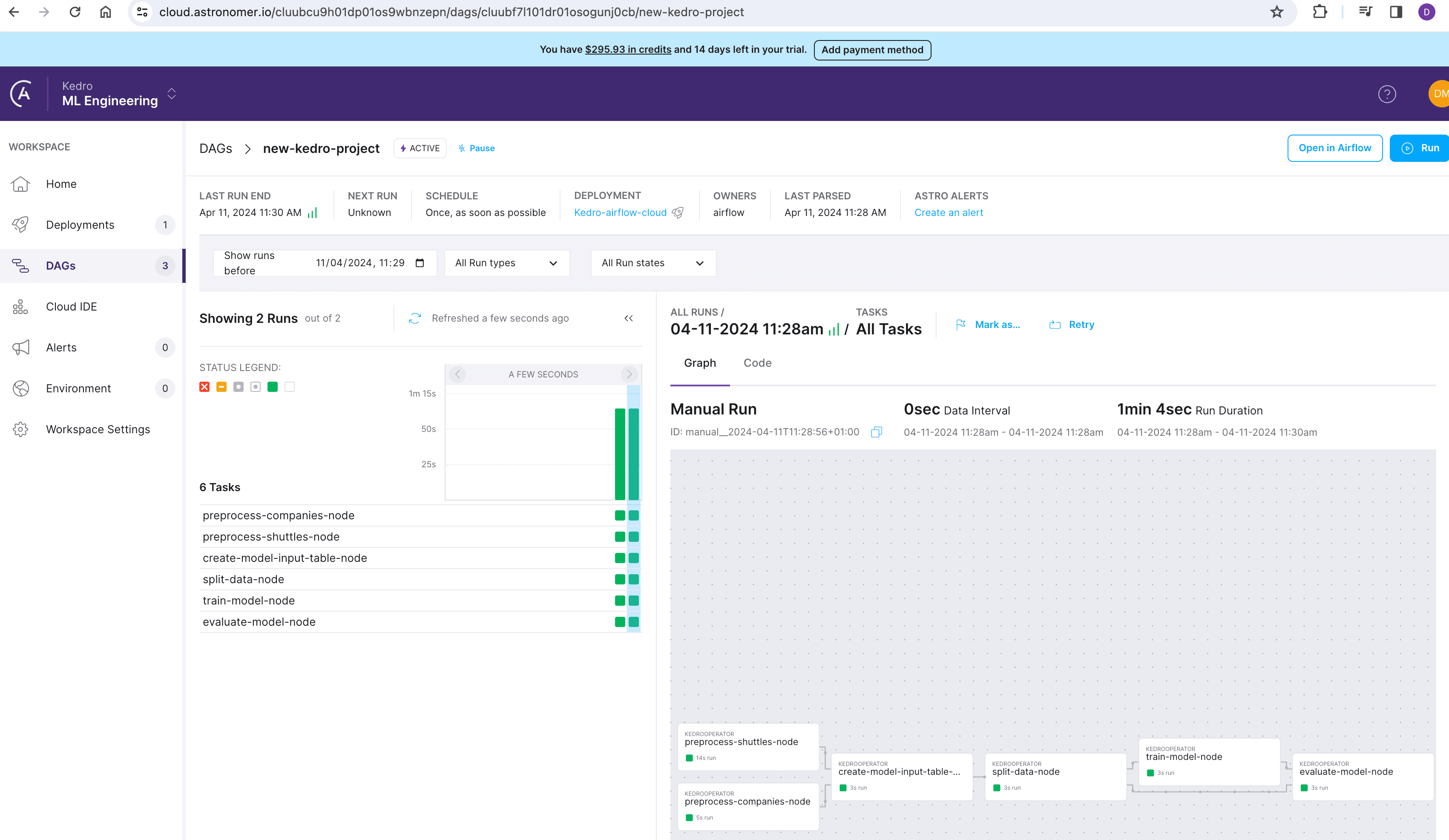
如何在亚马逊AWS托管的Apache Airflow工作流(MWAA)上运行Kedro管道¶
Kedro项目准备¶
MWAA(即Apache Airflow托管工作流)是AWS提供的一项服务,可简化在云端设置、运行和扩展Apache Airflow的过程。将Kedro管道部署到MWAA与Astronomer类似,但存在一些关键差异:您需要将项目数据存储在AWS S3存储桶中,并对DataCatalog进行必要的修改。此外,您还必须配置如何上传Kedro配置、安装Kedro软件包以及设置必要的环境变量。
完成创建、准备和打包示例Kedro项目部分中的步骤1-4。
您的项目数据不应存放在Airflow容器的工作目录中。相反,创建一个S3存储桶并将数据文件夹从new-kedro-project文件夹上传至您的S3存储桶。
修改
DataCatalog以引用S3存储桶中的数据,通过更新文件路径并在new-kedro-project/conf/airflow/catalog.yml中为每个数据集添加凭据行。如下所示,将S3前缀添加到文件路径中:
companies:
type: pandas.CSVDataset
filepath: s3://<your_S3_bucket>/data/01_raw/companies.csv
credentials: dev_s3
设置AWS凭证以提供对S3存储桶的读写访问权限。使用您的AWS_ACCESS_KEY_ID和AWS_SECRET_ACCESS_KEY更新
new-kedro-project/conf/local/credentials.yml,并将其复制到new-kedro-project/conf/airflow/文件夹中:
dev_s3:
client_kwargs:
aws_access_key_id: *********************
aws_secret_access_key: ******************************************
在
new-kedro-project中将s3fs添加到项目的requirements.txt中,以便与AWS S3进行通信。某些库可能会在Airflow环境中引起依赖冲突,因此请确保最小化需求列表并避免使用kedro-viz和pytest。
s3fs
按照创建、准备和打包示例Kedro项目部分中的步骤5-6操作,打包您的Kedro项目并生成Airflow DAG。
更新位于
dags/文件夹中的DAG文件new_kedro_project_airflow_dag.py,在Kedro操作器执行函数中的KedroSession.create()参数里添加conf_source="plugins/conf-new_kedro_project.tar.gz"。这个修改是必要的,因为你的Kedro配置归档文件将存储在plugins/文件夹中,而不是根目录:
def execute(self, context):
configure_project(self.package_name)
with KedroSession.create(project_path=self.project_path,
env=self.env, conf_source="plugins/conf-new_kedro_project.tar.gz") as session:
session.run(self.pipeline_name, node_names=[self.node_name])
在MWAA上部署¶
归档以下三个文件:
new_kedro_project-0.1-py3-none-any.whl和conf-new_kedro_project.tar.gz(位于new-kedro-project/dist目录下),以及logging.yml(位于new-kedro-project/conf/目录下),将它们打包成名为plugins.zip的文件并上传至s3://your_S3_bucket。
zip -j plugins.zip dist/new_kedro_project-0.1-py3-none-any.whl dist/conf-new_kedro_project.tar.gz conf/logging.yml
该归档文件稍后将被解压到Airflow容器工作目录中的/plugins文件夹。
创建一个新的
requirements.txt文件,添加你的Kedro项目将在Airflow容器中解压的路径,并将requirements.txt上传到s3://your_S3_bucket:
./plugins/new_kedro_project-0.1-py3-none-any.whl
容器初始化期间将安装来自 requirements.txt 的库。
将
new_kedro_project_airflow_dag.py从new-kedro-project/dags上传至s3://your_S3_bucket/dags。创建一个空的
startup.sh文件用于容器启动命令。为自定义Kedro日志设置环境变量:
export KEDRO_LOGGING_CONFIG="plugins/logging.yml"
使用以下设置新建一个AWS MWAA环境:
S3 Bucket:
s3://your_S3_bucket
DAGs folder
s3://your_S3_bucket/dags
Plugins file - optional
s3://your_S3_bucket/plugins.zip
Requirements file - optional
s3://your_S3_bucket/requrements.txt
Startup script file - optional
s3://your_S3_bucket/startup.sh
在下一页,如果您想从互联网访问Airflow UI,请在Web server access部分设置Public network (Internet accessible)选项。在后续页面继续使用默认选项。
环境创建完成后,使用
Open Airflow UI按钮访问标准Airflow界面,您可以在其中管理DAG。
如何在Apache Airflow上使用Kubernetes集群运行Kedro管道¶
如果你想在Airflow上使用Kubernetes集群在隔离环境中执行DAG,可以结合使用kedro-airflow和kedro-docker插件。
将您的Kedro项目打包为Docker容器 使用
kedro docker init和kedro docker build命令将您的Kedro项目容器化。将Docker镜像推送至容器注册表 将构建好的Docker镜像上传至云端容器注册表,例如AWS ECR、Google Container Registry或Docker Hub。
生成Airflow DAG 运行以下命令来生成Airflow DAG:
kedro airflow create
这将默认创建一个包含
KedroOperator()的DAG文件。修改DAG以使用
KubernetesPodOperator为了在每个隔离的Kubernetes pod中执行Kedro节点,将KedroOperator()替换为KubernetesPodOperator(),如下例所示:from airflow.providers.cncf.kubernetes.operators.pod import KubernetesPodOperator KubernetesPodOperator( task_id=node_name, name=node_name, namespace=NAMESPACE, image=DOCKER_IMAGE, cmds=["kedro"], arguments=["run", f"--nodes={node_name}"], get_logs=True, is_delete_operator_pod=True, # 执行后清理 in_cluster=False, # 如果Airflow运行在Kubernetes集群内部则设为True do_xcom_push=False, image_pull_policy="Always", # 如果Airflow运行在Kubernetes集群外部,请取消以下行的注释 # cluster_context="k3d-your-cluster", # 指定kubeconfig中的Kubernetes上下文 # config_file="~/.kube/config", # kubeconfig文件路径 )
在单个容器中运行多个节点¶
默认情况下,此方法会在独立的Docker容器中运行每个节点。但为了减少计算开销,您可以选择在同一容器内同时运行多个节点。如果选择此方式,则必须相应修改DAG以调整任务依赖关系和执行顺序。
例如,在spaceflights-pandas教程中,如果你想同时执行前两个节点,你的DAG可能看起来像这样:
from airflow.providers.cncf.kubernetes.operators.pod import KubernetesPodOperator
with DAG(...) as dag:
tasks = {
"preprocess-companies-and-shuttles": KubernetesPodOperator(
task_id="preprocess-companies-and-shuttles",
name="preprocess-companies-and-shuttles",
namespace=NAMESPACE,
image=DOCKER_IMAGE,
cmds=["kedro"],
arguments=["run", "--nodes=preprocess-companies-node,preprocess-shuttles-node"],
...
),
"create-model-input-table-node": KubernetesPodOperator(...),
...
}
tasks["preprocess-companies-and-shuttles"] >> tasks["create-model-input-table-node"]
tasks["create-model-input-table-node"] >> tasks["split-data-node"]
...
在本示例中,我们修改了由kedro airflow create命令生成的原始DAG,将KedroOperator()替换为KubernetesPodOperator()。此外,我们将前两个任务合并为一个名为preprocess-companies-and-shuttles的单一任务。该任务执行运行两个Kedro节点的Docker镜像:preprocess-companies-node和preprocess-shuttles-node。
此外,我们在DAG末尾调整了任务顺序。不再为前两个任务设置独立依赖关系,而是将它们合并为单行代码:
tasks["preprocess-companies-and-shuttles"] >> tasks["create-model-input-table-node"]
这确保了create-model-input-table-node任务仅在preprocess-companies-and-shuttles完成后运行。