
使用Delta Lake进行数据版本控制¶
Delta Lake 是一个开源存储层,通过在云存储数据之上添加事务性存储层,为数据湖带来可靠性。它支持ACID事务、数据版本控制和回滚功能。Delta表是Databricks中的默认表格式,也可以在Databricks之外使用。它通常用于数据湖场景,支持增量或批量数据摄入。
本教程将探讨如何在Kedro工作流中使用Delta表,以及如何利用Delta Lake的数据版本控制功能。
先决条件¶
在本示例中,您将使用spaceflights-pandas入门项目,该项目包含可供使用的示例流水线和数据集。如果尚未创建,您可以通过以下命令新建一个Kedro项目:
kedro new --starter spaceflights-pandas
Kedro在kedro-datasets包中提供了多种连接器用于与Delta表交互:pandas.DeltaTableDataset、spark.DeltaTableDataset、spark.SparkDataset、databricks.ManagedTableDataset和ibis.FileDataset都支持delta表格式。在本教程中,我们将使用pandas.DeltaTableDataset连接器通过Pandas DataFrames与Delta表进行交互。要安装kedro-datasets及Delta Lake所需的依赖项,请将以下行添加到您的requirements.txt中:
kedro-datasets[pandas-deltatabledataset]
现在,您可以通过运行以下命令安装项目依赖项:
pip install -r requirements.txt
在目录中使用Delta表¶
将数据集保存为Delta表¶
要在您的Kedro项目中使用Delta表,您可以更新base/catalog.yml文件,将需要保存为Delta表的数据集类型设置为type: pandas.DeltaTableDataset。在本示例中,我们将更新base/catalog.yml文件中的model_input_table数据集:
model_input_table:
type: pandas.DeltaTableDataset
filepath: data/03_primary/model_input_table
save_args:
mode: overwrite
您可以在配置中添加save_args来指定Delta表的保存模式。mode参数可以是"overwrite"或"append",具体取决于您是要覆盖现有Delta表还是追加数据。您还可以指定delta-rs库中write_deltalake函数接受的额外保存选项,这些选项被pandas.DeltaTableDataset用来与Delta表格式进行交互。
当你使用kedro run命令运行Kedro项目时,Delta表将被保存到filepath参数指定的位置,作为一个包含parquet文件的文件夹。该文件夹还包含一个_delta_log目录,用于存储Delta表的事务日志。后续运行管道将在同一位置创建Delta表的新版本,并在_delta_log目录中添加新条目。你可以运行以下Kedro命令来生成model_input_table数据集:
kedro run
假设上游数据集 companies、shuttles 或 reviews 已更新。您可以运行以下命令来生成 model_input_table 数据集的新版本:
kedro run --to-outputs=model_input_table
要检查更新后的数据集和日志:
$ tree data/03_primary
data/03_primary
└── model_input_table
├── _delta_log
│ ├── 00000000000000000000.json
│ └── 00000000000000000001.json
├── part-00001-0d522679-916c-4283-ad06-466c27025bcf-c000.snappy.parquet
└── part-00001-42733095-97f4-46ef-bdfd-3afef70ee9d8-c000.snappy.parquet
加载特定数据集版本¶
要加载特定版本的数据集,您可以在目录条目中的load_args参数里指定版本号:
model_input_table:
type: pandas.DeltaTableDataset
filepath: data/03_primary/model_input_table
load_args:
version: 1
在交互模式下检查数据集¶
你可以在交互式Python会话中检查Delta表的历史记录和元数据。要启动已加载Kedro组件的IPython会话,请运行:
kedro ipython
您可以通过catalog.datasets属性加载Delta表数据集并检查该数据集:
In [1]: model_input_table = catalog.datasets['model_input_table']
您可以通过访问history属性来检查Delta表的历史记录:
In [2]: model_input_table.history
Out [2]:
[
{
'timestamp': 1739891304488,
'operation': 'WRITE',
'operationParameters': {'mode': 'Overwrite'},
'operationMetrics': {
'execution_time_ms': 8,
'num_added_files': 1,
'num_added_rows': 6027,
'num_partitions': 0,
'num_removed_files': 1
},
'clientVersion': 'delta-rs.0.23.1',
'version': 1
},
{
'timestamp': 1739891277424,
'operation': 'WRITE',
'operationParameters': {'mode': 'Overwrite'},
'clientVersion': 'delta-rs.0.23.1',
'operationMetrics': {
'execution_time_ms': 48,
'num_added_files': 1,
'num_added_rows': 6027,
'num_partitions': 0,
'num_removed_files': 0
},
'version': 0
}
]
您还可以通过以下方法检查已加载的表格版本:
In [3]: model_input_table.get_loaded_version()
Out [3]: 1
在Spark中使用Delta表¶
你也可以在Kedro项目中使用PySpark来与Delta表进行交互。如需配置Spark使用Delta表,请参阅Spark与Kedro集成的相关文档。
我们推荐以下工作流程,该流程利用了Kedro中的转码功能:
要创建Delta表,请使用带有
file_format="delta"参数的spark.SparkDataset。您也可以使用这类数据集来读取Delta表或覆盖它。要执行Delta表删除、更新和合并操作,请使用
DeltaTableDataset加载数据,并在节点函数内执行写入操作。
最终,我们得到的目录如下所示:
temperature:
type: spark.SparkDataset
filepath: data/01_raw/data.csv
file_format: "csv"
load_args:
header: True
inferSchema: True
save_args:
sep: '|'
header: True
weather@spark:
type: spark.SparkDataset
filepath: s3a://my_bucket/03_primary/weather
file_format: "delta"
save_args:
mode: "overwrite"
versionAsOf: 0
weather@delta:
type: spark.DeltaTableDataset
filepath: s3a://my_bucket/03_primary/weather
注意
DeltaTableDataset不支持save()操作。您需要选择要执行的操作(DeltaTable.update()、DeltaTable.delete()、DeltaTable.merge())并在节点代码中实现。
注意
如果你已经为Kedro的before_dataset_saved/after_dataset_saved钩子定义了实现,该钩子将不会被触发。这是因为保存操作是通过DeltaTable API在node内部完成的。
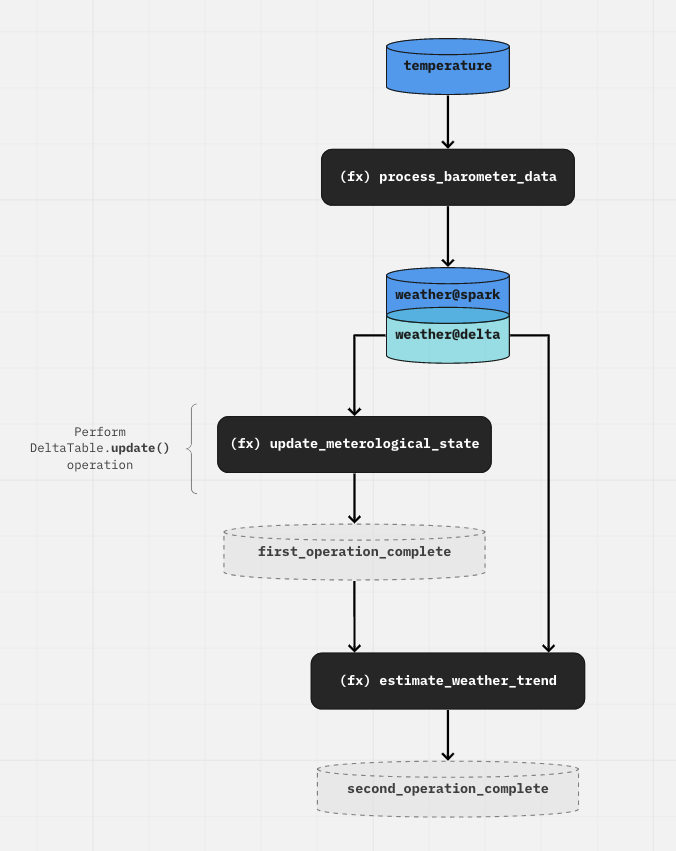
pipeline(
[
node(
func=process_barometer_data, inputs="temperature", outputs="weather@spark"
),
node(
func=update_meterological_state,
inputs="weather@delta",
outputs="first_operation_complete",
),
node(
func=estimate_weather_trend,
inputs=["first_operation_complete", "weather@delta"],
outputs="second_operation_complete",
),
]
)
first_operation_complete 是一个 MemoryDataset,它标志着发生在Kedro DAG"外部"的任何Delta操作已完成。这可以作为下游节点的输入,以保持DAG的结构。否则,如果在此之后没有下游节点需要运行,该节点可以简单地不返回任何内容:
pipeline(
[
node(func=..., inputs="temperature", outputs="weather@spark"),
node(func=..., inputs="weather@delta", outputs=None),
]
)
下图是上述工作流程的可视化表示:
注意
这种创建"虚拟"数据集以保持数据流的模式同样适用于其他"在DAG之外"的执行操作,例如节点内的SQL操作。