使用Jupyter笔记本进行Kedro项目实验¶
本页说明如何使用Jupyter notebook来探索Kedro项目的各个元素。它展示了如何通过kedro jupyter notebook命令设置一个可以访问Kedro项目中catalog、context、pipelines和session变量的笔记本环境,以便您能够查询这些变量。
本页还介绍了如何使用行魔法(line magic)直接在笔记本中显示Kedro-Viz的管道可视化。
示例项目¶
该示例添加了一个笔记本,用于实验spaceflight-pandas-viz starter。作为替代方案,您可以使用不同的starter跟随此示例,或者直接向您自己的项目添加笔记本。
我们将假设示例项目名为spaceflights,但您可以根据需要随意命名。
要创建一个项目,你可以运行以下命令:
kedro new -n spaceflights --tools=viz --example=yes
您可以在创建新Kedro项目中找到更多关于kedro new的选项。
使用kedro jupyter notebook加载项目¶
导航到项目目录 (cd spaceflights) 并在终端中执行以下命令以启动 Jupyter:
kedro jupyter notebook
在首次运行新项目时,系统会询问您是否选择加入使用情况分析。当您用y或n回答后,浏览器窗口将打开一个Jupyter页面,其中列出了您项目中的文件夹:
您现在可以通过新建下拉菜单并选择Kedro (iris)内核来创建新的Jupyter笔记本:
这将打开一个新的浏览器标签页来显示空白的笔记本:

我们建议您将笔记本保存在Kedro项目的notebooks文件夹中。
kedro jupyter notebook 有什么作用?¶
kedro jupyter notebook 命令会启动一个带有定制内核的笔记本,该内核经过扩展以提供以下项目变量:
catalog(类型DataCatalog): 包含所有已定义数据集的数据目录实例;这是context.catalog的快捷方式context(类型KedroContext): Kedro项目上下文,提供对Kedro库组件的访问pipelines(类型dict[str, Pipeline]): 在pipeline registry中定义的管道session(类型KedroSession): 协调管道运行的Kedro会话
此外,当您启动笔记本时,它还会自动运行%load_ext kedro.ipython。
注意
如果在您的Jupyter笔记本中无法使用Kedro变量,可能是配置文件格式错误或缺少依赖项。完整的错误信息会显示在用于启动kedro jupyter notebook的终端上,或者在笔记本单元格中运行%load_ext kedro.ipython时显示。
使用kedro.ipython扩展加载项目¶
在兼容IPython的环境中(如Databricks笔记本、Google Colab等),快速浏览项目中catalog、context、pipelines和session变量的方法是使用kedro.ipython扩展。这个工具无关的解决方案在无法启动Jupyter交互环境时特别有用。您可以使用%load_ext行魔法显式加载Kedro IPython扩展:
In [1]: %load_ext kedro.ipython
如果你是从Kedro项目外部启动交互式环境,需要运行第二行魔法命令来设置项目路径。这样Kedro才能加载catalog、context、pipelines和session变量:
In [2]: %reload_kedro <project_root>
Kedro的IPython扩展会记住项目路径,这样以后调用%reload_kedro时就不需要再指定路径了:
In [1]: %load_ext kedro.ipython
In [2]: %reload_kedro <project_root>
In [3]: %reload_kedro
在笔记本中探索Kedro项目¶
以下是一些使用Kedro变量的示例。要探索所有可用的属性和方法,请参阅相关的API文档或使用Python的dir()函数,例如dir(catalog)。
catalog¶
catalog 可用于通过 catalog.list、catalog.load 和 catalog.save 等方法探索项目的 数据目录。
例如,在笔记本的单元格中添加以下内容以运行 catalog.list:
catalog.list()
当你运行单元格时:
[
'companies',
'reviews',
'shuttles',
'preprocessed_companies',
'preprocessed_shuttles',
'model_input_table',
'regressor',
'metrics',
'companies_columns',
'shuttle_passenger_capacity_plot_exp',
'shuttle_passenger_capacity_plot_go',
'dummy_confusion_matrix',
'parameters',
'params:model_options',
'params:model_options.test_size',
'params:model_options.random_state',
'params:model_options.features'
]
使用正则表达式搜索数据集¶
如果不记得数据集的准确名称,可以使用正则表达式来搜索数据集。
catalog.list("pre*")
当你运行该单元格时:
['preprocessed_companies', 'preprocessed_shuttles']
接下来尝试对 catalog.load 执行以下操作:
catalog.load("shuttles")
输出:
[06/05/24 12:50:17] INFO Loading data from reviews (CSVDataset)...
Out[1]:
shuttle_id review_scores_rating review_scores_comfort ... review_scores_price number_of_reviews reviews_per_month
0 45163 91.0 10.0 ... 9.0 26 0.77
1 49438 96.0 10.0 ... 9.0 61 0.62
2 10750 97.0 10.0 ... 10.0 467 4.66
3 4146 95.0 10.0 ... 9.0 318 3.22
现在尝试以下操作:
catalog.load("parameters")
您应该看到以下内容:
INFO Loading data from 'parameters' (MemoryDataset)...
{
'model_options': {
'test_size': 0.2,
'random_state': 3,
'features': [
'engines',
'passenger_capacity',
'crew',
'd_check_complete',
'moon_clearance_complete',
'iata_approved',
'company_rating',
'review_scores_rating'
]
}
}
注意
如果启用版本控制,你可以加载特定版本的数据集,例如 catalog.load("preprocessed_shuttles", version="2024-06-05T15.08.09.255Z")。
上下文¶
context 允许您访问Kedro的库组件和项目元数据。例如,如果您在单元格中添加以下内容并运行它:
context.project_path
根据您的用户名和路径,您应该会看到类似这样的输出:
PosixPath('/Users/username/kedro_projects/spaceflights')
您可以在KedroContext的API文档中了解更多信息。
pipelines¶
pipelines 是一个包含您项目中 registered pipelines 的字典:
pipelines
输出将显示如下列表:
{'__default__': Pipeline([
Node(create_confusion_matrix, 'companies', 'dummy_confusion_matrix', None),
Node(preprocess_companies, 'companies', ['preprocessed_companies', 'companies_columns'], 'preprocess_companies_node'),
Node(preprocess_shuttles, 'shuttles', 'preprocessed_shuttles', 'preprocess_shuttles_node'),
...
您可以使用此功能来探索您的流水线及其包含的节点:
pipelines["__default__"].all_outputs()
应输出:
{
'X_train',
'regressor',
'shuttle_passenger_capacity_plot_exp',
'y_test',
'model_input_table',
'y_train',
'X_test',
'metrics',
'companies_columns',
'preprocessed_shuttles',
'preprocessed_companies',
'shuttle_passenger_capacity_plot_go',
'dummy_confusion_matrix'
}
session¶
session.run 允许您运行一个管道。不带参数时,这将顺序运行您的 __default__ 项目管道,类似于从终端调用 kedro run:
session.run()
你也可以为session.run指定以下可选参数:
参数名称 |
接受类型 |
描述 |
|---|---|---|
|
|
使用附加了此标签的节点构建管道。如果节点包含任何这些标签,则会被包含在生成的管道中 |
|
|
Kedro |
|
|
运行指定名称的节点 |
|
|
应作为起始点使用的节点名称列表 |
|
|
应作为终点的节点名称列表 |
|
|
应作为起始点使用的数据集名称列表 |
|
|
应作为终点的数据集名称列表 |
|
|
将数据集名称映射到特定数据集版本(时间戳)以便加载。适用于版本化数据集 |
|
|
要运行的模块化流水线名称。必须是在 |
每个会话只能执行一次成功运行,因为会话与运行之间存在一对一映射关系。如需进行多次运行,必须使用%reload_kedro行魔法来获取新的session。
Kedro行魔法¶
行魔法命令是在交互式会话中执行任务的简洁方式。Kedro提供了多个行魔法命令来简化在交互式环境中使用Kedro项目的操作。
%reload_kedro 行魔法¶
您可以在Jupyter笔记本中使用%reload_kedro行魔法来重新加载Kedro变量(例如,如果您在修改数据目录后需要更新catalog)。
你不需要为catalog、context、pipelines和session变量重启内核。
%reload_kedro 接受可选关键字参数 env 和 params。例如,要使用配置环境 prod:
%reload_kedro --env=prod
如需了解更多详情,请运行 %reload_kedro?。
%load_node 行魔法¶
注意
这仍是一项实验性功能,目前仅支持Jupyter Notebook(版本需大于7.0)、Jupyter Lab、IPython和VS Code Notebook。如果您遇到意外行为或想建议功能改进,请在此GitHub问题下添加。
在Jupyter Notebook中使用此功能时,您需要安装以下要求及最低版本:
ipylab>=1.0.0
notebook>=7.0.0
你可以使用%load_node行魔法将项目中某个节点的内容加载到一系列单元格中。要使用%load_node,需要满足两个条件:
节点需要有一个名称
节点的输入需要被持久化
关于创建带名称节点的章节解释了如何确保您的节点具有名称。默认情况下,Kedro将数据保存在内存中。要持久化数据,您需要在数据目录中声明数据集。
注意
节点名称在流水线中必须是唯一的。如果用户未定义名称,Kedro会使用函数名、输入和输出的组合自动生成一个名称。
行魔法将加载你的节点输入、导入和主体内容:
%load_node <my-node-name>
Click to see an example.

要能够访问节点的输入,请确保它们在项目的目录中明确定义。
然后你可以运行生成的单元格,重现该节点在流水线中的执行过程。这可以让你单独探索节点的输入、行为和输出,或者用于调试。
%run_viz 行魔法¶
注意
如果尚未为项目安装Kedro-Viz,请在项目目录下的终端中运行pip install kedro-viz。
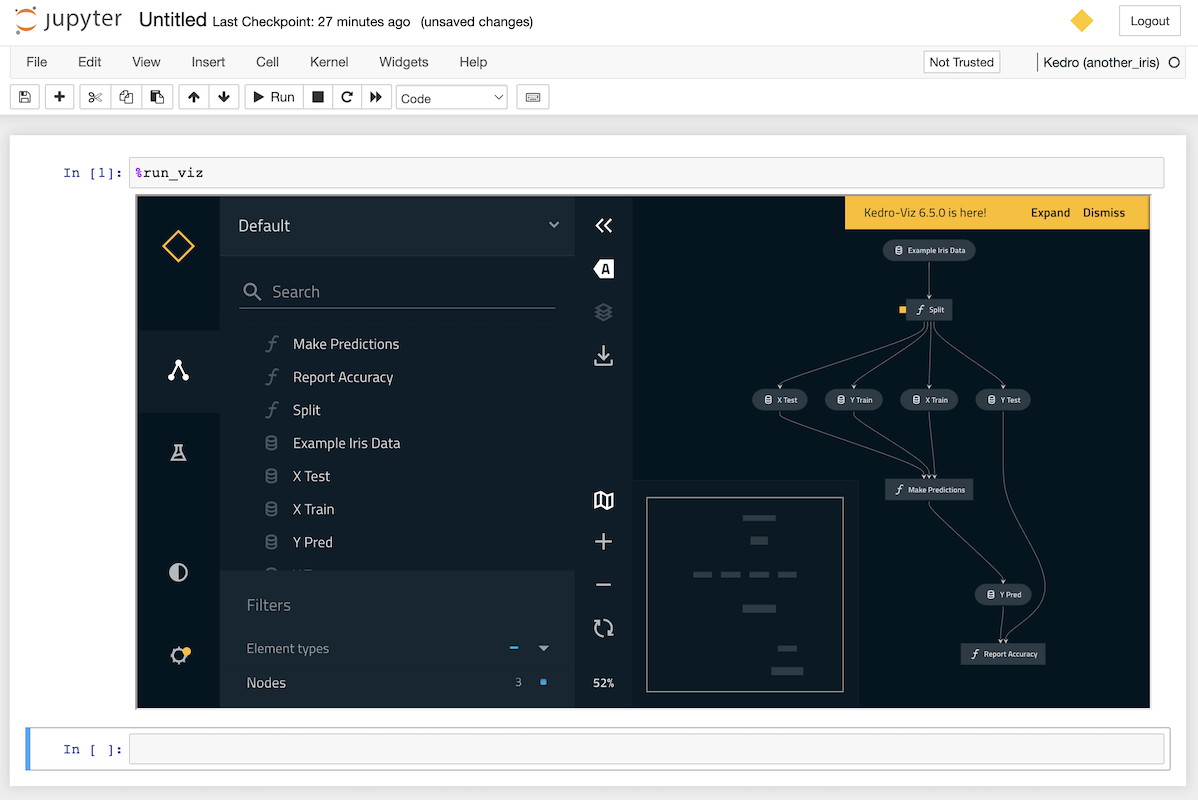
您可以直接在笔记本中使用单元格内的%run_viz行魔法命令来显示管道的交互式可视化:
%run_viz
在笔记本中调试Kedro项目¶
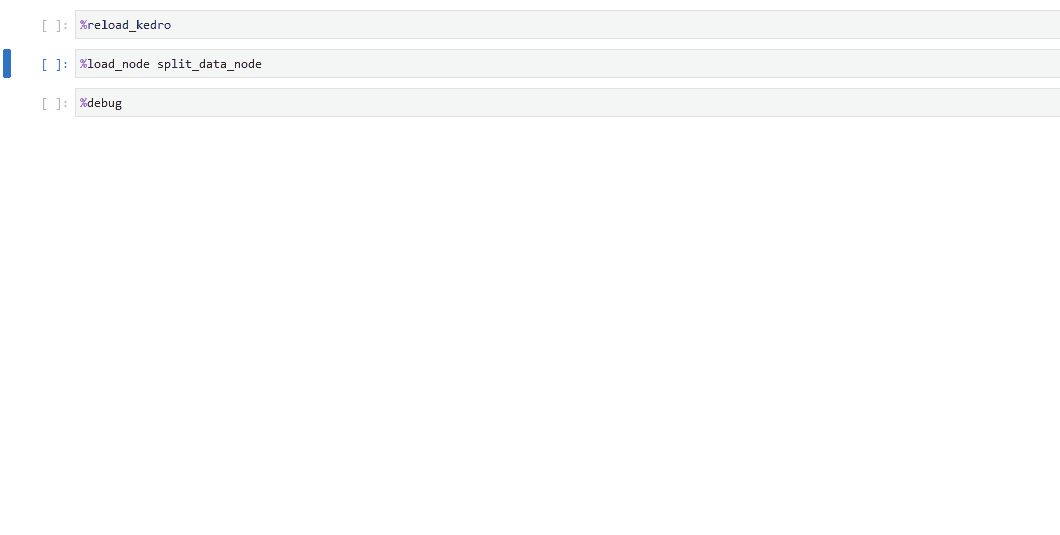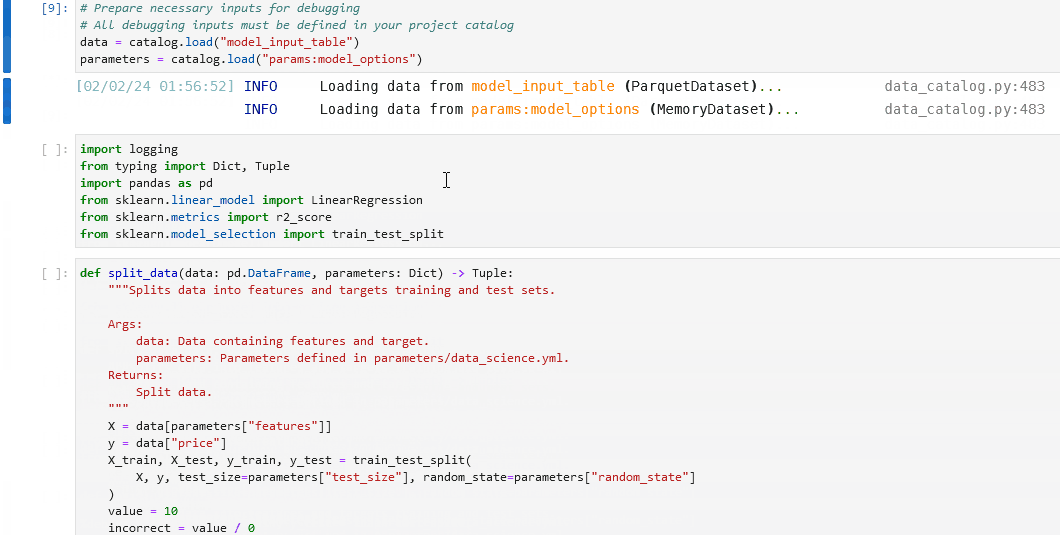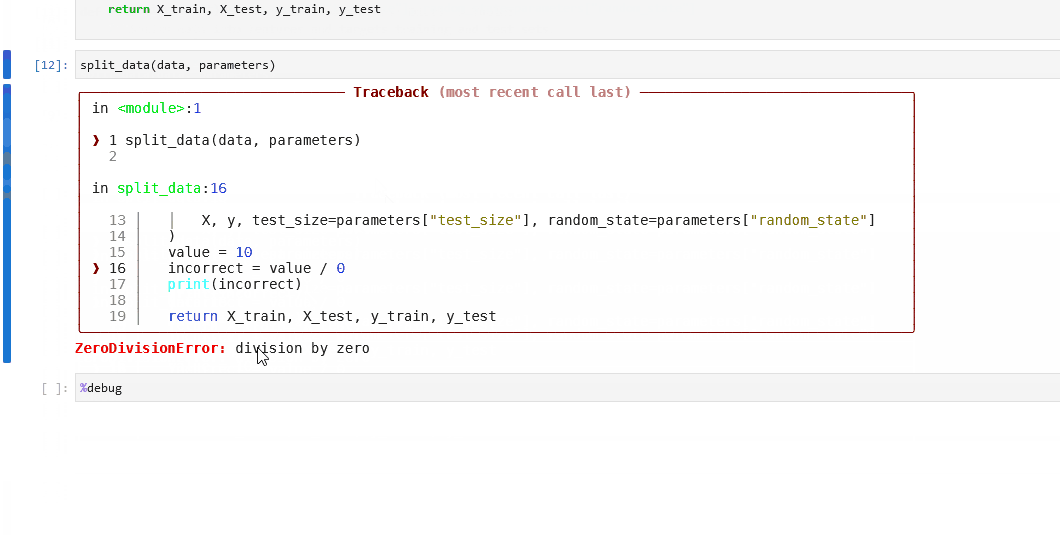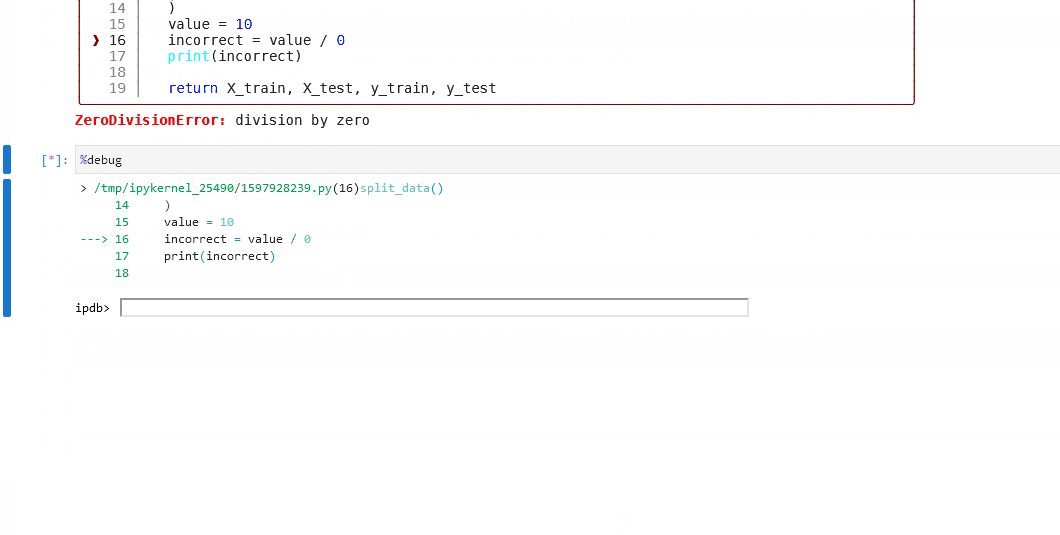
您可以使用内置的%debug line magic在Jupyter笔记本中启动交互式调试器。在单行语句前声明该命令,即可在调试模式下逐步执行。您可以使用参数--breakpoint或-b来设置断点。或者,在发生错误后不带参数运行该命令,即可加载堆栈跟踪并开始调试。
当错误发生后运行%debug时,会按以下顺序执行:
加载最后一个未处理异常的堆栈跟踪。
程序会在异常发生的位置停止。
会打开一个交互式shell,用户可以在其中浏览堆栈跟踪。
然后你可以检查表达式和参数的值,或者在代码中添加断点。
以下是发现流水线中某个节点失败后的示例调试工作流程:
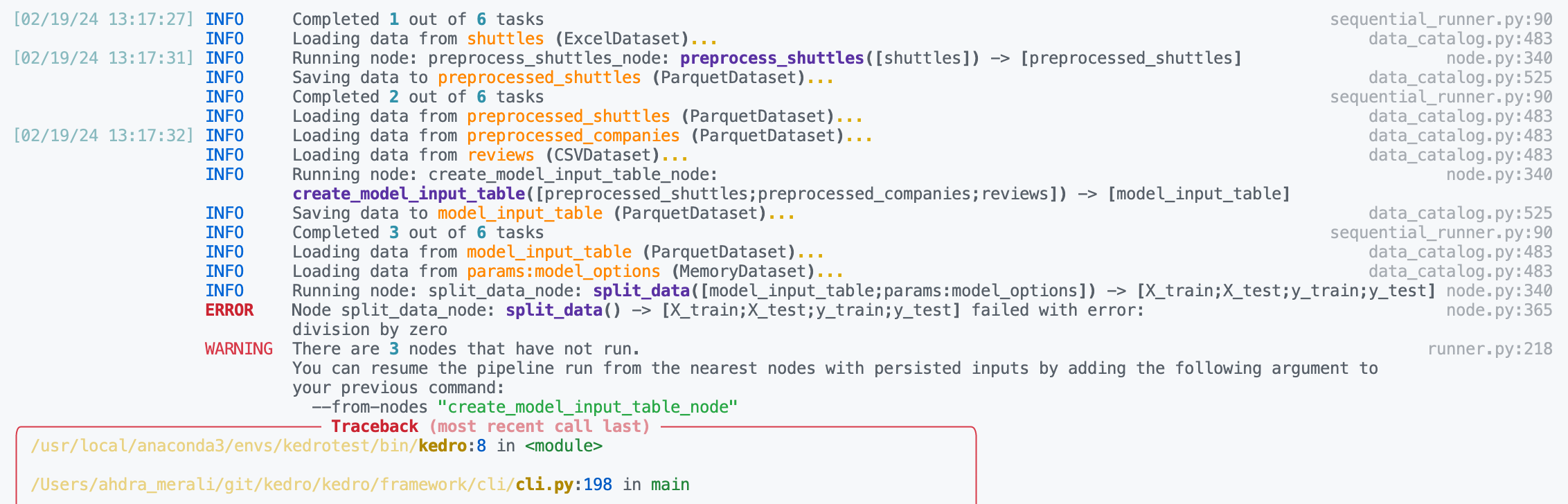
检查日志以查找失败节点的名称。我们可以在下面看到有问题的节点是
split_data_node。
Click to the pipeline failure logs.
在你的笔记本中,运行
%load_node,使用%load_node行魔法加载问题节点的内容。运行填充的单元格以单独检查节点的行为。
如果节点运行出错,可以在笔记本中使用
%debug启动交互式调试会话。
Click to see this workflow in action.
注意
%load_node行魔法目前仅适用于Jupyter Notebook(版本大于7.0)和Jupyter Lab。如果您在其他交互式环境中工作,请手动从项目文件中复制内容,而不是使用%load_node自动填充节点的内容,并从步骤2继续。
你也可以通过使用%pdb行魔法来设置调试器在异常发生时自动运行。这种自动行为可以在执行程序前用%pdb 1或%pdb on启用,用%pdb 0或%pdb off禁用。
Click to see an example.

以下是一些可用于与ipdb shell交互的示例命令:
命令 |
描述 |
|---|---|
|
显示文件中的当前位置 |
|
显示命令列表,或获取特定命令的帮助信息 |
|
退出调试器和程序 |
|
退出调试器,继续执行程序 |
|
进入程序的下一步 |
重复上一条命令 |
|
|
打印变量 |
|
进入子程序 |
|
从子程序返回 |
|
插入断点 |
|
打印当前函数的参数列表 |
如需了解更多信息,请在调试器中使用help命令,或查看ipdb仓库获取指导。
进阶用户须知¶
每个Kedro项目都有独立的Jupyter内核,因此您可以通过选择相应内核,在单个Jupyter实例中切换不同的Kedro项目。
为确保Jupyter内核始终指向正确的Python可执行文件,如果已存在同名内核kedro_,则会被替换。
你可以使用jupyter kernelspec命令集来管理你的Jupyter内核。例如,要删除一个内核,可以运行jupyter kernelspec remove 。
IPython、JupyterLab及其他Jupyter客户端¶
你也可以通过以下方式将IPython shell连接到Kedro项目内核:
kedro ipython
该命令会启动一个已加载扩展的IPython shell,等同于运行 ipython --ext kedro.ipython。您首次在spaceflights tutorial教程中看到这个功能。
类似地,以下操作会创建一个自定义的Jupyter内核,该内核会自动加载扩展并启动已选择此内核的JupyterLab:
kedro jupyter lab
你可以使用任何其他Jupyter客户端连接到Kedro项目内核,例如Qt Console,可以通过以下方式使用spaceflights内核启动:
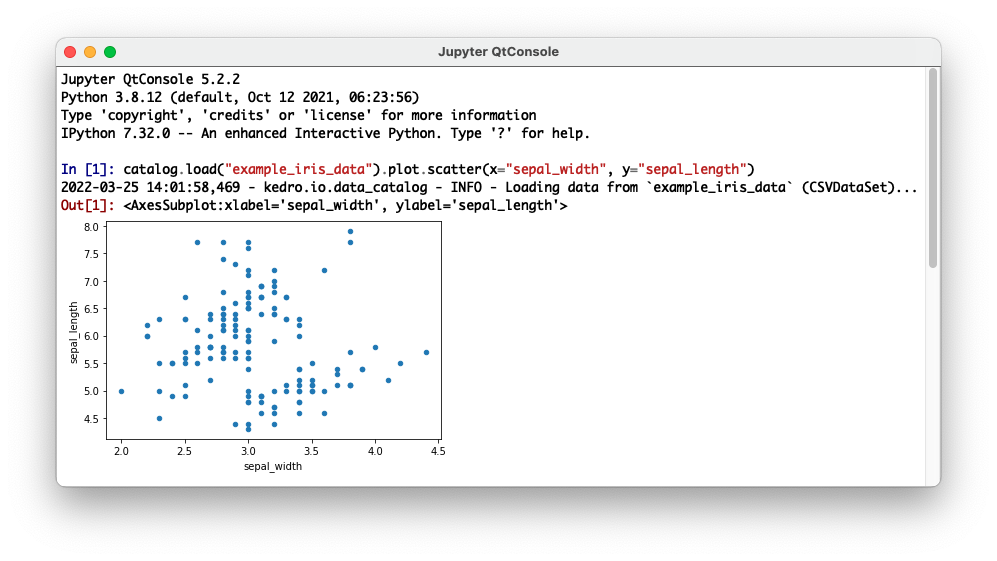
jupyter qtconsole --kernel=spaceflights
这将自动在支持图形功能(如嵌入式图表)的控制台中加载Kedro IPython: