
常见用例¶
使用Hooks扩展节点的行为¶
你可以使用before_node_run和after_node_run钩子在节点执行前后添加额外行为。此外,你不仅可以对单个节点或整个Kedro流水线应用额外行为,还能基于标签或命名空间对节点的子集进行操作:例如,假设我们想为某个节点添加以下额外行为:
from kedro.pipeline.node import Node
def say_hello(node: Node):
"""An extra behaviour for a node to say hello before running."""
print(f"Hello from {node.name}")
然后您可以根据节点名称将其添加到单个节点:
# src/<package_name>/hooks.py
from kedro.framework.hooks import hook_impl
from kedro.pipeline.node import Node
class ProjectHooks:
@hook_impl
def before_node_run(self, node: Node):
# adding extra behaviour to a single node
if node.name == "hello":
say_hello(node)
或者根据节点的标签将其添加到节点组中:
# src/<package_name>/hooks.py
from kedro.framework.hooks import hook_impl
from kedro.pipeline.node import Node
class ProjectHooks:
@hook_impl
def before_node_run(self, node: Node):
if "hello" in node.tags:
say_hello(node)
或者将其添加到整个流水线中的所有节点:
# src/<package_name>/hooks.py
from kedro.framework.hooks import hook_impl
from kedro.pipeline.node import Node
class ProjectHooks:
@hook_impl
def before_node_run(self, node: Node):
# adding extra behaviour to all nodes in the pipeline
say_hello(node)
如果你的用例利用了装饰器,例如使用像tenacity这样的库来重试节点的执行,你仍然可以直接装饰节点的函数:
from tenacity import retry
@retry
def my_flaky_node_function():
...
或者在before_node_run钩子中如下应用:
# src/<package_name>/hooks.py
from tenacity import retry
from kedro.framework.hooks import hook_impl
from kedro.pipeline.node import Node
class ProjectHooks:
@hook_impl
def before_node_run(self, node: Node):
# adding retrying behaviour to nodes tagged as flaky
if "flaky" in node.tags:
node.func = retry(node.func)
使用Hooks自定义数据集的加载和保存方法¶
我们建议在适当情况下使用before_dataset_loaded/after_dataset_loaded和before_dataset_saved/after_dataset_saved钩子来自定义数据集的load和save方法。
例如,您可以按如下方式添加关于数据集加载运行时间的日志记录:
import logging
import time
from typing import Any
from kedro.framework.hooks import hook_impl
from kedro.pipeline.node import Node
class LoggingHook:
"""A hook that logs how many time it takes to load each dataset."""
def __init__(self):
self._timers = {}
@property
def _logger(self):
return logging.getLogger(__name__)
@hook_impl
def before_dataset_loaded(self, dataset_name: str, node: Node) -> None:
start = time.time()
self._timers[dataset_name] = start
@hook_impl
def after_dataset_loaded(self, dataset_name: str, data: Any, node: Node) -> None:
start = self._timers[dataset_name]
end = time.time()
self._logger.info(
"Loading dataset %s before node '%s' takes %0.2f seconds",
dataset_name,
node.name,
end - start,
)
使用Hooks加载外部凭证¶
我们建议使用after_context_created钩子函数,从任何外部凭证管理器向会话的配置加载器实例添加凭证。本示例展示了如何从Azure KeyVault加载凭证。
以下是KeyVault实例示例,请注意KeyVault和密钥名称:
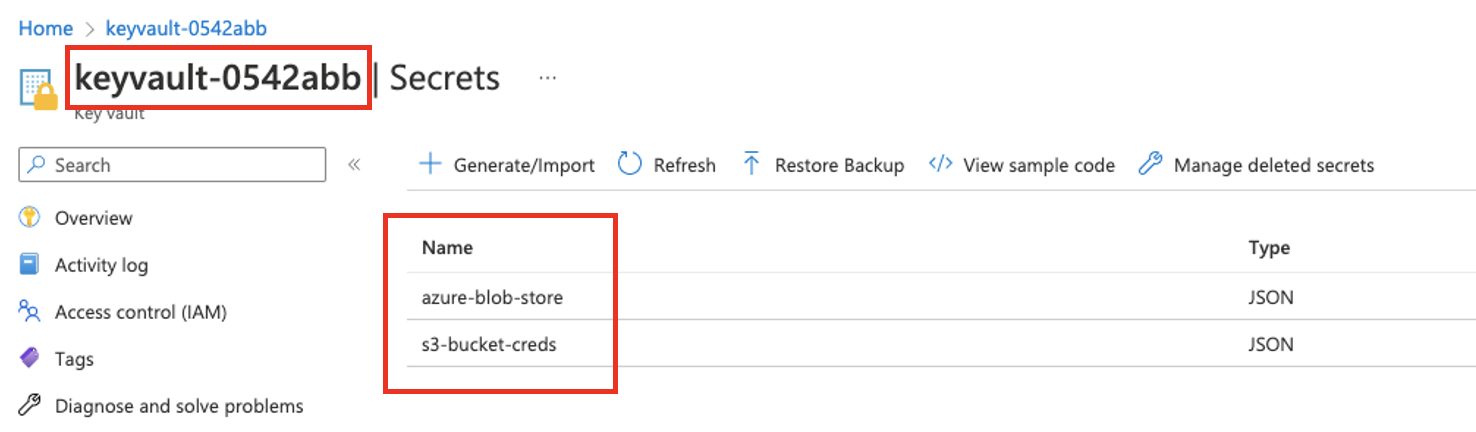
这些凭证将用于访问数据目录中的这些数据集:
weather:
type: spark.SparkDataset
filepath: s3a://your_bucket/data/01_raw/weather*
file_format: csv
credentials: s3_creds
cars:
type: pandas.CSVDataset
filepath: https://your_data_store.blob.core.windows.net/data/01_raw/cars.csv
file_format: csv
credentials: abs_creds
然后我们可以使用以下钩子实现来获取并注入这些凭证:
# hooks.py
from kedro.framework.hooks import hook_impl
from azure.keyvault.secrets import SecretClient
from azure.identity import DefaultAzureCredential
class AzureSecretsHook:
@hook_impl
def after_context_created(self, context) -> None:
keyVaultName = "keyvault-0542abb" # or os.environ["KEY_VAULT_NAME"] if you would like to provide it through environment variables
KVUri = f"https://{keyVaultName}.vault.azure.net"
my_credential = DefaultAzureCredential()
client = SecretClient(vault_url=KVUri, credential=my_credential)
secrets = {
"abs_creds": "azure-blob-store",
"s3_creds": "s3-bucket-creds",
}
azure_creds = {
cred_name: client.get_secret(secret_name).value
for cred_name, secret_name in secrets.items()
}
context.config_loader["credentials"] = {
**context.config_loader["credentials"],
**azure_creds,
}
最后,在settings.py中注册Hook:
from my_project.hooks import AzureSecretsHook
HOOKS = (AzureSecretsHook(),)
注意
注意:DefaultAzureCredential()是Azure推荐的授权访问存储账户数据的认证方式。如需了解更多信息,请参阅关于如何向Azure进行身份验证并授权访问Blob数据的文档。
使用Hooks从DataCatalog读取metadata¶
使用after_catalog_created钩子访问metadata来扩展Kedro。
class MetadataHook:
@hook_impl
def after_catalog_created(
self,
catalog: DataCatalog,
):
for dataset_name, dataset in catalog.datasets.__dict__.items():
print(f"{dataset_name} metadata: \n {str(dataset.metadata)}")
使用Hooks调试你的pipeline¶
你可以使用Hooks在流水线运行出错时,通过Kedro Hooks启动事后调试会话,使用pdb。ipdb也可以采用同样的方式进行集成。
调试节点¶
当你的node中出现未捕获的错误时,要实现调试会话的启动,请实现on_node_error Hook specification:
import pdb
import sys
import traceback
from kedro.framework.hooks import hook_impl
class PDBNodeDebugHook:
"""A hook class for creating a post mortem debugging with the PDB debugger
whenever an error is triggered within a node. The local scope from when the
exception occured is available within this debugging session.
"""
@hook_impl
def on_node_error(self):
_, _, traceback_object = sys.exc_info()
# Print the traceback information for debugging ease
traceback.print_tb(traceback_object)
# Drop you into a post mortem debugging session
pdb.post_mortem(traceback_object)
然后你可以在项目的settings.py中注册这个PDBNodeDebugHook:
HOOKS = (PDBNodeDebugHook(),)
调试管道¶
当你的pipeline中出现未被捕获的错误时,若要启动调试会话,请实现on_pipeline_error Hook specification:
import pdb
import sys
import traceback
from kedro.framework.hooks import hook_impl
class PDBPipelineDebugHook:
"""A hook class for creating a post mortem debugging with the PDB debugger
whenever an error is triggered within a pipeline. The local scope from when the
exception occured is available within this debugging session.
"""
@hook_impl
def on_pipeline_error(self):
# We don't need the actual exception since it is within this stack frame
_, _, traceback_object = sys.exc_info()
# Print the traceback information for debugging ease
traceback.print_tb(traceback_object)
# Drop you into a post mortem debugging session
pdb.post_mortem(traceback_object)
然后你可以在项目的settings.py中注册这个PDBPipelineDebugHook:
HOOKS = (PDBPipelineDebugHook(),)