
如何将MLflow集成到您的Kedro工作流中¶
MLflow 是一个用于管理端到端机器学习生命周期的开源平台。 它提供了跟踪实验、将代码打包成可复现运行以及共享和部署模型的工具。 MLflow 支持 TensorFlow、PyTorch 和 scikit-learn 等机器学习框架。
在Kedro项目中集成MLflow功能,可帮助您追踪和管理机器学习实验与模型。例如,您可以将Kedro流水线运行产生的指标、参数和产物记录到MLflow中,进而对比和复现实验结果。当多人协作开发Kedro项目时,MLflow提供的模型注册表和部署工具能协助您共享并部署机器学习模型。
先决条件¶
你需要以下内容:
一个在虚拟环境中可运行的Kedro项目。本文档中的示例假设使用
spaceflights-pandas-viz入门模板。如果您不熟悉Spaceflights项目,请查看我们的教程。安装在同一虚拟环境中的MLflow客户端。在本教程中,您可以使用MLflow的最简配置。
要开始使用,请创建一个新的Kedro项目:
$ kedro new --starter=spaceflights-pandas-viz --name spaceflights-mlflow
$ cd spaceflights-mlflow
$ python -m venv && source .venv/bin/activate
(.venv) $ pip install -r requirements.txt
然后从您的目录根目录按如下方式本地启动UI:
(.venv) $ pip install mlflow
(.venv) $ mlflow ui --backend-store-uri ./mlflow_runs
这将使MLflow将每次运行的元数据和工件记录到一个名为mlflow_runs的本地目录中。
注意
如果想使用更复杂的设置,可以参考 MLflow跟踪服务器的文档、 官方MLflow跟踪服务器5分钟概览, 以及MLflow跟踪服务器文档。
简单用例¶
尽管MLflow在处理机器学习(ML)和AI管道时表现最佳,但您仍然可以将常规的Kedro运行作为实验记录在MLflow中,即使它们不使用ML。
本节将介绍如何使用kedro-mlflow插件,以简单直接的方式在MLflow中追踪您的Kedro管道。
使用kedro-mlflow轻松追踪Kedro在MLflow中的运行记录¶
要开始使用 kedro-mlflow,请先安装它:
pip install kedro-mlflow
在Kedro的最新版本中,这将自动为您注册kedro-mlflow的Hooks。
接下来,在您的conf/local目录中创建一个mlflow.yml配置文件,
用于配置MLflow运行结果的存储位置,
与您启动mlflow ui命令的方式保持一致:
server:
mlflow_tracking_uri: mlflow_runs
从现在开始,当你执行 kedro run 时,你将看到来自 kedro-mlflow 的日志:
[06/04/24 09:52:53] INFO Kedro project spaceflights-mlflow session.py:324
INFO Registering new custom resolver: 'km.random_name' mlflow_hook.py:65
INFO The 'tracking_uri' key in mlflow.yml is relative kedro_mlflow_config.py:260
('server.mlflow_(tracking|registry)_uri = mlflow_runs').
It is converted to a valid uri:
'file:///Users/juan_cano/Projects/QuantumBlackLabs/kedro-
mlflow-playground/spaceflights-mlflow/mlflow_runs'
如果您打开跟踪服务器界面,您将看到类似这样的结果:
请注意,kedro-mlflow使用了run_params的一个子集作为MLflow运行的标签,并将Kedro参数记录为MLflow参数。
查看官方kedro-mlflow教程 获取更详细的步骤说明。
使用kedro-mlflow在MLflow中进行工件追踪¶
kedro-mlflow 提供了一些开箱即用的工件追踪功能,可将您的Kedro项目与MLflow部署连接起来,例如MlflowArtifactDataset,它可用于包装您现有的任何Kedro数据集。
使用该数据集的优势在于可以利用MLflow UI的预览功能。
警告
这适用于作为节点输出的数据集,对于自由输入的数据集(因此仅被加载)将不会产生任何效果。
例如,如果您像这样修改matplotlib.MatplotlibWriter数据集:
# conf/base/catalog.yml
dummy_confusion_matrix:
- type: matplotlib.MatplotlibWriter
- filepath: data/08_reporting/dummy_confusion_matrix.png
- versioned: true
+ type: kedro_mlflow.io.artifacts.MlflowArtifactDataset
+ dataset:
+ type: matplotlib.MatplotlibWriter
+ filepath: data/08_reporting/dummy_confusion_matrix.png
然后该图像将被记录为运行产物的一部分,您可以在MLflow网页界面中预览它:
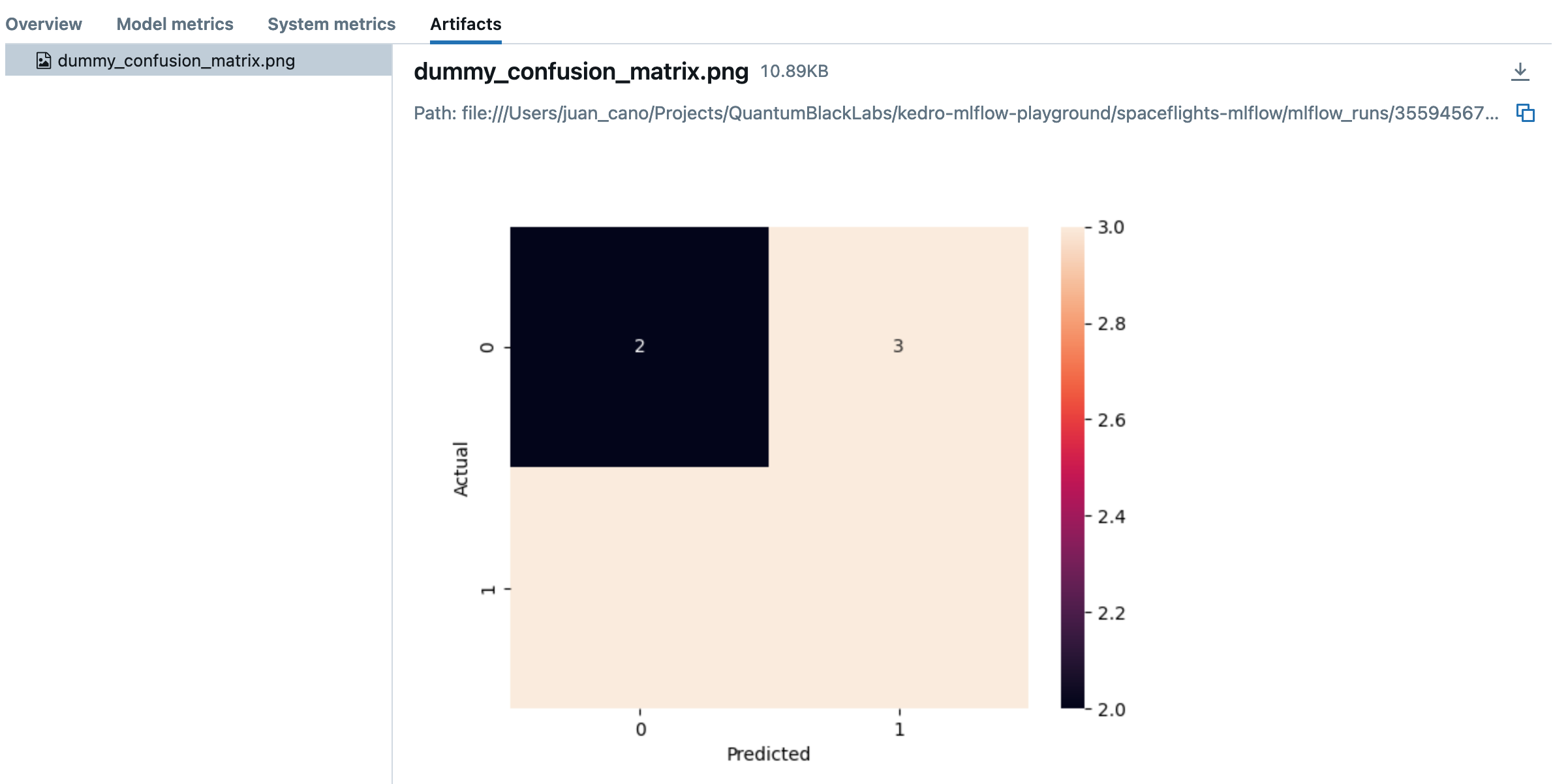
警告
如果遇到Failed while saving data to dataset MlflowMatplotlibWriter错误,
可能是因为您在数据集标记为versioned: true时已经执行过kedro run。
解决方案是清理旧的data/08_reporting/dummy_confusion_matrix.png目录。
查看kedro-mlflow官方文档中关于版本化Kedro数据集的部分以获取更多信息。
在MLflow中使用kedro-mlflow的模型注册表¶
如果你的Kedro流水线训练了一个机器学习模型,你可以通过MLflow跟踪这些模型,以便管理和部署它们。
kedro-mlflow插件引入了一个特殊的工件类型MlflowModelTrackingDataset,
你可以用它来将模型作为MLflow工件进行加载和保存。
例如,如果您有一个对应于scikit-learn模型的数据集,可以按以下方式修改:
regressor:
- type: pickle.PickleDataset
- filepath: data/06_models/regressor.pickle
- versioned: true
+ type: kedro_mlflow.io.models.MlflowModelTrackingDataset
+ flavor: mlflow.sklearn
kedro-mlflow Hook 会将模型作为运行的一部分记录在 the standard MLflow Model format 中。
如果您还希望注册它
(即将其存储在MLflow模型注册表中)
可以添加一个registered_model_name参数:
regressor:
type: kedro_mlflow.io.models.MlflowModelTrackingDataset
flavor: mlflow.sklearn
save_args:
registered_model_name: spaceflights-regressor
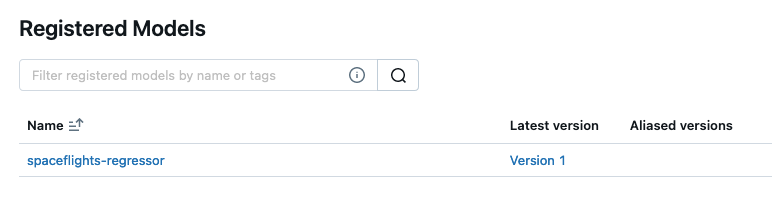
然后您将看到它被列为已注册模型:
要从特定运行中加载模型,您可以指定run_id。
为此,您可以利用runtime parameters:
# Add the intermediate datasets to run only the inference
X_test:
type: pandas.ParquetDataset
filepath: data/05_model_input/X_test.parquet
y_test:
type: pandas.CSVDataset # https://github.com/pandas-dev/pandas/issues/54638
filepath: data/05_model_input/y_test.csv
regressor:
type: kedro_mlflow.io.models.MlflowModelTrackingDataset
flavor: mlflow.sklearn
run_id: ${runtime_params:mlflow_run_id,null}
save_args:
registered_model_name: spaceflights-regressor
并在命令行中指定MLflow运行ID,如下所示:
$ kedro run --to-outputs=X_test,y_test
...
$ kedro run --from-nodes=evaluate_model_node --params mlflow_run_id=4cba84...
注意
请注意,出于可重现性考虑,MLflow运行记录是不可变的,因此您无法在现有运行中保存模型。
高级使用案例¶
使用Hooks在MLflow中追踪Kedro运行的额外元数据¶
到目前为止,kedro-mlflow已被证明非常有用。
然而,您可能需要在运行中跟踪额外的元数据。
一种可能的实现方式是使用before_pipeline_run()钩子
来记录传递给该钩子的run_params参数。
具体实现如下所示:
# src/spaceflights_mlflow/hooks.py
import typing as t
import logging
import mlflow
from kedro.framework.hooks import hook_impl
logger = logging.getLogger(__name__)
class ExtraMLflowHooks:
@hook_impl
def before_pipeline_run(self, run_params: dict[str, t.Any]):
logger.info("Logging extra metadata to MLflow")
mlflow.set_tags({
"pipeline": run_params["pipeline_name"] or "__default__",
"custom_version": "0.1.0",
})
然后在settings.py中启用您的自定义钩子:
# src/spaceflights_mlflow/settings.py
...
from .hooks import ExtraMLflowHooks
HOOKS = (ExtraMLflowHooks(),)
...
启用此自定义钩子后,您可以执行kedro run,并在日志中看到类似以下内容:
...
[06/04/24 10:44:25] INFO Logging extra metadata to MLflow hooks.py:13
...
如果您打开跟踪服务器界面,您将看到类似这样的结果:
使用Python API在MLflow中追踪Kedro¶
如果您通过Python API以编程方式运行Kedro,可以使用MLflow的"fluent" API记录运行过程。
例如,以生命周期管理示例作为起点:
from pathlib import Path
import mlflow
from kedro.framework.session import KedroSession
from kedro.framework.startup import bootstrap_project
bootstrap_project(Path.cwd())
mlflow.set_experiment("Kedro Spaceflights test")
with KedroSession.create() as session:
with mlflow.start_run():
mlflow.set_tag("session_id", session.session_id)
session.run()
如果您需要更大的灵活性或记录额外参数,可能需要手动运行Kedro管道。