ot.gaussian
高斯分布的最优运输
函数
- ot.gaussian.bures_wasserstein_barycenter(m, C, weights=None, num_iter=1000, eps=1e-07, log=False)[源]
返回样本之间的OT线性算子。
该函数估计经验分布的最佳重心。这相当于解决不动点
多个高斯分布的算法 \(\left{\mathcal{N}(\mu,\Sigma)\right}_{i=1}^n\)
[1]。
重心仍然遵循高斯分布 \(\mathcal{N}(\mu_b,\Sigma_b)\),其中:
\[\mu_b = \sum_{i=1}^n w_i \mu_i\]广义重心协方差是以下定点算法的解:
\[\Sigma_b = \sum_{i=1}^n w_i \left(\Sigma_b^{1/2}\Sigma_i^{1/2}\Sigma_b^{1/2}\right)^{1/2}\]- Parameters:
- Returns:
mb ((d,) 类数组) – 重心的均值
Cb ((d, d) 类数组) – 重心的协方差
log (字典) – 仅在参数中log==True时返回日志字典
参考文献
使用 ot.gaussian.bures_wasserstein_barycenter 的示例

- ot.gaussian.bures_wasserstein_distance(ms, mt, Cs, Ct, log=False)[源]
返回样本之间的Bures Wasserstein距离。
该函数估计了两个经验分布源 \(\mu_s\) 和目标 \(\mu_t\) 之间的Bures-Wasserstein距离,在备注2.31 [1] 中讨论。
源分布和目标分布之间的Bures Wasserstein距离 \(\mathcal{W}\)
\[\mathcal{W}(\mu_s, \mu_t)_2^2= \left\lVert \mathbf{m}_s - \mathbf{m}_t \right\rVert^2 + \mathcal{B}(\Sigma_s, \Sigma_t)^{2}\]其中 :
\[\mathbf{B}(\Sigma_s, \Sigma_t)^{2} = \text{Tr}\left(\Sigma_s + \Sigma_t - 2 \sqrt{\Sigma_s^{1/2}\Sigma_t\Sigma_s^{1/2}} \right)\]- Parameters:
ms (类数组 (d,)) – 源分布的均值
mt (类似数组 (d,)) – 目标分布的均值
Cs (类数组 (d,d)) – 源分布的协方差
Ct (类数组 (d,d)) – 目标分布的协方差
log (bool, 可选) – 如果为真,则记录日志
- Returns:
W (float) – Bures Wasserstein 距离
log (dict) – 仅在参数中 log==True 时返回日志字典
参考文献
- ot.gaussian.bures_wasserstein_mapping(ms, mt, Cs, Ct, log=False)[源]
返回样本之间的OT线性算子。
该函数估计对齐两个经验分布的最优线性算子。这等价于估计两个高斯分布之间的封闭形式映射 \(\mathcal{N}(\mu_s,\Sigma_s)\) 和 \(\mathcal{N}(\mu_t,\Sigma_t)\),如[1]中所提出,并在[2]的备注2.29中讨论。
从源到目标的线性算子 \(M\)
\[M(\mathbf{x})= \mathbf{A} \mathbf{x} + \mathbf{b}\]其中 :
\[ \begin{align}\begin{aligned}\mathbf{A} &= \Sigma_s^{-1/2} \left(\Sigma_s^{1/2}\Sigma_t\Sigma_s^{1/2} \right)^{1/2} \Sigma_s^{-1/2}\\\mathbf{b} &= \mu_t - \mathbf{A} \mu_s\end{aligned}\end{align} \]- Parameters:
ms (类数组 (d,)) – 源分布的均值
mt (类似数组 (d,)) – 目标分布的均值
Cs (类数组 (d,d)) – 源分布的协方差
Ct (类数组 (d,d)) – 目标分布的协方差
log (bool, 可选) – 如果为真,则记录日志
- Returns:
A ((d, d) 数组-like) – 线性算子
b ((1, d) 数组-like) – 偏差
log (字典) – 仅在参数中log==True时返回日志字典
参考文献
- ot.gaussian.empirical_bures_wasserstein_barycenter(X, reg=1e-06, weights=None, num_iter=1000, eps=1e-07, w=None, bias=True, log=False)[源]
返回样本之间的OT线性算子。
该函数估计经验分布的最优重心。这相当于求解不动点
多个高斯分布的算法 \(\left{\mathcal{N}(\mu,\Sigma)\right}_{i=1}^n\)
[1]。
重心仍然遵循高斯分布 \(\mathcal{N}(\mu_b,\Sigma_b)\),其中:
\[\mu_b = \sum_{i=1}^n w_i \mu_i\]广义重心协方差是以下定点算法的解:
\[\Sigma_b = \sum_{i=1}^n w_i \left(\Sigma_b^{1/2}\Sigma_i^{1/2}\Sigma_b^{1/2}\right)^{1/2}\]- Parameters:
- Returns:
mb ((d,) 类数组) – 重心的均值
Cb ((d, d) 类数组) – 重心的协方差
log (字典) – 仅在参数中log==True时返回日志字典
参考文献
- ot.gaussian.empirical_bures_wasserstein_distance(xs, xt, reg=1e-06, ws=None, wt=None, bias=True, log=False)[源]
返回分布的均值和协方差的Bures Wasserstein距离。
该函数估计了两个经验分布源 \(\mu_s\) 和目标 \(\mu_t\) 之间的Bures-Wasserstein距离,在备注2.31 [1] 中讨论。
源分布和目标分布之间的Bures Wasserstein距离 \(\mathcal{W}\)
\[\mathcal{W}(\mu_s, \mu_t)_2^2= \left\lVert \mathbf{m}_s - \mathbf{m}_t \right\rVert^2 + \mathcal{B}(\Sigma_s, \Sigma_t)^{2}\]其中 :
\[\mathbf{B}(\Sigma_s, \Sigma_t)^{2} = \text{Tr}\left(\Sigma_s + \Sigma_t - 2 \sqrt{\Sigma_s^{1/2}\Sigma_t\Sigma_s^{1/2}} \right)\]- Parameters:
- Returns:
W (float) – Bures Wasserstein 距离
log (dict) – 仅在参数中 log==True 时返回日志字典
参考文献
- ot.gaussian.empirical_bures_wasserstein_mapping(xs, xt, reg=1e-06, ws=None, wt=None, bias=True, log=False)[源]
返回样本之间的OT线性算子。
该函数估计对齐两个经验分布的最优线性算子。这等价于估计两个高斯分布之间的封闭形式映射 \(\mathcal{N}(\mu_s,\Sigma_s)\) 和 \(\mathcal{N}(\mu_t,\Sigma_t)\),如[1]中所提出,并在[2]的备注2.29中讨论。
从源到目标的线性算子 \(M\)
\[M(\mathbf{x})= \mathbf{A} \mathbf{x} + \mathbf{b}\]其中 :
\[ \begin{align}\begin{aligned}\mathbf{A} &= \Sigma_s^{-1/2} \left(\Sigma_s^{1/2}\Sigma_t\Sigma_s^{1/2} \right)^{1/2} \Sigma_s^{-1/2}\\\mathbf{b} &= \mu_t - \mathbf{A} \mu_s\end{aligned}\end{align} \]- Parameters:
- Returns:
A ((d, d) 数组-like) – 线性算子
b ((1, d) 数组-like) – 偏差
log (字典) – 仅在参数中log==True时返回日志字典
参考文献
使用 ot.gaussian.empirical_bures_wasserstein_mapping 的示例
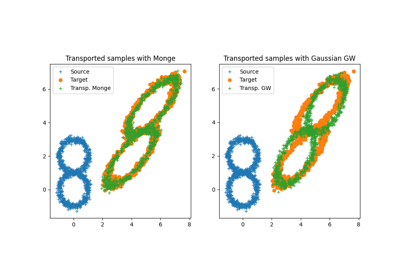
- ot.gaussian.empirical_gaussian_gromov_wasserstein_distance(xs, xt, ws=None, wt=None, log=False)[源]
返回样本之间的高斯Gromov-Wasserstein距离。
该函数估计两个高斯分布源 \(\mu_s\) 和目标 \(\mu_t\) 之间的高斯Gromov-Wasserstein距离,其参数是从提供的样本 \(\mathcal{X}_s\) 和 \(\mathcal{X}_t\) 中估计的。有关更多细节,请参见[57] 定理4.1。
- Parameters:
xs (类似数组 (ns,d)) – 源领域中的样本
xt (类数组 (nt,d)) – 目标领域中的样本
ws (array-like (ns,1), 可选) – 源样本的权重
wt (类似数组 (ns,1), 可选) – 目标样本的权重
log (bool, 可选) – 如果为真,则记录日志
- Returns:
G – 高斯Gromov-Wasserstein距离
- Return type:
参考文献
高斯分布之间的距离。《应用概率杂志》,59(4),1178-1198。
- ot.gaussian.empirical_gaussian_gromov_wasserstein_mapping(xs, xt, ws=None, wt=None, sign_eigs=None, log=False)[源]
返回样本之间的高斯Gromov-Wasserstein映射。
该函数估计两个高斯分布源 \(\mu_s\) 和目标 \(\mu_t\) 之间的高斯 Gromov-Wasserstein 映射,其参数是从提供的样本 \(\mathcal{X}_s\) 和 \(\mathcal{X}_t\) 中估算得出的。详见 [57] 定理 4.1。
- Parameters:
xs (类似数组 (ns,ds)) – 源领域中的样本
xt (类似数组 (nt,dt)) – 目标领域中的样本
ws (array-like (ns,1), 可选) – 源样本的权重
wt (类似数组 (ns,1), 可选) – 目标样本的权重
sign_eigs (array-like (min(ds,dt),) 或 string, 可选) – 映射矩阵的特征值的符号,默认情况下所有符号将为正。如果提供了‘skewness’,特征值的符号将选择为投影数据的偏斜度的符号的乘积。
log (bool, 可选) – 如果为真,则记录日志
- Returns:
A ((dt, ds) 类数组) – 线性算子
b ((1, dt) 类数组) – 偏置
.. _references-empirical_gaussian_gromov_wasserstein_mapping
参考文献
高斯分布之间的距离。《应用概率杂志》,59(4),1178-1198。
使用 ot.gaussian.empirical_gaussian_gromov_wasserstein_mapping
- ot.gaussian.gaussian_gromov_wasserstein_distance(Cov_s, Cov_t, log=False)[源]
返回来自[57]的高斯Gromov-Wasserstein值。
该函数返回在假设OT计划也为高斯时,两种高斯分布之间的高斯Gromov-Wasserstein距离的闭式解
\(\mathcal{N}(\mu_s,\Sigma_s)\) 和 \(\mathcal{N}(\mu_t,\Sigma_t)\) . 更多细节请参见 [57] 定理 4.1。- Parameters:
Cov_s (类数组 (ds,ds)) – 源分布的协方差
Cov_t (类数组 (dt,dt)) – 目标分布的协方差
- Returns:
G – 高斯Gromov-Wasserstein距离
- Return type:
参考文献
高斯分布之间的距离。《应用概率杂志》,59(4),1178-1198。
- ot.gaussian.gaussian_gromov_wasserstein_mapping(mu_s, mu_t, Cov_s, Cov_t, sign_eigs=None, log=False)[源]
返回来自 [57] 的高斯 Gromov-Wasserstein 映射。
该函数返回两个高斯分布之间的高斯Gromov-Wasserstein映射的闭式值 \(\mathcal{N}(\mu_s,\Sigma_s)\) 和 \(\mathcal{N}(\mu_t,\Sigma_t)\) 当OT计划也假设为高斯时。详见[57]定理4.1。
- Parameters:
mu_s (类数组 (ds,)) – 源分布的均值
mu_t (数组类型 (dt,)) – 目标分布的均值
Cov_s (类数组 (ds,ds)) – 源分布的协方差
Cov_t (类数组 (dt,dt)) – 目标分布的协方差
log (bool, 可选) – 如果为真,则记录日志
- Returns:
A ((dt, ds) 类数组) – 线性算子
b ((1, dt) 类数组) – 偏差
参考文献
高斯分布之间的距离。《应用概率杂志》,59(4),1178-1198。
- ot.gaussian.bures_wasserstein_barycenter(m, C, weights=None, num_iter=1000, eps=1e-07, log=False)[源]
返回样本之间的OT线性算子。
该函数估计经验分布的最佳重心。这相当于解决不动点
多个高斯分布的算法 \(\left{\mathcal{N}(\mu,\Sigma)\right}_{i=1}^n\)
[1]。
重心仍然遵循高斯分布 \(\mathcal{N}(\mu_b,\Sigma_b)\),其中:
\[\mu_b = \sum_{i=1}^n w_i \mu_i\]广义重心协方差是以下定点算法的解:
\[\Sigma_b = \sum_{i=1}^n w_i \left(\Sigma_b^{1/2}\Sigma_i^{1/2}\Sigma_b^{1/2}\right)^{1/2}\]- Parameters:
- Returns:
mb ((d,) 类数组) – 重心的均值
Cb ((d, d) 类数组) – 重心的协方差
log (字典) – 仅在参数中log==True时返回日志字典
参考文献
- ot.gaussian.bures_wasserstein_distance(ms, mt, Cs, Ct, log=False)[源]
返回样本之间的Bures Wasserstein距离。
该函数估计了两个经验分布源 \(\mu_s\) 和目标 \(\mu_t\) 之间的Bures-Wasserstein距离,在备注2.31 [1] 中讨论。
源分布和目标分布之间的Bures Wasserstein距离 \(\mathcal{W}\)
\[\mathcal{W}(\mu_s, \mu_t)_2^2= \left\lVert \mathbf{m}_s - \mathbf{m}_t \right\rVert^2 + \mathcal{B}(\Sigma_s, \Sigma_t)^{2}\]其中 :
\[\mathbf{B}(\Sigma_s, \Sigma_t)^{2} = \text{Tr}\left(\Sigma_s + \Sigma_t - 2 \sqrt{\Sigma_s^{1/2}\Sigma_t\Sigma_s^{1/2}} \right)\]- Parameters:
ms (类数组 (d,)) – 源分布的均值
mt (类似数组 (d,)) – 目标分布的均值
Cs (类数组 (d,d)) – 源分布的协方差
Ct (类数组 (d,d)) – 目标分布的协方差
log (bool, 可选) – 如果为真,则记录日志
- Returns:
W (float) – Bures Wasserstein 距离
log (dict) – 仅在参数中 log==True 时返回日志字典
参考文献
- ot.gaussian.bures_wasserstein_mapping(ms, mt, Cs, Ct, log=False)[源]
返回样本之间的OT线性算子。
该函数估计对齐两个经验分布的最优线性算子。这等价于估计两个高斯分布之间的封闭形式映射 \(\mathcal{N}(\mu_s,\Sigma_s)\) 和 \(\mathcal{N}(\mu_t,\Sigma_t)\),如[1]中所提出,并在[2]的备注2.29中讨论。
从源到目标的线性算子 \(M\)
\[M(\mathbf{x})= \mathbf{A} \mathbf{x} + \mathbf{b}\]其中 :
\[ \begin{align}\begin{aligned}\mathbf{A} &= \Sigma_s^{-1/2} \left(\Sigma_s^{1/2}\Sigma_t\Sigma_s^{1/2} \right)^{1/2} \Sigma_s^{-1/2}\\\mathbf{b} &= \mu_t - \mathbf{A} \mu_s\end{aligned}\end{align} \]- Parameters:
ms (类数组 (d,)) – 源分布的均值
mt (类似数组 (d,)) – 目标分布的均值
Cs (类数组 (d,d)) – 源分布的协方差
Ct (类数组 (d,d)) – 目标分布的协方差
log (bool, 可选) – 如果为真,则记录日志
- Returns:
A ((d, d) 数组-like) – 线性算子
b ((1, d) 数组-like) – 偏差
log (字典) – 仅在参数中log==True时返回日志字典
参考文献
- ot.gaussian.empirical_bures_wasserstein_barycenter(X, reg=1e-06, weights=None, num_iter=1000, eps=1e-07, w=None, bias=True, log=False)[源]
返回样本之间的OT线性算子。
该函数估计经验分布的最优重心。这等同于求解不动点
多重高斯分布的算法 \(\left{\mathcal{N}(\mu,\Sigma)\right}_{i=1}^n\)
[1]。
重心仍然遵循高斯分布 \(\mathcal{N}(\mu_b,\Sigma_b)\),其中:
\[\mu_b = \sum_{i=1}^n w_i \mu_i\]广义重心协方差是以下定点算法的解:
\[\Sigma_b = \sum_{i=1}^n w_i \left(\Sigma_b^{1/2}\Sigma_i^{1/2}\Sigma_b^{1/2}\right)^{1/2}\]- Parameters:
- Returns:
mb ((d,) 类数组) – 重心的均值
Cb ((d, d) 类数组) – 重心的协方差
log (字典) – 仅在参数中log==True时返回日志字典
参考文献
- ot.gaussian.empirical_bures_wasserstein_distance(xs, xt, reg=1e-06, ws=None, wt=None, bias=True, log=False)[源]
返回分布的均值和协方差的Bures Wasserstein距离。
该函数估计了两个经验分布源 \(\mu_s\) 和目标 \(\mu_t\) 之间的Bures-Wasserstein距离,在备注2.31 [1] 中讨论。
源分布和目标分布之间的Bures Wasserstein距离 \(\mathcal{W}\)
\[\mathcal{W}(\mu_s, \mu_t)_2^2= \left\lVert \mathbf{m}_s - \mathbf{m}_t \right\rVert^2 + \mathcal{B}(\Sigma_s, \Sigma_t)^{2}\]其中 :
\[\mathbf{B}(\Sigma_s, \Sigma_t)^{2} = \text{Tr}\left(\Sigma_s + \Sigma_t - 2 \sqrt{\Sigma_s^{1/2}\Sigma_t\Sigma_s^{1/2}} \right)\]- Parameters:
- Returns:
W (float) – Bures Wasserstein 距离
log (dict) – 仅在参数中 log==True 时返回日志字典
参考文献
- ot.gaussian.empirical_bures_wasserstein_mapping(xs, xt, reg=1e-06, ws=None, wt=None, bias=True, log=False)[源]
返回样本之间的OT线性算子。
该函数估计对齐两个经验分布的最优线性算子。这等价于估计两个高斯分布之间的封闭形式映射 \(\mathcal{N}(\mu_s,\Sigma_s)\) 和 \(\mathcal{N}(\mu_t,\Sigma_t)\),如[1]中所提出,并在[2]的备注2.29中讨论。
从源到目标的线性算子 \(M\)
\[M(\mathbf{x})= \mathbf{A} \mathbf{x} + \mathbf{b}\]其中 :
\[ \begin{align}\begin{aligned}\mathbf{A} &= \Sigma_s^{-1/2} \left(\Sigma_s^{1/2}\Sigma_t\Sigma_s^{1/2} \right)^{1/2} \Sigma_s^{-1/2}\\\mathbf{b} &= \mu_t - \mathbf{A} \mu_s\end{aligned}\end{align} \]- Parameters:
- Returns:
A ((d, d) 数组-like) – 线性算子
b ((1, d) 数组-like) – 偏差
log (字典) – 仅在参数中log==True时返回日志字典
参考文献
- ot.gaussian.empirical_gaussian_gromov_wasserstein_distance(xs, xt, ws=None, wt=None, log=False)[源]
返回样本之间的高斯Gromov-Wasserstein距离。
该函数估计两个高斯分布源 \(\mu_s\) 和目标 \(\mu_t\) 之间的高斯Gromov-Wasserstein距离,其参数是从提供的样本 \(\mathcal{X}_s\) 和 \(\mathcal{X}_t\) 中估计的。有关更多细节,请参见[57] 定理4.1。
- Parameters:
xs (类似数组 (ns,d)) – 源领域中的样本
xt (类数组 (nt,d)) – 目标领域中的样本
ws (array-like (ns,1), 可选) – 源样本的权重
wt (类似数组 (ns,1), 可选) – 目标样本的权重
log (bool, 可选) – 如果为真,则记录日志
- Returns:
G – 高斯Gromov-Wasserstein距离
- Return type:
参考文献
高斯分布之间的距离。《应用概率杂志》,59(4),1178-1198。
- ot.gaussian.empirical_gaussian_gromov_wasserstein_mapping(xs, xt, ws=None, wt=None, sign_eigs=None, log=False)[源]
返回样本之间的高斯Gromov-Wasserstein映射。
该函数估计两个高斯分布源 \(\mu_s\) 和目标 \(\mu_t\) 之间的高斯 Gromov-Wasserstein 映射,其参数是从提供的样本 \(\mathcal{X}_s\) 和 \(\mathcal{X}_t\) 中估算得出的。详见 [57] 定理 4.1。
- Parameters:
xs (类似数组 (ns,ds)) – 源领域中的样本
xt (类似数组 (nt,dt)) – 目标领域中的样本
ws (array-like (ns,1), 可选) – 源样本的权重
wt (类似数组 (ns,1), 可选) – 目标样本的权重
sign_eigs (array-like (min(ds,dt),) 或 string, 可选) – 映射矩阵的特征值的符号,默认情况下所有符号将为正。如果提供了‘skewness’,特征值的符号将选择为投影数据的偏斜度的符号的乘积。
log (bool, 可选) – 如果为真,则记录日志
- Returns:
A ((dt, ds) 类数组) – 线性算子
b ((1, dt) 类数组) – 偏置
.. _references-empirical_gaussian_gromov_wasserstein_mapping
参考文献
高斯分布之间的距离。《应用概率杂志》,59(4),1178-1198。
- ot.gaussian.gaussian_gromov_wasserstein_distance(Cov_s, Cov_t, log=False)[源]
返回来自[57]的高斯Gromov-Wasserstein值。
该函数返回在假设OT计划也为高斯时,两种高斯分布之间的高斯Gromov-Wasserstein距离的闭式解
\(\mathcal{N}(\mu_s,\Sigma_s)\) 和 \(\mathcal{N}(\mu_t,\Sigma_t)\) . 更多细节请参见 [57] 定理 4.1。- Parameters:
Cov_s (类数组 (ds,ds)) – 源分布的协方差
Cov_t (类数组 (dt,dt)) – 目标分布的协方差
- Returns:
G – 高斯Gromov-Wasserstein距离
- Return type:
参考文献
高斯分布之间的距离。《应用概率杂志》,59(4),1178-1198。
- ot.gaussian.gaussian_gromov_wasserstein_mapping(mu_s, mu_t, Cov_s, Cov_t, sign_eigs=None, log=False)[源]
返回来自 [57] 的高斯 Gromov-Wasserstein 映射。
该函数返回两个高斯分布之间的高斯Gromov-Wasserstein映射的闭式值 \(\mathcal{N}(\mu_s,\Sigma_s)\) 和 \(\mathcal{N}(\mu_t,\Sigma_t)\) 当OT计划也假设为高斯时。详见[57]定理4.1。
- Parameters:
mu_s (类数组 (ds,)) – 源分布的均值
mu_t (数组类型 (dt,)) – 目标分布的均值
Cov_s (类数组 (ds,ds)) – 源分布的协方差
Cov_t (类数组 (dt,dt)) – 目标分布的协方差
log (bool, 可选) – 如果为真,则记录日志
- Returns:
A ((dt, ds) 类数组) – 线性算子
b ((1, dt) 类数组) – 偏差
参考文献
高斯分布之间的距离。《应用概率杂志》,59(4),1178-1198。