ot.stochastic
用于正则化OT的随机求解器。
函数
- ot.stochastic.averaged_sgd_entropic_transport(a, b, M, reg, numItermax=300000, lr=None, random_state=None)[源]
计算ASGD算法以解决正则化半连续度量最优运输最大化问题
该函数解决以下优化问题:
\[ \begin{align}\begin{aligned}\gamma = \mathop{\arg \min}_\gamma \quad \langle \gamma, \mathbf{M} \rangle_F + \mathrm{reg}\cdot\Omega(\gamma)\\\text{使得 } \gamma \mathbf{1} = \mathbf{a}\\ \gamma^T \mathbf{1} = \mathbf{b}\\ \gamma \geq 0\end{aligned}\end{align} \]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\Omega\) 是熵正则化项,\(\Omega(\gamma)=\sum_{i,j} \gamma_{i,j}\log(\gamma_{i,j})\)
\(\mathbf{a}\) 和 \(\mathbf{b}\) 是源权重和目标权重(总和为1)
用于解决问题的算法是ASGD算法,如在[18] [alg.2]中提出的
- Parameters:
- Returns:
ave_v (ndarray, 形状 (nt,)) – 对偶变量
.. _references-averaged-sgd-entropic-transport
参考文献
- ot.stochastic.batch_grad_dual(a, b, M, reg, alpha, beta, batch_size, batch_alpha, batch_beta)[源]
计算对偶最优传输问题的部分梯度。
对于每个 \((i,j)\) 在一批坐标中,偏导数为:
\[ \begin{align}\begin{aligned}\partial_{\mathbf{u}_i} F = \frac{b_s}{l_v} \mathbf{u}_i - \sum_{j \in B_v} \mathbf{a}_i \mathbf{b}_j \exp\left( \frac{\mathbf{u}_i + \mathbf{v}_j - \mathbf{M}_{i,j}}{\mathrm{reg}} \right)\\\partial_{\mathbf{v}_j} F = \frac{b_s}{l_u} \mathbf{v}_j - \sum_{i \in B_u} \mathbf{a}_i \mathbf{b}_j \exp\left( \frac{\mathbf{u}_i + \mathbf{v}_j - \mathbf{M}_{i,j}}{\mathrm{reg}} \right)\end{aligned}\end{align} \]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\mathbf{u}\), \(\mathbf{v}\) 是\(\mathbb{R}^{ns} \times \mathbb{R}^{nt}\)中的对偶变量
reg是正则化项
\(B_u\) 和 \(B_v\) 是索引列表
\(b_s\) 是批次的大小 \(B_u\) 和 \(B_v\)
\(l_u\) 和 \(l_v\) 是 \(B_u\) 和 \(B_v\) 的长度
\(\mathbf{a}\) 和 \(\mathbf{b}\) 是源权重和目标权重(总和为1)
用于解决对偶问题的算法是SGD算法,如[19] [alg.1]中所提到的
- Parameters:
a (ndarray, shape (ns,)) – 源测量
b (ndarray, shape (nt,)) – 目标度量
M (ndarray, shape (ns, nt)) – 成本矩阵
reg (float) – 正则化项 > 0
alpha (ndarray, shape (ns,)) – 对偶变量
beta (ndarray, shape (nt,)) – 对偶变量
batch_size (int) – 批次大小
batch_alpha (ndarray, shape (bs,)) – alpha的索引批次
batch_beta (ndarray, shape (bs,)) – beta的索引批次
- Returns:
grad (ndarray, shape (ns,)) – 部分梯度 F
.. _references-batch-grad-dual
参考文献
- ot.stochastic.c_transform_entropic(b, M, reg, beta)[源]
目标是从c变换中恢复u。
该函数计算来自另一个对偶变量的对偶变量的c变换:
\[\mathbf{u} = \mathbf{v}^{c,reg} = - \mathrm{reg} \sum_j \mathbf{b}_j \exp\left( \frac{\mathbf{v} - \mathbf{M}}{\mathrm{reg}} \right)\]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\mathbf{u}\), \(\mathbf{v}\) 是\(\mathbb{R}^{ns} \times \mathbb{R}^{nt}\)中的对偶变量
reg是正则化项
它用于从最优 v 中恢复最优 u,解决半对偶问题,参见[18]的命题 2.1
- Parameters:
b (ndarray, shape (nt,)) – 目标测量
M (ndarray, shape (ns, nt)) – 成本矩阵
reg (float) – 正则化项 > 0
v (ndarray, shape (nt,)) – 对偶变量。
- Returns:
u (ndarray, shape (ns,)) – 对偶变量。
.. _references-c-transform-entropic
参考文献
- ot.stochastic.coordinate_grad_semi_dual(b, M, reg, beta, i)[源]
计算正则化离散分布的坐标梯度更新,对于 \((i, :)\)
该函数计算半对偶问题的梯度:
\[\max_\mathbf{v} \ \sum_i \mathbf{a}_i \left[ \sum_j \mathbf{v}_j \mathbf{b}_j - \mathrm{reg} \cdot \log \left( \sum_j \mathbf{b}_j \exp \left( \frac{\mathbf{v}_j - \mathbf{M}_{i,j}}{\mathrm{reg}} \right) \right) \right]\]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\mathbf{v}\) 是 \(\mathbb{R}^{nt}\) 中的一个对偶变量
reg是正则化项
\(\mathbf{a}\) 和 \(\mathbf{b}\) 是源权重和目标权重(总和为1)
用于解决该问题的算法是ASGD和SAG算法,如[18]所提及 [alg.1 & alg.2]
- Parameters:
- Returns:
坐标梯度 (ndarray, shape (nt,))
.. _references-coordinate-grad-semi-dual
参考文献
- ot.stochastic.loss_dual_entropic(u, v, xs, xt, reg=1, ws=None, wt=None, metric='sqeuclidean')[源]
计算熵最优传输的对偶损失,如[19]中的公式(6)-(7)所示
该损失是后端兼容的,可以用于双潜在变量的随机优化。它可以在完整数据集上使用(注意内存)或在小批量上使用。
- Parameters:
u (类数组, 形状 (ns,)) – 源双势能
v (类似数组, 形状 (nt,)) – 目标双潜力
xs (类数组, 形状 (ns,d)) – 源样本
xt (类数组, 形状 (ns,d)) – 目标样本
reg (float) – 正则化项 > 0 (默认=1)
ws (类数组, 形状 (ns,), 可选) – 源样本权重(默认均匀)
wt (类似数组, 形状 (ns,), 可选) – 目标样本权重(默认均匀)
metric (字符串, 可调用) – OT的基础度量(默认是二次距)。可以作为一个可调用函数传入,接受 (xs,xt) 作为参数。
- Returns:
dual_loss – 双重损失(待最大化)
- Return type:
类似数组
参考文献
使用 ot.stochastic.loss_dual_entropic 的示例
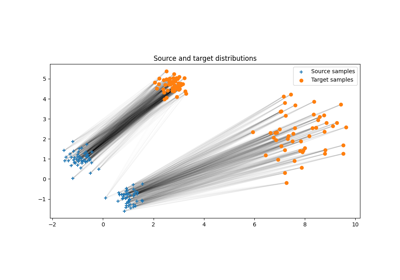
- ot.stochastic.loss_dual_quadratic(u, v, xs, xt, reg=1, ws=None, wt=None, metric='sqeuclidean')[源]
计算二次正则化OT的对偶损失,如[19]中的公式(6)-(7)所示
该损失是后端兼容的,可以用于双潜在变量的随机优化。它可以在完整数据集上使用(注意内存)或在小批量上使用。
- Parameters:
u (类数组, 形状 (ns,)) – 源双势能
v (类似数组, 形状 (nt,)) – 目标双潜力
xs (类数组, 形状 (ns,d)) – 源样本
xt (类数组, 形状 (ns,d)) – 目标样本
reg (float) – 正则化项 > 0 (默认=1)
ws (类数组, 形状 (ns,), 可选) – 源样本权重(默认均匀)
wt (类似数组, 形状 (ns,), 可选) – 目标样本权重(默认均匀)
metric (字符串, 可调用) – OT的基础度量(默认是二次距)。可以作为一个可调用函数传入,接受 (xs,xt) 作为参数。
- Returns:
dual_loss – 双重损失(待最大化)
- Return type:
类似数组
参考文献
使用 ot.stochastic.loss_dual_quadratic
- ot.stochastic.plan_dual_entropic(u, v, xs, xt, reg=1, ws=None, wt=None, metric='sqeuclidean')[源]
计算原始OT计划与方程(8)中的熵OT [19]相同
该损失是后端兼容的,可以用于双潜在变量的随机优化。它可以在完整数据集上使用(注意内存)或在小批量上使用。
- Parameters:
u (类数组, 形状 (ns,)) – 源双势能
v (类似数组, 形状 (nt,)) – 目标双潜力
xs (类数组, 形状 (ns,d)) – 源样本
xt (类数组, 形状 (ns,d)) – 目标样本
reg (float) – 正则化项 > 0 (默认=1)
ws (类数组, 形状 (ns,), 可选) – 源样本权重(默认均匀)
wt (类似数组, 形状 (ns,), 可选) – 目标样本权重(默认均匀)
metric (字符串, 可调用) – OT的基础度量(默认是二次距)。可以作为一个可调用函数传入,接受 (xs,xt) 作为参数。
- Returns:
G – 原始OT计划
- Return type:
类似数组
参考文献
使用 ot.stochastic.plan_dual_entropic 的示例
- ot.stochastic.plan_dual_quadratic(u, v, xs, xt, reg=1, ws=None, wt=None, metric='sqeuclidean')[源]
计算如[19]中公式(8)所示的主OT计划的二次正则化OT
该损失是后端兼容的,可以用于双潜在变量的随机优化。它可以在完整数据集上使用(注意内存)或在小批量上使用。
- Parameters:
u (类数组, 形状 (ns,)) – 源双势能
v (类似数组, 形状 (nt,)) – 目标双潜力
xs (类数组, 形状 (ns,d)) – 源样本
xt (类数组, 形状 (ns,d)) – 目标样本
reg (float) – 正则化项 > 0 (默认=1)
ws (类数组, 形状 (ns,), 可选) – 源样本权重(默认均匀)
wt (类似数组, 形状 (ns,), 可选) – 目标样本权重(默认均匀)
metric (字符串, 可调用) – OT的基础度量(默认是二次距)。可以作为一个可调用函数传入,接受 (xs,xt) 作为参数。
- Returns:
G – 原始OT计划
- Return type:
类似数组
参考文献
使用 ot.stochastic.plan_dual_quadratic 的示例
- ot.stochastic.sag_entropic_transport(a, b, M, reg, numItermax=10000, lr=None, random_state=None)[源]
计算SAG算法以解决规则化离散度量最优运输最大问题
该函数解决以下优化问题:
\[ \begin{align}\begin{aligned}\gamma = \mathop{\arg \min}_\gamma \quad \langle \gamma, \mathbf{M} \rangle_F + \mathrm{reg} \cdot\Omega(\gamma)\\s.t. \ \gamma \mathbf{1} = \mathbf{a}\\ \gamma^T \mathbf{1} = \mathbf{b}\\ \gamma \geq 0\end{aligned}\end{align} \]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\Omega\) 是熵正则化项,\(\Omega(\gamma)=\sum_{i,j} \gamma_{i,j}\log(\gamma_{i,j})\)
\(\mathbf{a}\) 和 \(\mathbf{b}\) 是源权重和目标权重(总和为1)
用于解决问题的算法是SAG算法,如在[18] [alg.1]中提出的。
- Parameters:
- Returns:
v (ndarray, shape (nt,)) – 对偶变量。
.. _references-sag-entropic-transport
参考文献
- ot.stochastic.sgd_entropic_regularization(a, b, M, reg, batch_size, numItermax, lr, random_state=None)[源]
计算sgd算法以解决正则化离散度量最优传输对偶问题
该函数解决以下优化问题:
\[ \begin{align}\begin{aligned}\gamma = \mathop{\arg \min}_\gamma \quad \langle \gamma, \mathbf{M} \rangle_F + \mathrm{reg} \cdot\Omega(\gamma)\\s.t. \ \gamma \mathbf{1} = \mathbf{a}\\ \gamma^T \mathbf{1} = \mathbf{b}\\ \gamma \geq 0\end{aligned}\end{align} \]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\Omega\) 是熵正则化项,\(\Omega(\gamma)=\sum_{i,j} \gamma_{i,j}\log(\gamma_{i,j})\)
\(\mathbf{a}\) 和 \(\mathbf{b}\) 是源权重和目标权重(总和为1)
- Parameters:
- Returns:
alpha (ndarray, shape (ns,)) – 对偶变量
beta (ndarray, shape (nt,)) – 对偶变量
参考文献
- ot.stochastic.solve_dual_entropic(a, b, M, reg, batch_size, numItermax=10000, lr=1, log=False)[源]
计算运输矩阵以解决正则化离散测度的最优运输对偶问题
该函数解决以下优化问题:
\[ \begin{align}\begin{aligned}\gamma = \mathop{\arg \min}_\gamma \quad \langle \gamma, \mathbf{M} \rangle_F + \mathrm{reg} \cdot\Omega(\gamma)\\s.t. \ \gamma \mathbf{1} = \mathbf{a}\\ \gamma^T \mathbf{1} = \mathbf{b}\\ \gamma \geq 0\end{aligned}\end{align} \]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\Omega\) 是熵正则化项,\(\Omega(\gamma)=\sum_{i,j} \gamma_{i,j}\log(\gamma_{i,j})\)
\(\mathbf{a}\) 和 \(\mathbf{b}\) 是源权重和目标权重(总和为1)
- Parameters:
- Returns:
pi (ndarray, shape (ns, nt)) – 运输矩阵
log (dict) – 日志字典,仅在参数中log==True时返回
参考文献
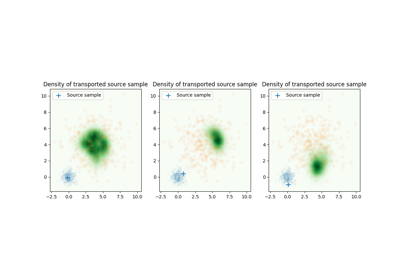
使用 ot.stochastic.solve_dual_entropic 的示例
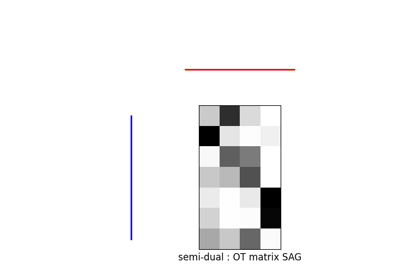
- ot.stochastic.solve_semi_dual_entropic(a, b, M, reg, method, numItermax=10000, lr=None, log=False)[源]
计算运输矩阵以解决正则化离散度量最优运输最大化问题
该函数解决以下优化问题:
\[ \begin{align}\begin{aligned}\gamma = \mathop{\arg \min}_\gamma \quad \langle \gamma, \mathbf{M} \rangle_F + \mathrm{reg} \cdot\Omega(\gamma)\\s.t. \ \gamma \mathbf{1} = \mathbf{a}\\ \gamma^T \mathbf{1} = \mathbf{b}\\ \gamma \geq 0\end{aligned}\end{align} \]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\Omega\) 是熵正则化项,\(\Omega(\gamma)=\sum_{i,j} \gamma_{i,j}\log(\gamma_{i,j})\)
\(\mathbf{a}\) 和 \(\mathbf{b}\) 是源权重和目标权重(总和为1)
用于解决该问题的算法是SAG或ASGD算法,如[18]中所提到的
- Parameters:
- Returns:
pi (ndarray, shape (ns, nt)) – 运输矩阵
log (dict) – 日志字典,仅在参数中log==True时返回
.. _references-solve-semi-dual-entropic
参考文献
使用 ot.stochastic.solve_semi_dual_entropic 的示例
- ot.stochastic.averaged_sgd_entropic_transport(a, b, M, reg, numItermax=300000, lr=None, random_state=None)[源]
计算ASGD算法以解决正则化半连续度量最优运输最大化问题
该函数解决以下优化问题:
\[ \begin{align}\begin{aligned}\gamma = \mathop{\arg \min}_\gamma \quad \langle \gamma, \mathbf{M} \rangle_F + \mathrm{reg}\cdot\Omega(\gamma)\\\text{使得 } \gamma \mathbf{1} = \mathbf{a}\\ \gamma^T \mathbf{1} = \mathbf{b}\\ \gamma \geq 0\end{aligned}\end{align} \]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\Omega\) 是熵正则化项,\(\Omega(\gamma)=\sum_{i,j} \gamma_{i,j}\log(\gamma_{i,j})\)
\(\mathbf{a}\) 和 \(\mathbf{b}\) 是源权重和目标权重(总和为1)
用于解决问题的算法是ASGD算法,如在[18] [alg.2]中提出的
- Parameters:
- Returns:
ave_v (ndarray, 形状 (nt,)) – 对偶变量
.. _references-averaged-sgd-entropic-transport
参考文献
- ot.stochastic.batch_grad_dual(a, b, M, reg, alpha, beta, batch_size, batch_alpha, batch_beta)[源]
计算对偶最优传输问题的部分梯度。
对于每个 \((i,j)\) 在一批坐标中,偏导数为:
\[ \begin{align}\begin{aligned}\partial_{\mathbf{u}_i} F = \frac{b_s}{l_v} \mathbf{u}_i - \sum_{j \in B_v} \mathbf{a}_i \mathbf{b}_j \exp\left( \frac{\mathbf{u}_i + \mathbf{v}_j - \mathbf{M}_{i,j}}{\mathrm{reg}} \right)\\\partial_{\mathbf{v}_j} F = \frac{b_s}{l_u} \mathbf{v}_j - \sum_{i \in B_u} \mathbf{a}_i \mathbf{b}_j \exp\left( \frac{\mathbf{u}_i + \mathbf{v}_j - \mathbf{M}_{i,j}}{\mathrm{reg}} \right)\end{aligned}\end{align} \]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\mathbf{u}\), \(\mathbf{v}\) 是\(\mathbb{R}^{ns} \times \mathbb{R}^{nt}\)中的对偶变量
reg是正则化项
\(B_u\) 和 \(B_v\) 是索引列表
\(b_s\) 是批次的大小 \(B_u\) 和 \(B_v\)
\(l_u\) 和 \(l_v\) 是 \(B_u\) 和 \(B_v\) 的长度
\(\mathbf{a}\) 和 \(\mathbf{b}\) 是源权重和目标权重(总和为1)
用于解决对偶问题的算法是SGD算法,如[19] [alg.1]中所提到的
- Parameters:
a (ndarray, shape (ns,)) – 源测量
b (ndarray, shape (nt,)) – 目标度量
M (ndarray, shape (ns, nt)) – 成本矩阵
reg (float) – 正则化项 > 0
alpha (ndarray, shape (ns,)) – 对偶变量
beta (ndarray, shape (nt,)) – 对偶变量
batch_size (int) – 批次大小
batch_alpha (ndarray, shape (bs,)) – alpha的索引批次
batch_beta (ndarray, shape (bs,)) – beta的索引批次
- Returns:
grad (ndarray, shape (ns,)) – 部分梯度 F
.. _references-batch-grad-dual
参考文献
- ot.stochastic.c_transform_entropic(b, M, reg, beta)[源]
目标是从c变换中恢复u。
该函数计算来自另一个对偶变量的对偶变量的c变换:
\[\mathbf{u} = \mathbf{v}^{c,reg} = - \mathrm{reg} \sum_j \mathbf{b}_j \exp\left( \frac{\mathbf{v} - \mathbf{M}}{\mathrm{reg}} \right)\]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\mathbf{u}\), \(\mathbf{v}\) 是\(\mathbb{R}^{ns} \times \mathbb{R}^{nt}\)中的对偶变量
reg是正则化项
它用于从最优 v 中恢复最优 u,解决半对偶问题,参见[18]的命题 2.1
- Parameters:
b (ndarray, shape (nt,)) – 目标测量
M (ndarray, shape (ns, nt)) – 成本矩阵
reg (float) – 正则化项 > 0
v (ndarray, shape (nt,)) – 对偶变量。
- Returns:
u (ndarray, shape (ns,)) – 对偶变量。
.. _references-c-transform-entropic
参考文献
- ot.stochastic.coordinate_grad_semi_dual(b, M, reg, beta, i)[源]
计算正则化离散分布的坐标梯度更新,对于 \((i, :)\)
该函数计算半对偶问题的梯度:
\[\max_\mathbf{v} \ \sum_i \mathbf{a}_i \left[ \sum_j \mathbf{v}_j \mathbf{b}_j - \mathrm{reg} \cdot \log \left( \sum_j \mathbf{b}_j \exp \left( \frac{\mathbf{v}_j - \mathbf{M}_{i,j}}{\mathrm{reg}} \right) \right) \right]\]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\mathbf{v}\) 是 \(\mathbb{R}^{nt}\) 中的一个对偶变量
reg是正则化项
\(\mathbf{a}\) 和 \(\mathbf{b}\) 是源权重和目标权重(总和为1)
用于解决该问题的算法是ASGD和SAG算法,如[18]所提及 [alg.1 & alg.2]
- Parameters:
- Returns:
坐标梯度 (ndarray, shape (nt,))
.. _references-coordinate-grad-semi-dual
参考文献
- ot.stochastic.loss_dual_entropic(u, v, xs, xt, reg=1, ws=None, wt=None, metric='sqeuclidean')[源]
计算熵最优传输的对偶损失,如[19]中的公式(6)-(7)所示
该损失是后端兼容的,可以用于双潜在变量的随机优化。它可以在完整数据集上使用(注意内存)或在小批量上使用。
- Parameters:
u (类数组, 形状 (ns,)) – 源双势能
v (类似数组, 形状 (nt,)) – 目标双潜力
xs (类数组, 形状 (ns,d)) – 源样本
xt (类数组, 形状 (ns,d)) – 目标样本
reg (float) – 正则化项 > 0 (默认=1)
ws (类数组, 形状 (ns,), 可选) – 源样本权重(默认均匀)
wt (类似数组, 形状 (ns,), 可选) – 目标样本权重(默认均匀)
metric (字符串, 可调用) – OT的基础度量(默认是二次距)。可以作为一个可调用函数传入,接受 (xs,xt) 作为参数。
- Returns:
dual_loss – 双重损失(待最大化)
- Return type:
类似数组
参考文献
- ot.stochastic.loss_dual_quadratic(u, v, xs, xt, reg=1, ws=None, wt=None, metric='sqeuclidean')[源]
计算二次正则化OT的对偶损失,如[19]中的公式(6)-(7)所示
该损失是后端兼容的,可以用于双潜在变量的随机优化。它可以在完整数据集上使用(注意内存)或在小批量上使用。
- Parameters:
u (类数组, 形状 (ns,)) – 源双势能
v (类似数组, 形状 (nt,)) – 目标双潜力
xs (类数组, 形状 (ns,d)) – 源样本
xt (类数组, 形状 (ns,d)) – 目标样本
reg (float) – 正则化项 > 0 (默认=1)
ws (类数组, 形状 (ns,), 可选) – 源样本权重(默认均匀)
wt (类似数组, 形状 (ns,), 可选) – 目标样本权重(默认均匀)
metric (字符串, 可调用) – OT的基础度量(默认是二次距)。可以作为一个可调用函数传入,接受 (xs,xt) 作为参数。
- Returns:
dual_loss – 双重损失(待最大化)
- Return type:
类似数组
参考文献
- ot.stochastic.plan_dual_entropic(u, v, xs, xt, reg=1, ws=None, wt=None, metric='sqeuclidean')[源]
计算原始OT计划与方程(8)中的熵OT [19]相同
该损失是后端兼容的,可以用于双潜在变量的随机优化。它可以在完整数据集上使用(注意内存)或在小批量上使用。
- Parameters:
u (类数组, 形状 (ns,)) – 源双势能
v (类似数组, 形状 (nt,)) – 目标双潜力
xs (类数组, 形状 (ns,d)) – 源样本
xt (类数组, 形状 (ns,d)) – 目标样本
reg (float) – 正则化项 > 0 (默认=1)
ws (类数组, 形状 (ns,), 可选) – 源样本权重(默认均匀)
wt (类似数组, 形状 (ns,), 可选) – 目标样本权重(默认均匀)
metric (字符串, 可调用) – OT的基础度量(默认是二次距)。可以作为一个可调用函数传入,接受 (xs,xt) 作为参数。
- Returns:
G – 原始OT计划
- Return type:
类似数组
参考文献
- ot.stochastic.plan_dual_quadratic(u, v, xs, xt, reg=1, ws=None, wt=None, metric='sqeuclidean')[源]
计算如[19]中公式(8)所示的主OT计划的二次正则化OT
该损失是后端兼容的,可以用于双潜在变量的随机优化。它可以在完整数据集上使用(注意内存)或在小批量上使用。
- Parameters:
u (类数组, 形状 (ns,)) – 源双势能
v (类似数组, 形状 (nt,)) – 目标双潜力
xs (类数组, 形状 (ns,d)) – 源样本
xt (类数组, 形状 (ns,d)) – 目标样本
reg (float) – 正则化项 > 0 (默认=1)
ws (类数组, 形状 (ns,), 可选) – 源样本权重(默认均匀)
wt (类似数组, 形状 (ns,), 可选) – 目标样本权重(默认均匀)
metric (字符串, 可调用) – OT的基础度量(默认是二次距)。可以作为一个可调用函数传入,接受 (xs,xt) 作为参数。
- Returns:
G – 原始OT计划
- Return type:
类似数组
参考文献
- ot.stochastic.sag_entropic_transport(a, b, M, reg, numItermax=10000, lr=None, random_state=None)[源]
计算SAG算法以解决规则化离散度量最优运输最大问题
该函数解决以下优化问题:
\[ \begin{align}\begin{aligned}\gamma = \mathop{\arg \min}_\gamma \quad \langle \gamma, \mathbf{M} \rangle_F + \mathrm{reg} \cdot\Omega(\gamma)\\s.t. \ \gamma \mathbf{1} = \mathbf{a}\\ \gamma^T \mathbf{1} = \mathbf{b}\\ \gamma \geq 0\end{aligned}\end{align} \]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\Omega\) 是熵正则化项,\(\Omega(\gamma)=\sum_{i,j} \gamma_{i,j}\log(\gamma_{i,j})\)
\(\mathbf{a}\) 和 \(\mathbf{b}\) 是源权重和目标权重(总和为1)
用于解决问题的算法是SAG算法,如在[18] [alg.1]中提出的。
- Parameters:
- Returns:
v (ndarray, shape (nt,)) – 对偶变量。
.. _references-sag-entropic-transport
参考文献
- ot.stochastic.sgd_entropic_regularization(a, b, M, reg, batch_size, numItermax, lr, random_state=None)[源]
计算sgd算法以解决正则化离散度量最优传输对偶问题
该函数解决以下优化问题:
\[ \begin{align}\begin{aligned}\gamma = \mathop{\arg \min}_\gamma \quad \langle \gamma, \mathbf{M} \rangle_F + \mathrm{reg} \cdot\Omega(\gamma)\\s.t. \ \gamma \mathbf{1} = \mathbf{a}\\ \gamma^T \mathbf{1} = \mathbf{b}\\ \gamma \geq 0\end{aligned}\end{align} \]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\Omega\) 是熵正则化项,\(\Omega(\gamma)=\sum_{i,j} \gamma_{i,j}\log(\gamma_{i,j})\)
\(\mathbf{a}\) 和 \(\mathbf{b}\) 是源权重和目标权重(总和为1)
- Parameters:
- Returns:
alpha (ndarray, shape (ns,)) – 对偶变量
beta (ndarray, shape (nt,)) – 对偶变量
参考文献
- ot.stochastic.solve_dual_entropic(a, b, M, reg, batch_size, numItermax=10000, lr=1, log=False)[源]
计算运输矩阵以解决正则化离散测度的最优运输对偶问题
该函数解决以下优化问题:
\[ \begin{align}\begin{aligned}\gamma = \mathop{\arg \min}_\gamma \quad \langle \gamma, \mathbf{M} \rangle_F + \mathrm{reg} \cdot\Omega(\gamma)\\s.t. \ \gamma \mathbf{1} = \mathbf{a}\\ \gamma^T \mathbf{1} = \mathbf{b}\\ \gamma \geq 0\end{aligned}\end{align} \]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\Omega\) 是熵正则化项,\(\Omega(\gamma)=\sum_{i,j} \gamma_{i,j}\log(\gamma_{i,j})\)
\(\mathbf{a}\) 和 \(\mathbf{b}\) 是源权重和目标权重(总和为1)
- Parameters:
- Returns:
pi (ndarray, shape (ns, nt)) – 运输矩阵
log (dict) – 日志字典,仅在参数中log==True时返回
参考文献
- ot.stochastic.solve_semi_dual_entropic(a, b, M, reg, method, numItermax=10000, lr=None, log=False)[源]
计算运输矩阵以解决正则化离散度量最优运输最大化问题
该函数解决以下优化问题:
\[ \begin{align}\begin{aligned}\gamma = \mathop{\arg \min}_\gamma \quad \langle \gamma, \mathbf{M} \rangle_F + \mathrm{reg} \cdot\Omega(\gamma)\\s.t. \ \gamma \mathbf{1} = \mathbf{a}\\ \gamma^T \mathbf{1} = \mathbf{b}\\ \gamma \geq 0\end{aligned}\end{align} \]其中:
\(\mathbf{M}\) 是 (ns, nt) 计量成本矩阵
\(\Omega\) 是熵正则化项,\(\Omega(\gamma)=\sum_{i,j} \gamma_{i,j}\log(\gamma_{i,j})\)
\(\mathbf{a}\) 和 \(\mathbf{b}\) 是源权重和目标权重(总和为1)
用于解决该问题的算法是SAG或ASGD算法,如[18]中所提到的
- Parameters:
- Returns:
pi (ndarray, shape (ns, nt)) – 运输矩阵
log (dict) – 日志字典,仅在参数中log==True时返回
.. _references-solve-semi-dual-entropic
参考文献