ot.datasets
简单示例数据集
函数
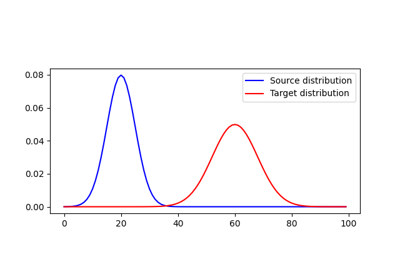
使用 ot.datasets.make_1D_gauss 的示例
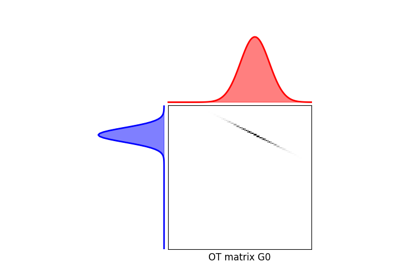
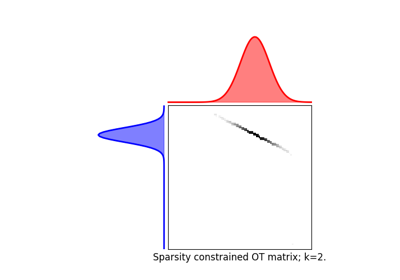

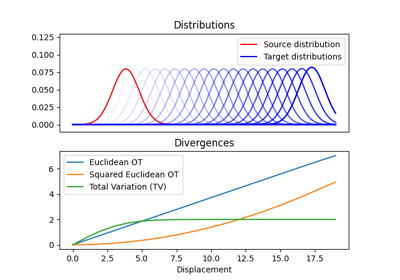
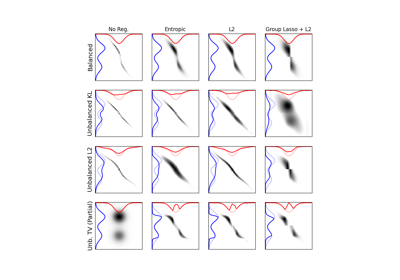
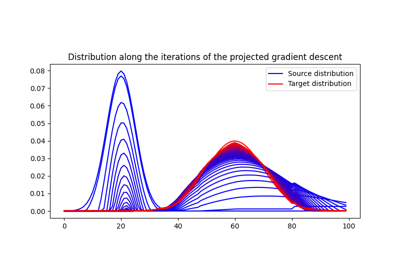
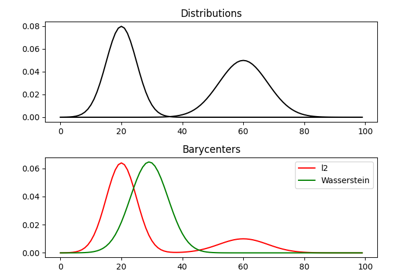

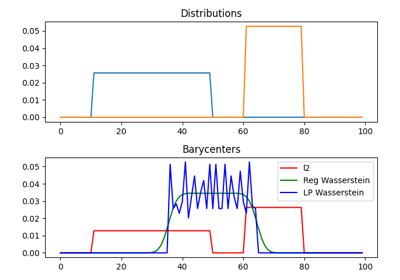

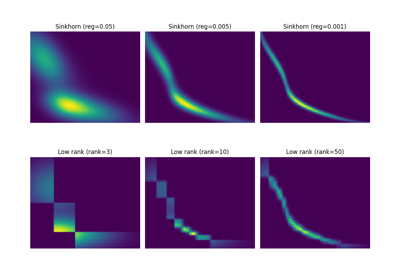
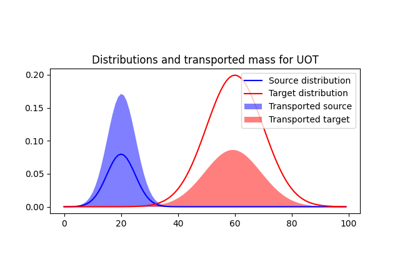
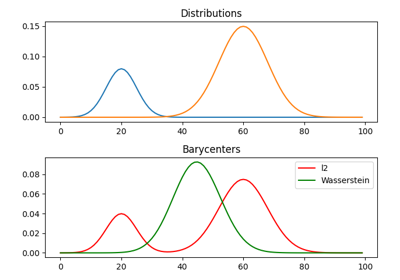
使用 ot.datasets.make_2D_samples_gauss 的示例
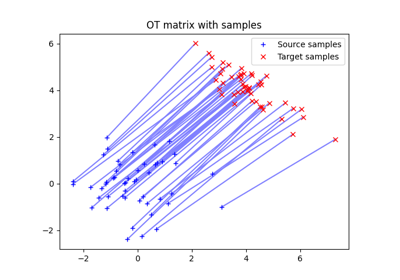


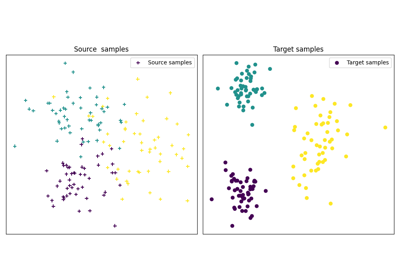
使用 ot.datasets.make_data_classif 的示例
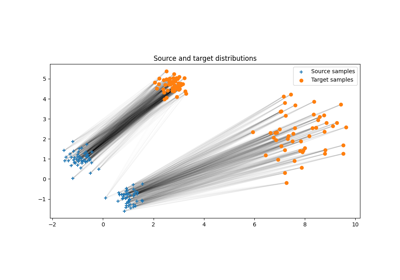
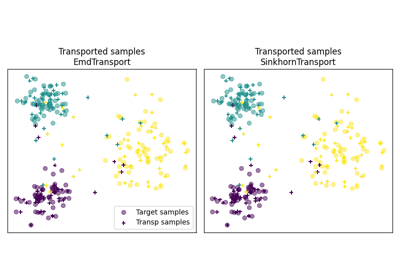

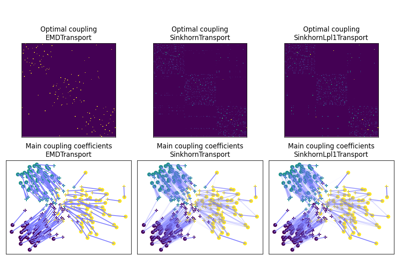
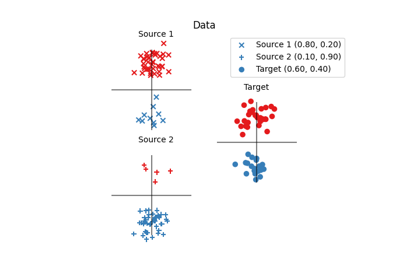
- ot.datasets.make_2D_samples_gauss(n, m, sigma, random_state=None)[源]
返回 n 个从二维高斯 \(\mathcal{N}(m, \sigma)\) 中提取的样本
- Parameters:
- Returns:
X – 从 \(\mathcal{N}(m, \sigma)\) 中抽取的 n 个样本。
- Return type:
ndarray,形状 (n, 2)