使用Li和Pearl(2019)的结果插补进行反事实价值估计
介绍
提升建模的目标通常是预测个体的最佳处理条件。大多数情况下,最佳处理条件被假定为具有最高概率的“转化事件”,例如个体购买产品。这是传统方法,其目标是最大化转化率。
然而,如果提升建模的目标是最大化价值,那么假设最佳处理组是预期转化率最高的组是不安全的。例如,可能转化带来的收益不足以抵消处理成本,或者处理针对的是那些无论如何都会转化的个体(Li and Pearl 2019)。因此,通常重要的是在进行提升建模的同时进行某种价值优化,以确定具有最佳价值的处理组,而不仅仅是最大的提升。
Causal ML 包包含 CounterfactualValueEstimator 类,用于进行基于简单插补的价值优化。本笔记本演示了如何使用 CounterfactualValueEstimator 在考虑治疗成本的情况下确定最佳治疗组。我们考虑两种成本:
转换成本是指如果处于治疗组的个体发生转换,我们必须承担的成本。一个典型的例子是促销券的成本。
印象成本是指我们需要为治疗组中的每个人支付的费用,无论他们是否转化。一个典型的例子是与发送短信或电子邮件相关的成本。
所提出的方法接受两个输入:由任何合适方法学习的CATE估计\(\hat{\tau}\),以及由我们称为转换概率模型学习的个体预测结果,该模型估计转换的条件概率\(P(Y=1 \mid X=x, W=x)\),其中\(W\)是治疗组指示器。也就是说,该模型使用每个个体观察到的治疗前特征\(X\)来估计每个个体的转换概率。然后,该模型的输出与预测的CATE结合,以便在\textit{每个治疗条件下}为每个个体估算预期的转换概率,如下所示:
:nbsphinx-math:`begin{equation} \hat{Y}_i^0 =
begin{cases} \hat{m}(X_i, W_i) & \text{当 } W_i = 0 \ \hat{m}(X_i, W_i) - \hat{\tau}_t(X_i) & \text{当 } W_i = t \ \end{cases}
结束{equation}`
:nbsphinx-math:`begin{equation} \hat{Y}_i^t =
begin{cases} \hat{m}(X_i, W_i) + \hat{\tau}_t(X_i) & \text{当 } W_i = 0 \text{ 时} \\ \hat{m}(X_i, W_i) & \text{当 } W_i = t \text{ 时} \\ \end{cases}
结束{equation}`
我们根据每个实验条件(实际的和反事实的)推算转化概率,这为我们的方法命名。使用估计的转化概率,我们然后计算每个处理条件下的预期收益,同时考虑到转化的价值以及与每个处理相关的转化和展示成本,如下所示(详见Zhao和Harinen(2019)了解更多详情):
- :nbsphinx-math:`begin{equation}
mathbb{E}[(v - cc_t)Y_t - ic_t]
结束{equation}`
其中 \(cc_t\) 和 \(ic_t\) 分别是转化成本和展示成本。
[2]:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import xgboost as xgb
from causalml.dataset import make_uplift_classification
from causalml.inference.meta import BaseTClassifier
from causalml.optimize import CounterfactualValueEstimator
from causalml.optimize import get_treatment_costs
from causalml.optimize import get_actual_value
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
%matplotlib inline
The sklearn.utils.testing module is deprecated in version 0.22 and will be removed in version 0.24. The corresponding classes / functions should instead be imported from sklearn.utils. Anything that cannot be imported from sklearn.utils is now part of the private API.
sklearn.tree._criterion.RegressionCriterion size changed, may indicate binary incompatibility. Expected 168 from C header, got 360 from PyObject
sklearn.tree._criterion.Criterion size changed, may indicate binary incompatibility. Expected 160 from C header, got 352 from PyObject
sklearn.tree._criterion.ClassificationCriterion size changed, may indicate binary incompatibility. Expected 176 from C header, got 368 from PyObject
数据生成
首先,我们使用内置函数模拟一些异质性处理数据。
[3]:
df, X_names = make_uplift_classification(
n_samples=5000, treatment_name=['control', 'treatment1', 'treatment2'])
在这个例子中,我们假设将单位分配到控制组没有相关成本,而对于两个处理组,转换成本分别为\$2.5和\$5。我们假设其中一个处理的展示成本为零,另一个为\$0.02。我们还指定了收益,这里我们假设每个人的收益相同,为\$20。然而,这些值可能因人而异。
[4]:
# Put costs into dicts
conversion_cost_dict = {'control': 0, 'treatment1': 2.5, 'treatment2': 5}
impression_cost_dict = {'control': 0, 'treatment1': 0, 'treatment2': 0.02}
# Use a helper function to put treatment costs to array
cc_array, ic_array, conditions = get_treatment_costs(treatment=df['treatment_group_key'],
control_name='control',
cc_dict=conversion_cost_dict,
ic_dict=impression_cost_dict)
# Put the conversion value into an array
conversion_value_array = np.full(df.shape[0], 20)
接下来,我们使用治疗下的期望值方程计算个体在其实际治疗组中的实际价值,即:
- :nbsphinx-math:`begin{equation}
mathbb{E}[(v - cc_t)Y_t - ic_t]
结束{equation}`
[5]:
# Use a helper function to obtain the value of actual treatment
actual_value = get_actual_value(treatment=df['treatment_group_key'],
observed_outcome=df['conversion'],
conversion_value=conversion_value_array,
conditions=conditions,
conversion_cost=cc_array,
impression_cost=ic_array)
[6]:
plt.hist(actual_value)
plt.show()
模型评估
在提升建模文献中,一个常见的问题是评估模型产生的治疗建议的质量。提升模型的评估很棘手,因为在非模拟数据中我们无法直接观察到个体层面的治疗效果,因此无法使用均方误差等标准模型评估指标。因此,不同的作者提出了各种方法来解决这个问题。例如,Schuler等人(2018)识别了文献中使用的七种不同的评估策略。
下面,我们使用Kaepelner等人(2014)提出的模型评估方法。该方法的思想是评估如果我们使用特定模型生成的建议来针对一些尚未处理的未来人群,我们将获得的改进。为此,我们将数据分为不相交的训练集和测试集,并在训练数据上训练我们的模型。然后,我们使用该模型预测测试数据中单位的最佳治疗组,在简单的双臂试验中,这要么是治疗组,要么是对照组。为了估计如果使用该模型,未来人群的结果,我们然后根据观察到的治疗分配是否恰好与模型推荐的相同来选择测试数据的一个子集。这个人群被称为“幸运”。
预测的最佳治疗方案 |
实际治疗方案 |
幸运 |
|---|---|---|
控制 |
控制 |
是 |
控制 |
处理 |
否 |
治疗 |
治疗 |
是 |
治疗 |
控制 |
否 |
“幸运”群体的平均结果可以被视为如果我们使用所讨论的提升模型来分配治疗,未来未治疗群体的结果会是什么。回想一下,在所有实验中,治疗被假定为在总人口中随机分配,因此应该没有选择偏差。然后可以将给定模型下的平均结果与其他治疗分配策略进行比较。正如Kaepelner等人(2014)所指出的,两种常见策略是随机分配和“最佳治疗”分配。为了估计未来群体在随机分配下的结果,我们可以简单地查看整个测试群体的样本均值。为了估计“最佳治疗”分配下的结果,我们可以查看测试集中那些观察到的治疗分配对应于具有最佳平均治疗效果的治疗组的单位。这些替代的目标策略很有趣,因为它们在工业应用和其他地方是常见的做法。
与基准的表现对比
在本节中,我们比较了四种不同的目标策略:
随机治疗分配,其中测试集中的所有单位被随机分配到治疗中
“最佳处理”分配,其中测试集中的所有单位都被分配到训练集中转化率最高的处理
在提升模型中,测试集中的所有单位都被分配到根据训练集上训练的提升模型预测具有最高转化率的处理
在反事实价值估计模型下的分配,其中所有单位都被分配到具有最佳预测回报的治疗组
[7]:
df_train, df_test = train_test_split(df)
train_idx = df_train.index
test_idx = df_test.index
[8]:
# Calculate the benchmark value according to the random allocation
# and best treatment schemes
random_allocation_value = actual_value.loc[test_idx].mean()
best_ate = df_train.groupby(
'treatment_group_key')['conversion'].mean().idxmax()
actual_is_best_ate = df_test['treatment_group_key'] == best_ate
best_ate_value = actual_value.loc[test_idx][actual_is_best_ate].mean()
[9]:
# Calculate the value under an uplift model
tm = BaseTClassifier(control_learner=xgb.XGBClassifier(),
treatment_learner=xgb.XGBClassifier(),
control_name='control')
tm.fit(df_train[X_names].values,
df_train['treatment_group_key'],
df_train['conversion'])
tm_pred = tm.predict(df_test[X_names].values)
pred_df = pd.DataFrame(tm_pred, columns=tm._classes)
tm_best = pred_df.idxmax(axis=1)
actual_is_tm_best = df_test['treatment_group_key'] == tm_best.ravel()
tm_value = actual_value.loc[test_idx][actual_is_tm_best].mean()
[10]:
# Estimate the conditional mean model; this is a pure curve
# fitting exercise
proba_model = xgb.XGBClassifier()
W_dummies = pd.get_dummies(df['treatment_group_key'])
XW = np.c_[df[X_names], W_dummies]
proba_model.fit(XW[train_idx], df_train['conversion'])
y_proba = proba_model.predict_proba(XW[test_idx])[:, 1]
[11]:
# Run the counterfactual calculation with TwoModel prediction
cve = CounterfactualValueEstimator(treatment=df_test['treatment_group_key'],
control_name='control',
treatment_names=conditions[1:],
y_proba=y_proba,
cate=tm_pred,
value=conversion_value_array[test_idx],
conversion_cost=cc_array[test_idx],
impression_cost=ic_array[test_idx])
cve_best_idx = cve.predict_best()
cve_best = [conditions[idx] for idx in cve_best_idx]
actual_is_cve_best = df.loc[test_idx, 'treatment_group_key'] == cve_best
cve_value = actual_value.loc[test_idx][actual_is_cve_best].mean()
[12]:
labels = [
'Random allocation',
'Best treatment',
'T-Learner',
'CounterfactualValueEstimator'
]
values = [
random_allocation_value,
best_ate_value,
tm_value,
cve_value
]
plt.bar(labels, values)
plt.ylabel('Mean actual value in testing set')
plt.xticks(rotation=45)
plt.show()
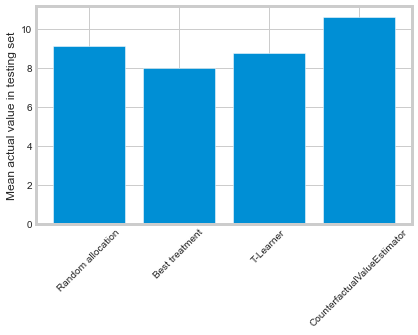
在这里,只有CounterfactualValueEstimator在随机目标上有所改进。“最佳治疗”和T-Learner方法可能表现更差,因为它们向那些无论如何都会转化的个体推荐了昂贵的治疗方法。