matplotlib.axes.Axes.hist#
- Axes.hist(x, bins=None, *, range=None, density=False, weights=None, cumulative=False, bottom=None, histtype='bar', align='mid', orientation='vertical', rwidth=None, log=False, color=None, label=None, stacked=False, data=None, **kwargs)[源代码][源代码]#
计算并绘制直方图。
此方法使用
numpy.histogram对 x 中的数据进行分箱,并统计每个箱中的数值数量,然后以BarContainer或Polygon的形式绘制分布。bins、range、density 和 weights 参数被传递给numpy.histogram。如果数据已经被分箱并计数,使用
bar或stairs来绘制分布:counts, bins = np.histogram(x) plt.stairs(counts, bins)
或者,使用
hist()绘制预计算的箱和计数,将每个箱视为一个点,其权重等于其计数:plt.hist(bins[:-1], bins, weights=counts)
数据输入 x 可以是一个单独的数组,一个可能长度不同的数据集列表([x0, x1, ...]),或者是一个2D的ndarray,其中每一列是一个数据集。注意,ndarray形式相对于列表形式是转置的。如果输入是一个数组,那么返回值是一个元组(n, bins, patches);如果输入是一个数组序列,那么返回值是一个元组([n0, n1, ...], bins, [patches0, patches1, ...])。
不支持掩码数组。
- 参数:
- x(n,) 数组或 (n,) 数组的序列
输入值,这可以接受单个数组或一系列数组,这些数组的长度不需要相同。
- bins : int 或 sequence 或 str, 默认值:
rcParams["hist.bins"](default:10)int 或 sequence 或 str, 默认: 如果 bins 是整数,它定义了范围中等宽箱的数量。
如果 bins 是一个序列,它定义了箱子的边缘,包括第一个箱子的左边缘和最后一个箱子的右边缘;在这种情况下,箱子可能是非均匀间隔的。除了最后一个(最右边的)箱子外,所有箱子都是半开的。换句话说,如果 bins 是:
[1, 2, 3, 4]
那么第一个区间是
[1, 2)``(包括1,但不包括2),第二个区间是 ``[2, 3)。然而,最后一个区间是[3, 4],它*包括*4。如果 bins 是一个字符串,它是
numpy.histogram_bin_edges支持的其中一种分箱策略:'auto', 'fd', 'doane', 'scott', 'stone', 'rice', 'sturges', 或 'sqrt'。- 范围元组或 None, 默认: None
箱子的下限和上限范围。忽略下限和上限的异常值。如果没有提供,range 是
(x.min(), x.max())。如果 bins 是一个序列,范围没有影响。如果 bins 是一个序列或指定了 range ,则自动缩放将基于指定的 bin 范围,而不是 x 的范围。
- 密度bool, 默认: False
如果
True,绘制并返回概率密度:每个 bin 将显示 bin 的原始计数除以总计数 *和 bin 宽度*(density = counts / (sum(counts) * np.diff(bins))),使得直方图下的面积积分为 1(np.sum(density * np.diff(bins)) == 1)。如果 stacked 也是
True,直方图的总和将被归一化为 1。- 权重(n,) 数组类或 None,默认:None
一个权重数组,形状与 x 相同。x 中的每个值仅将其相关权重贡献给箱计数(而不是 1)。如果 density 为
True,则权重被归一化,使得密度在范围内的积分保持为 1。- 累积布尔值或 -1,默认值:False
如果
True,则会计算一个直方图,其中每个箱子给出该箱子及其所有较小值箱子的计数。最后一个箱子给出数据点的总数。如果 density 也是
True,那么直方图将被归一化,使得最后一个箱等于1。如果 cumulative 是一个小于 0 的数字(例如,-1),累积的方向将被反转。在这种情况下,如果 density 也是
True,那么直方图将被归一化,使得第一个箱等于 1。- 底部类数组、标量或无,默认:无
每个箱子的底部位置,即从
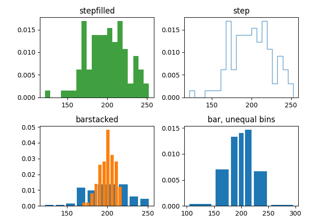
bottom到bottom + hist(x, bins)绘制箱子。如果是标量,每个箱子的底部会按相同数量移动。如果是数组,每个箱子会独立移动,且底部数组的长度必须与箱子数量匹配。如果为 None,则默认为 0。- histtype{'bar', 'barstacked', 'step', 'stepfilled'}, 默认: 'bar'
要绘制的直方图类型。
'bar' 是一个传统的条形直方图。如果给出多个数据,条形将并排排列。
'barstacked' 是一种柱状图类型,其中多个数据堆叠在彼此之上。
'step' 生成一个默认未填充的线图。
'stepfilled' 生成一个默认填充的线图。
- 对齐{'left', 'mid', 'right'}, 默认: 'mid'
直方图条的水平对齐方式。
'left': 条形图以左侧的箱边为中心。
'mid': 条形图在箱边之间居中。
'right': 柱状图以右侧边缘为中心。
- 方向{'vertical', 'horizontal'}, 默认: 'vertical'
如果为 'horizontal',则将使用
barh绘制条形直方图,并且 bottom 参数将是左边缘。- rwidthfloat 或 None, 默认: None
条形的相对宽度,作为箱宽的分数。如果
None,则自动计算宽度。如果 histtype 是 'step' 或 'stepfilled',则忽略。
- 日志bool, 默认: False
如果
True,直方图的轴将被设置为对数刻度。- 颜色 : color 或 color 列表 或 None, 默认: None颜色或颜色列表或无,默认:无
颜色或颜色序列,每个数据集对应一个颜色。默认 (
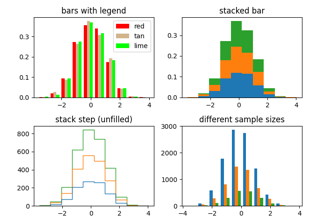
None) 使用标准线条颜色序列。- 标签str 或 str 列表,可选
字符串,或匹配多个数据集的字符串序列。条形图每个数据集产生多个补丁,但只有第一个获得标签,以便
legend能按预期工作。- 堆叠bool, 默认: False
如果
True,多个数据会堆叠在一起;如果False,多个数据会并排排列(如果 histtype 是 'bar')或堆叠在一起(如果 histtype 是 'step')。
- 返回:
- n数组或数组列表
直方图箱的值。有关可能的语义描述,请参见 density 和 weights。如果输入 x 是一个数组,那么这是一个长度为 nbins 的数组。如果输入是一个数组序列
[data1, data2, ...],那么这是一个数组列表,其中包含每个数组在相同顺序下的直方图值。数组 n (或其元素数组)的 dtype 将始终为 float,即使没有使用加权或归一化。- bins数组
箱子的边缘。长度为 nbins + 1(nbins 个左边缘和最后一个箱子的右边缘)。即使传入多个数据集,也始终是一个数组。
- patches :
BarContainer或单个Polygon的列表,或此类对象的列表BarContainer 或单个 Polygon 的列表或此类对象的列表 用于创建直方图的单个艺术家的容器,如果有多个输入数据集,则为这些容器的列表。
- 其他参数:
- 数据可索引对象,可选
如果提供,以下参数还接受一个字符串
s,如果s是data中的一个键,则解释为data[s]:x, weights
- **kwargs
Patch属性。以下属性还接受与 x 中的数据集对应的值序列:edgecolor、facecolor、linewidth、linestyle、hatch。Added in version 3.10: 允许在上述列出的补丁属性中使用值序列。
注释
对于大量的箱子(>1000),可以通过使用
stairs来绘制预先计算好的直方图(plt.stairs(*np.histogram(data))),或者通过将 histtype 设置为 'step' 或 'stepfilled' 而不是 'bar' 或 'barstacked' 来显著加速绘图。