


分类回归#
在这个例子中,我们将对具有两个以上类别的结果进行建模。
注意
本笔记本使用了不是 PyMC 依赖项的库,因此需要专门安装这些库才能运行此笔记本。打开下面的下拉菜单以获取更多指导。
Extra dependencies install instructions
为了在本地或binder上运行此笔记本,您不仅需要一个安装了所有可选依赖项的PyMC工作环境,还需要安装一些额外的依赖项。有关安装PyMC本身的建议,请参阅安装
您可以使用您喜欢的包管理器安装这些依赖项,我们提供了以下作为示例的pip和conda命令。
$ pip install pymc-bart
请注意,如果您想(或需要)从笔记本内部而不是命令行安装软件包,您可以通过运行pip命令的变体来安装软件包:
导入系统
!{sys.executable} -m pip install pymc-bart
您不应运行!pip install,因为它可能会在不同的环境中安装包,即使安装了也无法从Jupyter笔记本中使用。
另一个替代方案是使用conda:
$ conda install pymc-bart
在安装科学计算Python包时,我们推荐使用conda forge
import os
import warnings
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import pymc_bart as pmb
import seaborn as sns
warnings.simplefilter(action="ignore", category=FutureWarning)
# set formats
RANDOM_SEED = 8457
az.style.use("arviz-darkgrid")
鹰数据集#
在这里,我们将使用一个包含关于3种鹰的信息的数据集(CH=库珀鹰,RT=红尾鹰,SS=尖尾鹰)。该数据集总共包含908个个体的信息,每个个体包含16个变量,此外还有物种信息。为了简化示例,我们将使用以下5个协变量:
翼: 主翼羽从尖端到其附着的手腕的长度(单位:毫米)。
重量:体重(以克为单位)。
嘴峰: 从尖端到鸟喙上部与鸟肉部分接触处的长度(单位:毫米)。
大脚趾: 杀戮之爪的长度(单位:毫米)。
尾巴: 与尾巴长度相关的测量值(单位:毫米)。
此外,我们还将消除数据集中的NaN值。通过这些,我们将预测鹰的“物种”,换句话说,这些是我们的因变量,即我们想要预测的类别。
# Load data and eliminate NANs
try:
Hawks = pd.read_csv(os.path.join("..", "data", "Hawks.csv"))[
["Wing", "Weight", "Culmen", "Hallux", "Tail", "Species"]
].dropna()
except FileNotFoundError:
Hawks = pd.read_csv(pm.get_data("Hawks.csv"))[
["Wing", "Weight", "Culmen", "Hallux", "Tail", "Species"]
].dropna()
Hawks.head()
| Wing | Weight | Culmen | Hallux | Tail | Species | |
|---|---|---|---|---|---|---|
| 0 | 385.0 | 920.0 | 25.7 | 30.1 | 219 | RT |
| 2 | 381.0 | 990.0 | 26.7 | 31.3 | 235 | RT |
| 3 | 265.0 | 470.0 | 18.7 | 23.5 | 220 | CH |
| 4 | 205.0 | 170.0 | 12.5 | 14.3 | 157 | SS |
| 5 | 412.0 | 1090.0 | 28.5 | 32.2 | 230 | RT |
EDA#
以下比较协变量,以获取3个物种的快速数据可视化。
sns.pairplot(Hawks, hue="Species");
/home/pablo/anaconda3/envs/py310/lib/python3.10/site-packages/seaborn/axisgrid.py:123: UserWarning: The figure layout has changed to tight
self._figure.tight_layout(*args, **kwargs)
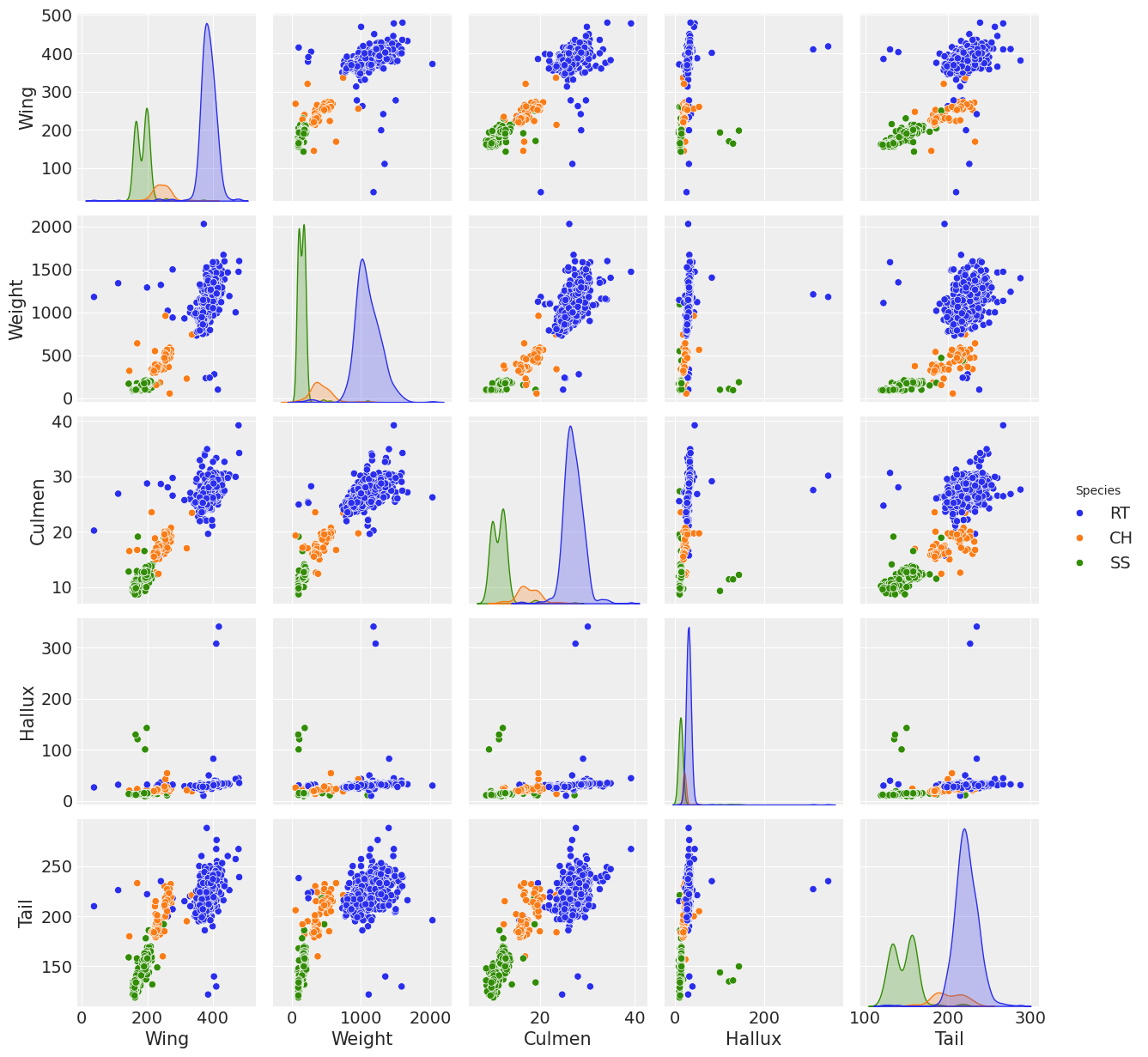
可以看出,RT物种在几乎所有协变量中的分布比其他两个物种更为分化,协变量翅膀、重量和喙在物种之间表现出一定的分离。然而,没有任何变量在物种分布之间表现出明显的分离,以至于它们可以干净地分离物种。可以通过组合协变量,可能是翅膀、重量和喙,来实现分类。这些是实现回归的主要原因。
模型规范#
首先,我们将准备模型的数据,使用“Species”作为响应变量,“Wing”、“Weight”、“Culmen”、“Hallux”和“Tail”作为预测变量。使用pd.Categorical(Hawks['Species']).codes我们可以将物种名称编码为0到2之间的整数,其中0=“CH”,1=“RT”,2=“SS”。
y_0 = pd.Categorical(Hawks["Species"]).codes
x_0 = Hawks[["Wing", "Weight", "Culmen", "Hallux", "Tail"]]
print(len(x_0), x_0.shape, y_0.shape)
891 (891, 5) (891,)
在每个pymc模型中,我们目前只能有一个BART()实例,因此为了对3个物种进行建模,我们可以使用坐标和维度名称来指定变量的形状,表明有891行信息用于3个物种。这一步便于从InferenceData中选择组。
_, species = pd.factorize(Hawks["Species"], sort=True)
species
Index(['CH', 'RT', 'SS'], dtype='object')
coords = {"n_obs": np.arange(len(x_0)), "species": species}
在这个模型中,我们使用了 pm.math.softmax() 函数,对于来自 pmb.BART() 的 \(\mu\),因为它保证了在这种情况下向量沿 axis=0 的总和为1。
with pm.Model(coords=coords) as model_hawks:
μ = pmb.BART("μ", x_0, y_0, m=50, dims=["species", "n_obs"])
θ = pm.Deterministic("θ", pm.math.softmax(μ, axis=0))
y = pm.Categorical("y", p=θ.T, observed=y_0)
pm.model_to_graphviz(model=model_hawks)

现在拟合模型并从后验中获取样本。
with model_hawks:
idata = pm.sample(chains=4, compute_convergence_checks=False, random_seed=123)
pm.sample_posterior_predictive(idata, extend_inferencedata=True)
Multiprocess sampling (4 chains in 3 jobs)
PGBART: [μ]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 155 seconds.
Sampling: [y]
结果#
变量重要性#
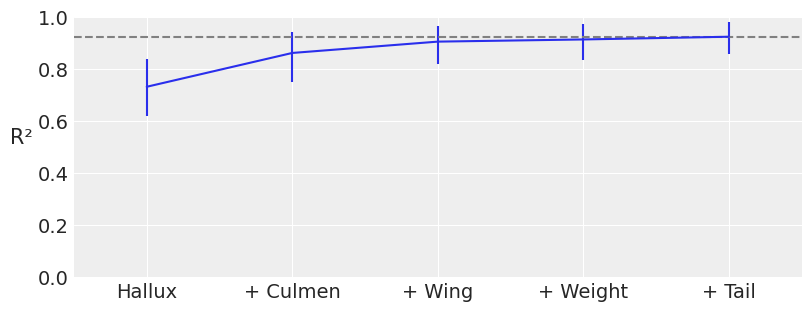
可能某些输入变量对于按物种分类并不具有信息性,因此为了简洁性和减少模型估计的计算成本,量化数据集中每个变量的重要性是有用的。PyMC-BART 提供了函数 plot_variable_importance(),该函数生成一个图,图中 x 轴显示协变量的数量,y 轴显示 R\(^2\)(皮尔逊相关系数的平方),表示完整模型(包含所有变量)和受限模型(仅包含部分变量)的预测之间的相关性。误差条表示后验预测分布的 94% HDI。
pmb.plot_variable_importance(idata, μ, x_0, method="VI", random_seed=RANDOM_SEED);
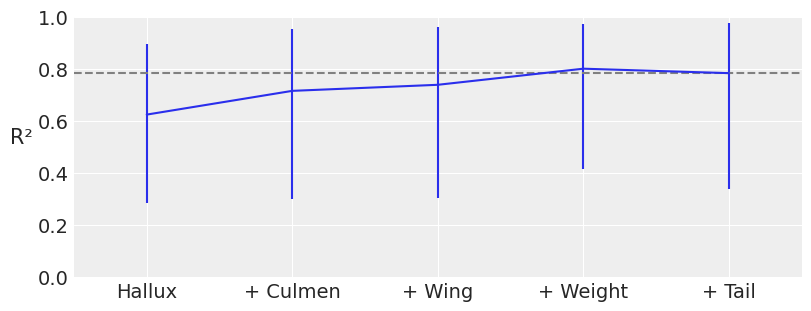
可以观察到,使用协变量 Hallux、Culmen 和 Wing,我们得到了与使用所有协变量相同的 R\(^2\) 值,这表明最后两个协变量对分类的贡献小于其他三个协变量。我们需要考虑的一点是,HDI 的范围相当宽,这使得结果的精度较低,稍后我们将看到一种减少这种情况的方法。
部分依赖图#
让我们使用pmb.plot_pdp()检查每个物种的每个协变量的行为,该函数显示协变量对预测变量的边际效应,同时我们对所有其他协变量进行平均。
pmb.plot_pdp(μ, X=x_0, Y=y_0, grid=(5, 3), figsize=(6, 9));
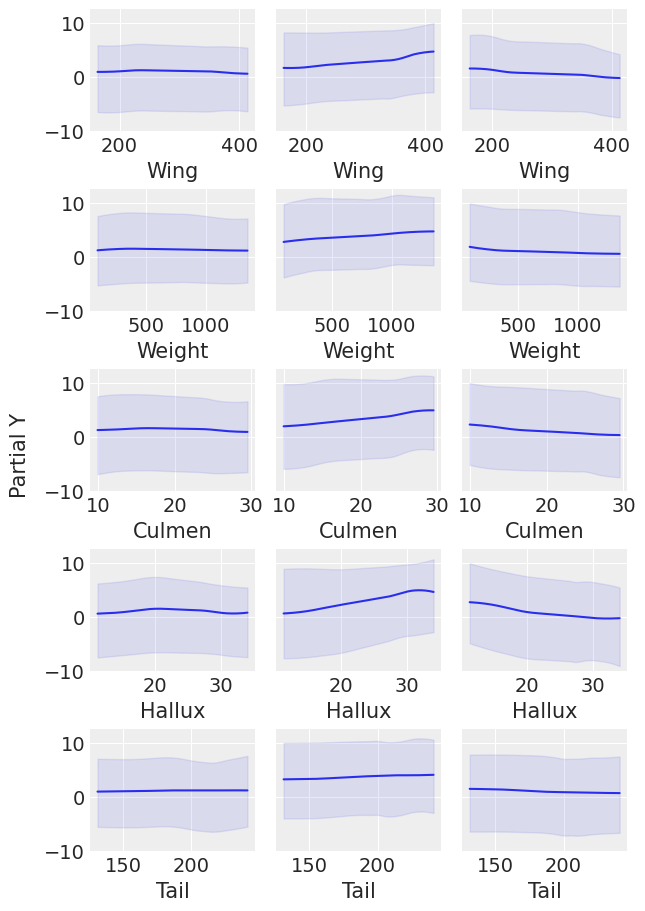
pdp图与变量重要性图一起确认了Tail是对预测变量影响较小的协变量。在变量重要性图中,Tail是最后添加的协变量,并且没有改善结果,在pdp图中,Tail的响应最平坦。对于此图中其余的协变量,很难看出它们中哪一个对预测变量的影响更大,因为它们具有很大的变异性,如HDI宽所示,与之前一样,稍后我们将看到一种减少这种变异性的方法。最后,一些变异性取决于每个物种的数据量,我们可以通过使用Pandas .describe()并按“Species”分组数据.groupby("Species")从其中一个协变量的counts中看到。
预测值 vs 观测值#
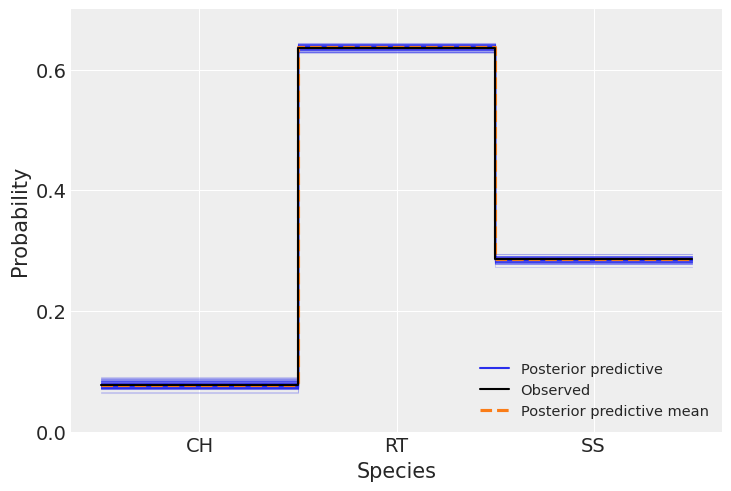
现在我们将比较预测数据与观测数据,以评估模型的拟合情况,我们使用Arviz函数az.plot_ppc()来完成这一操作。
ax = az.plot_ppc(idata, kind="kde", num_pp_samples=200, random_seed=123)
# plot aesthetics
ax.set_ylim(0, 0.7)
ax.set_yticks([0, 0.2, 0.4, 0.6])
ax.set_ylabel("Probability")
ax.set_xticks([0.5, 1.5, 2.5])
ax.set_xticklabels(["CH", "RT", "SS"])
ax.set_xlabel("Species");
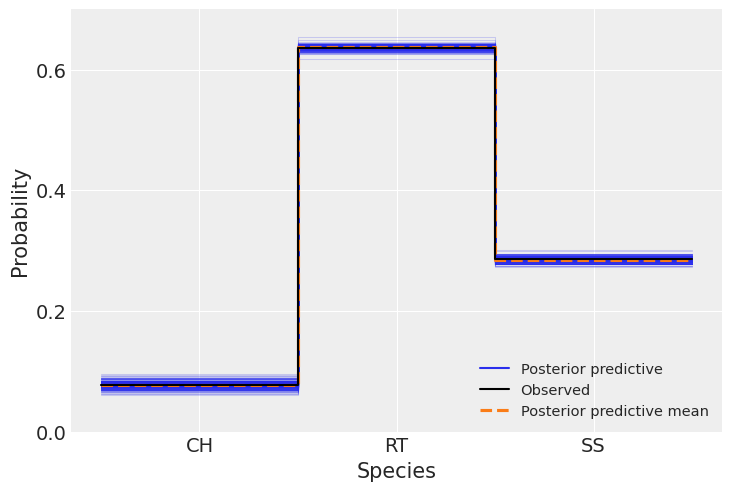
我们可以看到观测数据(黑线)与模型预测的数据(蓝线和橙线)之间有很好的吻合。正如我们之前提到的,物种之间的数值差异受到每个物种数据量的影响。在这里,与前两个图表不同,预测数据中没有观察到分散现象。
下面我们看到,样本内预测与观测结果非常吻合。
np.mean((idata.posterior_predictive["y"] - y_0) == 0) * 100
<xarray.DataArray 'y' ()> Size: 8B array(96.34186308)
all = 0
for i in range(3):
perct_per_class = np.mean(idata.posterior_predictive["y"].where(y_0 == i) == i) * 100
all += perct_per_class
print(perct_per_class)
all
<xarray.DataArray 'y' ()> Size: 8B
array(6.06369248)
<xarray.DataArray 'y' ()> Size: 8B
array(62.75785634)
<xarray.DataArray 'y' ()> Size: 8B
array(27.52031425)
<xarray.DataArray 'y' ()> Size: 8B array(96.34186308)
到目前为止,我们在基于5个协变量的物种分类方面取得了非常好的结果。然而,如果我们想要选择一个协变量子集来进行未来的分类,那么选择哪一个并不十分清楚。也许可以确定的是,Tail可以被排除。在最初我们绘制每个协变量的分布时,我们认为最重要的变量可能是Wing、Weight和Culmen,然而在运行模型后,我们发现Hallux、Culmen和Wing是最重要的。
不幸的是,部分依赖图显示了非常广泛的分散,使得结果看起来可疑。减少这种变异性的一种方法是调整独立树,下面我们将看到如何做到这一点并获得更准确的结果。
拟合独立树#
使用 pymc-bart 拟合独立树的选项通过参数 pmb.BART(..., separate_trees=True, ...) 设置。正如我们将看到的,对于这个例子,使用这个选项在预测上并没有带来很大的差异,但它帮助我们减少了ppc中的变异性,并在样本内比较中获得了小幅度的改进。如果在大数据集上使用此选项,您必须考虑到模型拟合速度会更慢,因此您可以在计算成本的代价下获得更好的结果。以下代码运行与之前相同的模型和分析,但拟合的是独立树。请比较运行此模型与之前模型所需的时间。
with pm.Model(coords=coords) as model_t:
μ_t = pmb.BART("μ", x_0, y_0, m=50, separate_trees=True, dims=["species", "n_obs"])
θ_t = pm.Deterministic("θ", pm.math.softmax(μ_t, axis=0))
y_t = pm.Categorical("y", p=θ_t.T, observed=y_0)
idata_t = pm.sample(chains=4, compute_convergence_checks=False, random_seed=123)
pm.sample_posterior_predictive(idata_t, extend_inferencedata=True)
Multiprocess sampling (4 chains in 3 jobs)
PGBART: [μ]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 423 seconds.
Sampling: [y]
现在我们将重现与之前相同的分析。
pmb.plot_variable_importance(idata_t, μ_t, x_0, method="VI", random_seed=RANDOM_SEED);
pmb.plot_pdp(μ_t, X=x_0, Y=y_0, grid=(5, 3), figsize=(6, 9));
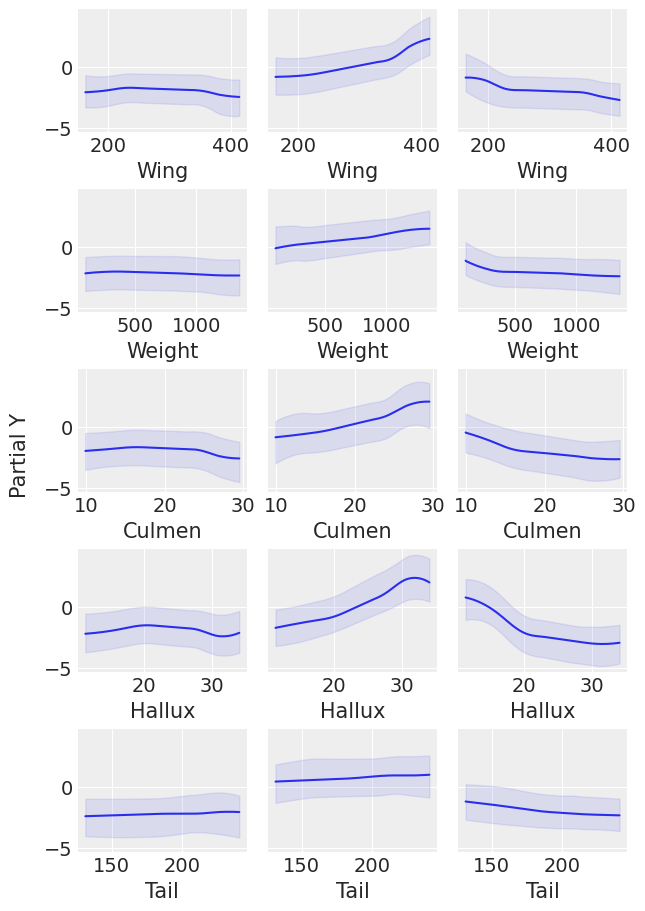
将这两个图与之前的图进行比较,可以看到每个图的方差都有明显的减少。在pmb.plot_variable_importance()的情况下,误差带更小,R\(^{2}\)值更接近1。而对于pm.plot_pdp(),我们可以看到更窄的带状图和y轴范围的缩小,这代表了由于分别调整树而减少的不确定性。另一个好处是,这使得每种物种的每个协变量的行为更加明显。
通过这些综合起来,我们可以选择 Hallux、Culmen 和 Wing 作为协变量来进行分类。
关于观测数据与预测数据的比较,我们得到了相同的好结果,且预测值的不确定性更小(蓝线)。样本内比较也是如此。
ax = az.plot_ppc(idata_t, kind="kde", num_pp_samples=100, random_seed=123)
ax.set_ylim(0, 0.7)
ax.set_yticks([0, 0.2, 0.4, 0.6])
ax.set_ylabel("Probability")
ax.set_xticks([0.5, 1.5, 2.5])
ax.set_xticklabels(["CH", "RT", "SS"])
ax.set_xlabel("Species");
np.mean((idata_t.posterior_predictive["y"] - y_0) == 0) * 100
<xarray.DataArray 'y' ()> Size: 8B array(97.26565657)
all = 0
for i in range(3):
perct_per_class = np.mean(idata_t.posterior_predictive["y"].where(y_0 == i) == i) * 100
all += perct_per_class
print(perct_per_class)
all
<xarray.DataArray 'y' ()> Size: 8B
array(6.48922559)
<xarray.DataArray 'y' ()> Size: 8B
array(62.95244108)
<xarray.DataArray 'y' ()> Size: 8B
array(27.8239899)
<xarray.DataArray 'y' ()> Size: 8B array(97.26565657)
参考资料#
水印#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor
Last updated: Wed May 29 2024
Python implementation: CPython
Python version : 3.10.0
IPython version : 8.24.0
pytensor: 2.20.0
numpy : 1.26.4
arviz : 0.18.0
pymc : 5.15.0
seaborn : 0.13.2
pymc_bart : 0.5.14
pandas : 2.2.2
matplotlib: 3.8.4
Watermark: 2.4.3