高级文章
贝叶斯非参数因果推断
- 21 一月 2024
很少有比因果关系的断言更强烈的说法,也很少有比这更值得争议的说法。一个天真的世界模型——充满了脆弱的联系和非逻辑的推论,是阴谋论和愚蠢的特征。另一方面,对因果关系的精炼和详细的理解,以清晰的预期、合理的联系和有力的反事实为特征,将引导你顺利通过这个喧嚣、纷繁复杂的世界。
贝叶斯非参数因果推断
- 21 一月 2024
很少有比因果关系的断言更强烈的说法,也很少有比这更值得争议的说法。一个天真的世界模型——充满了脆弱的联系和非逻辑的推论,是阴谋论和愚蠢的特征。另一方面,对因果关系的精炼和详细的理解,以清晰的预期、合理的联系和有力的反事实为特征,将引导你顺利通过这个喧嚣、纷繁复杂的世界。
贝叶斯非参数因果推断
- 21 一月 2024
很少有比因果关系的断言更强烈的说法,也很少有比这更值得争议的说法。一个天真的世界模型——充满了脆弱的联系和非逻辑的推论,是阴谋论和愚蠢的特征。另一方面,对因果关系的精炼和详细的理解,以清晰的预期、合理的联系和有力的反事实为特征,将引导你顺利通过这个喧嚣、纷繁复杂的世界。
贝叶斯非参数因果推断
- 21 一月 2024
很少有比因果关系的断言更强烈的说法,也很少有比这更值得争议的说法。一个天真的世界模型——充满了脆弱的联系和非逻辑的推论,是阴谋论和愚蠢的特征。另一方面,对因果关系的精炼和详细的理解,以清晰的预期、合理的联系和有力的反事实为特征,将引导你顺利通过这个喧嚣、纷繁复杂的世界。
离散选择和随机效用模型
- 21 六月 2023
指令“include”:文件未找到:‘/Users/cw/baidu/code/fin_tool/github/pymc-examples/examples/build/jupyter_execute/build/jupyter_execute/build/jupyter_execute/extra_installs.md’
离散选择和随机效用模型
- 21 六月 2023
指令“include”:未找到文件:‘/Users/cw/baidu/code/fin_tool/github/pymc-examples/examples/build/jupyter_execute/build/jupyter_execute/extra_installs.md’
离散选择和随机效用模型
- 21 六月 2023
指令“include”:未找到文件:‘/Users/cw/baidu/code/fin_tool/github/pymc-examples/examples/build/jupyter_execute/extra_installs.md’
变化的长度模型
- 21 四月 2023
对变化的研究涉及同时分析个体变化的轨迹,并从所研究的个体集合中抽象出更广泛的关于所讨论变化性质的见解。因此,很容易因为专注于树木而忽略了森林。在这个例子中,我们将展示使用分层贝叶斯模型研究个体群体内变化的一些微妙之处——从个体内部视角转向个体间/跨个体视角。
变化的长程模型
- 21 四月 2023
研究变化涉及同时分析个体变化轨迹,并从所研究的个体集合中抽象出更广泛的关于所讨论变化性质的见解。因此,很容易因为专注于树木而忽略了森林。在这个例子中,我们将展示使用分层贝叶斯模型研究个体群体内变化的一些微妙之处——从个体内部视角转向个体间/跨个体视角。
使用 ModelBuilder 类部署 PyMC 模型
- 22 二月 2023
许多用户在将他们的PyMC模型部署到生产环境中时面临困难,因为部署/保存/加载用户创建的模型没有得到很好的标准化。其中一个原因是,在PyMC中没有像scikit-learn或TensorFlow那样直接保存或加载模型的方法。新的ModelBuilder类旨在通过提供一个受scikit-learn启发的API来包装您的PyMC模型,从而改进这一工作流程。
使用 ModelBuilder 类部署 PyMC 模型
- 22 二月 2023
许多用户在将他们的PyMC模型部署到生产环境中时面临困难,因为部署/保存/加载用户创建的模型没有得到很好的标准化。其中一个原因是,与scikit-learn或TensorFlow不同,PyMC中没有直接的方法来保存或加载模型。新的ModelBuilder类旨在通过提供一个受scikit-learn启发的API来包装您的PyMC模型,从而改进这一工作流程。
使用ModelBuilder类部署PyMC模型
- 22 二月 2023
许多用户在将他们的PyMC模型部署到生产环境中时面临困难,因为部署/保存/加载用户创建的模型没有得到很好的标准化。原因之一是PyMC中没有像scikit-learn或TensorFlow那样直接保存或加载模型的方法。新的ModelBuilder类旨在通过提供一个受scikit-learn启发的API来包装您的PyMC模型,从而改进这一工作流程。
使用 ModelBuilder 类部署 PyMC 模型
- 22 二月 2023
许多用户在将他们的PyMC模型部署到生产环境中时面临困难,因为部署/保存/加载用户创建的模型没有得到很好的标准化。原因之一是PyMC中没有像scikit-learn或TensorFlow那样直接保存或加载模型的方法。新的ModelBuilder类旨在通过提供一个受scikit-learn启发的API来包装您的PyMC模型,从而改进这一工作流程。
Pathfinder 变分推断
- 05 二月 2023
Pathfinder [Zhang 等人, 2021] 是一种变分推断算法,能够从贝叶斯模型的后验分布中生成样本。它相较于广泛使用的ADVI算法具有优势。在大规模问题上,它的扩展性应优于大多数MCMC算法,包括动态HMC(即NUTS),但代价是后验估计的偏差更大。有关该算法的详细信息,请参阅arxiv预印本。
Pathfinder 变分推断
- 05 二月 2023
Pathfinder [Zhang 等人, 2021] 是一种变分推断算法,能够从贝叶斯模型的后验分布中生成样本。它相较于广泛使用的ADVI算法具有优势。在大规模问题上,它的扩展性应优于大多数MCMC算法,包括动态HMC(即NUTS),但代价是后验估计的偏差更大。有关该算法的详细信息,请参阅arxiv预印本。
经验近似概述
- 13 一月 2023
For most models we use sampling MCMC algorithms like Metropolis or NUTS. In PyMC we got used to store traces of MCMC samples and then do analysis using them. There is a similar concept for the variational inference submodule in PyMC: Empirical. This type of approximation stores particles for the SVGD sampler. There is no difference between independent SVGD particles and MCMC samples. Empirical acts as a bridge between MCMC sampling output and full-fledged VI utils like apply_replacements or sample_node. For the interface description, see 变分API快速入门. Here we will just focus on Emprical and give an overview of specific things for the Empirical approximation.
经验近似概述
- 13 一月 2023
对于大多数模型,我们使用Metropolis或NUTS等采样MCMC算法。在PyMC中,我们习惯于存储MCMC样本的轨迹,然后使用它们进行分析。PyMC中的变分推断子模块有一个类似的概念:Empirical。这种近似方法为SVGD采样器存储粒子。独立SVGD粒子与MCMC样本之间没有区别。Empirical充当MCMC采样输出与apply_replacements或sample_node等全功能VI工具之间的桥梁。有关接口描述,请参见变分推断API快速入门。这里我们将只关注Emprical,并概述Empirical近似的特定内容。
如何将JAX函数包装以便在PyMC中使用
- 24 三月 2022
指令“include”:文件未找到:‘/Users/cw/baidu/code/fin_tool/github/pymc-examples/examples/build/jupyter_execute/build/jupyter_execute/build/jupyter_execute/extra_installs.md’
如何将JAX函数包装以便在PyMC中使用
- 24 三月 2022
指令“include”:未找到文件:‘/Users/cw/baidu/code/fin_tool/github/pymc-examples/examples/build/jupyter_execute/build/jupyter_execute/extra_installs.md’
如何将JAX函数包装以便在PyMC中使用
- 24 三月 2022
指令“include”:未找到文件:‘/Users/cw/baidu/code/fin_tool/github/pymc-examples/examples/build/jupyter_execute/extra_installs.md’
因子分析
- 19 三月 2022
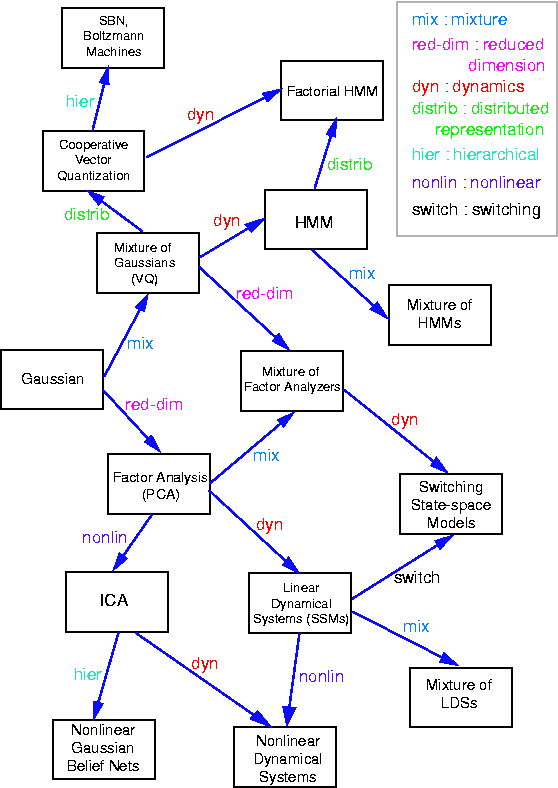
因子分析是一种广泛使用的概率模型,用于识别多元数据中的低秩结构,这些结构编码在潜在变量中。它与主成分分析非常密切相关,区别仅在于对这些潜在变量假设的先验分布。它也是一个线性高斯模型的良好示例,因为它可以完全描述为底层高斯变量的线性变换。要了解因子分析与其他模型的关系,您可以查看此图,该图最初由Ghahramani和Roweis发表。
{kind=link}
因子分析
- 19 三月 2022
因子分析是一种广泛使用的概率模型,用于识别多元数据中的低秩结构,这些结构编码在潜在变量中。它与主成分分析非常密切相关,区别仅在于对这些潜在变量假设的先验分布。它也是一个线性高斯模型的良好示例,因为它可以完全描述为底层高斯变量的线性变换。要了解因子分析与其他模型的关系,您可以查看此图,该图最初由Ghahramani和Roweis发表。
因子分析
- 19 三月 2022
因子分析是一种广泛使用的概率模型,用于识别多元数据中的低秩结构,这些结构编码在潜在变量中。它与主成分分析非常密切相关,区别仅在于对这些潜在变量假设的先验分布。它也是一个线性高斯模型的良好示例,因为它可以完全描述为底层高斯变量的线性变换。要了解因子分析与其他模型的关系,您可以查看此图,该图最初由Ghahramani和Roweis发表。
因子分析
- 19 三月 2022
因子分析是一种广泛使用的概率模型,用于识别多元数据中的低秩结构,这些结构编码在潜在变量中。它与主成分分析非常密切相关,仅在假设这些潜在变量的先验分布上有所不同。它也是一个线性高斯模型的良好示例,因为它可以完全描述为底层高斯变量的线性变换。有关因子分析与其他模型关系的概述,您可以查看此图,该图最初由Ghahramani和Roweis发表。
多项式混合的狄利克雷混合
- 08 一月 2022
这个示例笔记本演示了如何使用Dirichlet混合多项式(也称为Dirichlet-multinomial或DM)来建模分类计数数据。 这类模型在包括自然语言处理、生态学、生物信息学等多个领域中都非常重要。
多项式混合的狄利克雷分布
- 08 一月 2022
这个示例笔记本演示了如何使用Dirichlet混合多项式(也称为Dirichlet-multinomial或DM)来建模分类计数数据。 这类模型在包括自然语言处理、生态学、生物信息学等多个领域中都非常重要。
多项式混合的狄利克雷分布
- 08 一月 2022
这个示例笔记本演示了如何使用Dirichlet混合多项式(也称为Dirichlet-multinomial或DM)来建模分类计数数据。 这类模型在包括自然语言处理、生态学、生物信息学等多个领域中都非常重要。
多项式混合的狄利克雷分布
- 08 一月 2022
这个示例笔记本演示了如何使用Dirichlet混合多项式(也称为Dirichlet-multinomial或DM)来建模分类计数数据。 这类模型在包括自然语言处理、生态学、生物信息学等多个领域中都非常重要。
用于密度估计的Dirichlet过程混合模型
- 16 九月 2021
Dirichlet 过程是一个在分布空间上的灵活概率分布。最一般地,一个概率分布 \(P\) 在集合 \(\Omega\) 上是一个[测度](https://en.wikipedia.org/wiki/Measure_(mathematics%29),它将整个空间的测度赋值为1(\(P(\Omega) = 1\))。Dirichlet 过程 \(P \sim \textrm{DP}(\alpha, P_0)\) 是一个具有以下性质的测度:对于每一个有限的不相交划分 \(S_1, \ldots, S_n\) 的 \(\Omega\),
用于密度估计的Dirichlet过程混合模型
- 16 九月 2021
Dirichlet 过程是一个在分布空间上的灵活概率分布。最一般地,一个概率分布 \(P\) 在集合 \(\Omega\) 上是一个[测度](https://en.wikipedia.org/wiki/Measure_(mathematics%29),它将整个空间的测度赋值为1(\(P(\Omega) = 1\))。Dirichlet 过程 \(P \sim \textrm{DP}(\alpha, P_0)\) 是一个具有以下性质的测度:对于每一个有限的不相交划分 \(S_1, \ldots, S_n\) 的 \(\Omega\),
用于密度估计的狄利克雷过程混合模型
- 16 九月 2021
Dirichlet 过程是一个在分布空间上的灵活概率分布。最一般地,一个概率分布 \(P\) 在集合 \(\Omega\) 上是一个[测度](https://en.wikipedia.org/wiki/Measure_(mathematics%29),它将整个空间的测度赋值为1(\(P(\Omega) = 1\))。Dirichlet 过程 \(P \sim \textrm{DP}(\alpha, P_0)\) 是一个具有以下性质的测度:对于每一个有限的不相交划分 \(S_1, \ldots, S_n\) 的 \(\Omega\),
用于密度估计的Dirichlet过程混合模型
- 16 九月 2021
Dirichlet 过程是一个在分布空间上的灵活概率分布。最一般地,一个概率分布 \(P\) 在集合 \(\Omega\) 上是一个[测度](https://en.wikipedia.org/wiki/Measure_(mathematics%29),它将整个空间的测度赋值为1(\(P(\Omega) = 1\))。Dirichlet 过程 \(P \sim \textrm{DP}(\alpha, P_0)\) 是一个具有以下性质的测度:对于每一个有限的不相交划分 \(S_1, \ldots, S_n\) 的 \(\Omega\),