如何在
使用HSGPs进行婴儿出生建模
- 21 一月 2024
本笔记本提供了一个使用希尔伯特空间高斯过程(HSGP)技术的示例,该技术在[Solin 和 Särkkä,2020]中引入,用于时间序列建模的背景下。该技术已被证明在加速具有高斯过程组件的模型方面非常成功。
使用HSGPs进行婴儿出生建模
- 21 一月 2024
本笔记本提供了一个使用希尔伯特空间高斯过程(HSGP)技术的示例,该技术在[Solin 和 Särkkä, 2020]中引入,用于时间序列建模的背景下。该技术已被证明在加速具有高斯过程组件的模型方面非常成功。
使用HSGPs进行婴儿出生建模
- 21 一月 2024
本笔记本提供了一个使用希尔伯特空间高斯过程(HSGP)技术的示例,该技术在[Solin 和 Särkkä, 2020]中引入,用于时间序列建模的背景下。该技术已被证明在加速具有高斯过程组件的模型方面非常成功。
使用HSGPs进行婴儿出生建模
- 21 一月 2024
本笔记本提供了一个使用希尔伯特空间高斯过程(HSGP)技术的示例,该技术在[Solin 和 Särkkä, 2020]中引入,用于时间序列建模的背景下。该技术已被证明在加速具有高斯过程组件的模型方面非常成功。
自动边缘化离散变量
- 20 一月 2024
PyMC非常适合对具有离散潜在变量的模型进行采样。但如果你坚持只使用NUTS采样器,你需要以某种方式消除离散变量。最好的方法是边缘化它们,这样你可以受益于Rao-Blackwell定理,并获得参数的较低方差估计。
自动边缘化离散变量
- 20 一月 2024
PyMC非常适合对具有离散潜在变量的模型进行采样。但如果你坚持只使用NUTS采样器,你需要以某种方式消除离散变量。最好的方法是边缘化它们,这样你可以受益于Rao-Blackwell定理,并获得参数的较低方差估计。
自动边缘化离散变量
- 20 一月 2024
PyMC非常适合对具有离散潜在变量的模型进行采样。但如果你坚持只使用NUTS采样器,你需要以某种方式消除离散变量。最好的方法是边缘化它们,这样你可以受益于Rao-Blackwell定理,并获得参数的较低方差估计。
自动边缘化离散变量
- 20 一月 2024
PyMC非常适合对具有离散潜在变量的模型进行采样。但如果你坚持只使用NUTS采样器,你需要以某种方式消除离散变量。最好的方法是边缘化它们,这样你可以受益于Rao-Blackwell定理,并获得参数的较低方差估计。
Pathfinder 变分推断
- 05 二月 2023
Pathfinder [Zhang 等人, 2021] 是一种变分推断算法,能够从贝叶斯模型的后验分布中生成样本。它相较于广泛使用的ADVI算法具有优势。在大规模问题上,它的扩展性应优于大多数MCMC算法,包括动态HMC(即NUTS),但代价是后验估计的偏差更大。有关该算法的详细信息,请参阅arxiv预印本。
Pathfinder 变分推断
- 05 二月 2023
Pathfinder [Zhang 等人, 2021] 是一种变分推断算法,能够从贝叶斯模型的后验分布中生成样本。它相较于广泛使用的ADVI算法具有优势。在大规模问题上,它的扩展性应优于大多数MCMC算法,包括动态HMC(即NUTS),但代价是后验估计的偏差更大。有关该算法的详细信息,请参阅arxiv预印本。
DEMetropolis(Z) 采样器调优
- 18 一月 2023
对于连续变量,默认的PyMC采样器(NUTS)要求计算梯度,PyMC通过自动微分来实现这一点。然而,在某些情况下,PyMC模型可能没有提供梯度(例如,通过在PyMC外部评估数值模型),因此需要一个替代的采样器。DEMetropolisZ采样器是梯度无关推断的高效选择。PyMC中DEMetropolisZ的实现基于ter Braak和Vrugt [2008],但采用了修改后的调优方案。本笔记本比较了采样器的各种调优参数设置,包括在PyMC中引入的drop_tune_fraction参数。
DEMetropolis(Z) 采样器调优
- 18 一月 2023
对于连续变量,默认的PyMC采样器(NUTS)要求计算梯度,PyMC通过自动微分来实现这一点。然而,在某些情况下,PyMC模型可能没有提供梯度(例如,通过在PyMC外部评估数值模型),因此需要一个替代的采样器。DEMetropolisZ采样器是梯度无关推断的高效选择。PyMC中DEMetropolisZ的实现基于ter Braak和Vrugt [2008],但采用了修改后的调优方案。本笔记本比较了采样器的各种调优参数设置,包括在PyMC中引入的drop_tune_fraction参数。
DEMetropolis(Z) 采样器调优
- 18 一月 2023
对于连续变量,默认的PyMC采样器(NUTS)要求计算梯度,PyMC通过自动微分来实现这一点。然而,在某些情况下,PyMC模型可能没有提供梯度(例如,通过在PyMC外部评估数值模型),因此需要一个替代的采样器。DEMetropolisZ采样器是梯度无关推断的高效选择。PyMC中DEMetropolisZ的实现基于ter Braak和Vrugt [2008],但采用了修改后的调优方案。本笔记本比较了采样器的各种调优参数设置,包括在PyMC中引入的drop_tune_fraction参数。
DEMetropolis(Z) 采样器调优
- 18 一月 2023
对于连续变量,默认的 PyMC 采样器(NUTS)要求计算梯度,PyMC 通过自动微分来实现这一点。然而,在某些情况下,PyMC 模型可能没有提供梯度(例如,通过在 PyMC 外部评估数值模型),因此需要一个替代的采样器。DEMetropolisZ 采样器是梯度无关推断的高效选择。PyMC 中 DEMetropolisZ 的实现基于 ter Braak 和 Vrugt [2008],但采用了修改后的调优方案。本笔记本比较了采样器的各种调优参数设置,包括在 PyMC 中引入的 drop_tune_fraction 参数。
DEMetropolis 和 DEMetropolis(Z) 算法比较
- 18 一月 2023
对于连续变量,默认的 PyMC 采样器(NUTS)要求计算梯度,PyMC 通过自动微分来实现这一点。然而,在某些情况下,PyMC 模型可能没有提供梯度(例如,通过在 PyMC 外部评估数值模型),因此需要一个替代的采样器。差分进化(DE)Metropolis 采样器是梯度无关推断的高效选择。本笔记本比较了 PyMC 中的 DEMetropolis 和 DEMetropolisZ 采样器,以帮助确定哪个是给定问题的更好选择。
DEMetropolis 和 DEMetropolis(Z) 算法比较
- 18 一月 2023
对于连续变量,默认的 PyMC 采样器(NUTS)要求计算梯度,PyMC 通过自动微分来实现这一点。然而,在某些情况下,PyMC 模型可能没有提供梯度(例如,通过在 PyMC 外部评估数值模型),因此需要一个替代的采样器。差分进化(DE)Metropolis 采样器是梯度无关推断的高效选择。本笔记本比较了 PyMC 中的 DEMetropolis 和 DEMetropolisZ 采样器,以帮助确定哪个是给定问题的更好选择。
DEMetropolis 和 DEMetropolis(Z) 算法比较
- 18 一月 2023
对于连续变量,默认的 PyMC 采样器(NUTS)要求计算梯度,PyMC 通过自动微分来实现这一点。然而,在某些情况下,PyMC 模型可能没有提供梯度(例如,通过在 PyMC 外部评估数值模型),因此需要一个替代的采样器。差分进化(DE)Metropolis 采样器是梯度无关推断的高效选择。本笔记本比较了 PyMC 中的 DEMetropolis 和 DEMetropolisZ 采样器,以帮助确定哪个是给定问题的更好选择。
DEMetropolis 和 DEMetropolis(Z) 算法比较
- 18 一月 2023
对于连续变量,默认的 PyMC 采样器(NUTS)要求计算梯度,PyMC 通过自动微分来实现这一点。然而,在某些情况下,PyMC 模型可能没有提供梯度(例如,通过在 PyMC 外部评估数值模型),因此需要一个替代的采样器。差分进化(DE)Metropolis 采样器是梯度无关推断的高效选择。本笔记本比较了 PyMC 中的 DEMetropolis 和 DEMetropolisZ 采样器,以帮助确定哪个是给定问题的更好选择。
重新参数化Weibull加速失效时间模型
- 17 一月 2023
在贝叶斯参数生存分析的先前示例笔记本中,介绍了两种不同的加速失效时间(AFT)模型:Weibull 和 对数线性。在本笔记本中,我们介绍了 Weibull AFT 模型的三种不同参数化方法。
重新参数化Weibull加速失效时间模型
- 17 一月 2023
在贝叶斯参数生存分析的先前示例笔记本中,介绍了两种不同的加速失效时间(AFT)模型:Weibull 和 对数线性。在本笔记本中,我们介绍了 Weibull AFT 模型的三种不同参数化方法。
重新参数化Weibull加速失效时间模型
- 17 一月 2023
在贝叶斯参数生存分析的先前示例笔记本中,介绍了两种不同的加速失效时间(AFT)模型:Weibull 和 对数线性。在本笔记本中,我们展示了 Weibull AFT 模型的三种不同参数化方法。
重新参数化Weibull加速失效时间模型
- 17 一月 2023
在贝叶斯参数生存分析的先前示例笔记本中,介绍了两种不同的加速失效时间(AFT)模型:Weibull 和 对数线性。在本笔记本中,我们介绍了 Weibull AFT 模型的三种不同参数化方法。
使用贝叶斯推理的ODE Lotka-Volterra多方法
- 16 一月 2023
本笔记本的目的是演示如何在具有和不具有梯度的情况下对常微分方程(ODE)系统进行贝叶斯推断。比较了不同采样器的准确性和效率。
使用贝叶斯推理的ODE Lotka-Volterra多方法
- 16 一月 2023
本笔记本的目的是演示如何在常微分方程(ODE)系统上执行贝叶斯推断,无论是否使用梯度。比较了不同采样器的准确性和效率。
使用贝叶斯推断的多方法ODE Lotka-Volterra
- 16 一月 2023
本笔记本的目的是演示如何在具有和不具有梯度的情况下对常微分方程(ODE)系统进行贝叶斯推断。比较了不同采样器的准确性和效率。
使用贝叶斯推理的ODE Lotka-Volterra 多种方法
- 16 一月 2023
The purpose of this notebook is to demonstrate how to perform Bayesian inference on a system of ordinary differential equations (ODEs), both with and without gradients. The accuracy and efficiency of different samplers are compared.
PyMC中的变分推断简介
- 13 一月 2023
计算贝叶斯模型后验量的最常见策略是通过采样,特别是马尔可夫链蒙特卡洛(MCMC)算法。尽管采样算法及其相关计算在性能和效率上不断改进,但MCMC方法在数据规模上仍然扩展性差,对于超过几千个观测值的情况变得不可行。一种更具扩展性的替代方法是变分推断(VI),它将计算后验分布的问题重新表述为一个优化问题。
使用PyMC进行变分推断简介
- 13 一月 2023
计算贝叶斯模型后验量的最常见策略是通过采样,特别是马尔可夫链蒙特卡洛(MCMC)算法。尽管采样算法及其相关计算在性能和效率上不断改进,但MCMC方法在数据规模上仍然扩展性差,对于超过几千个观测值的情况变得不可行。一种更具扩展性的替代方法是变分推断(VI),它将计算后验分布的问题重新表述为一个优化问题。
经验近似概述
- 13 一月 2023
对于大多数模型,我们使用Metropolis或NUTS等采样MCMC算法。在PyMC中,我们习惯于存储MCMC样本的轨迹,然后使用它们进行分析。PyMC中的变分推断子模块有一个类似的概念:Empirical。这种近似方法为SVGD采样器存储粒子。独立SVGD粒子和MCMC样本之间没有区别。Empirical充当MCMC采样输出与apply_replacements或sample_node等全功能VI工具之间的桥梁。有关接口描述,请参见变分API快速入门。这里我们将只关注Emprical,并概述Empirical近似的特定内容。
经验近似概述
- 13 一月 2023
对于大多数模型,我们使用Metropolis或NUTS等采样MCMC算法。在PyMC中,我们习惯于存储MCMC样本的轨迹,然后使用它们进行分析。PyMC中的变分推断子模块有一个类似的概念:Empirical。这种近似方法为SVGD采样器存储粒子。独立SVGD粒子与MCMC样本之间没有区别。Empirical充当MCMC采样输出与apply_replacements或sample_node等全功能VI工具之间的桥梁。有关接口描述,请参见变分API快速入门。这里我们将只关注Emprical,并概述Empirical近似的特定内容。
删失数据模型
- 21 五月 2022
这个关于贝叶斯生存分析的示例笔记本涉及到了审查数据的问题。审查是一种缺失数据问题,其中大于某个阈值的观测值被截断到该阈值,或小于某个阈值的观测值被截断到该阈值,或两者兼有。这些分别称为右审查、左审查和区间审查。在这个示例笔记本中,我们考虑区间审查。
删失数据模型
- 21 五月 2022
这个关于贝叶斯生存分析的示例笔记本涉及到了审查数据的问题。审查是一种缺失数据问题,其中大于某个阈值的观测值被截断到该阈值,或小于某个阈值的观测值被截断到该阈值,或两者都有。这些分别称为右审查、左审查和区间审查。在这个示例笔记本中,我们考虑区间审查。
删失数据模型
- 21 五月 2022
这个关于贝叶斯生存分析的示例笔记本 涉及到了审查数据的要点。审查 是一种缺失数据问题,其中大于某个阈值的观测值被裁剪到该阈值,或小于某个阈值的观测值被裁剪到该阈值,或两者兼有。这些分别称为右审查、左审查和区间审查。在这个示例笔记本中,我们考虑区间审查。
删失数据模型
- 21 五月 2022
这个关于贝叶斯生存分析的示例笔记本涉及到了审查数据的问题。审查是一种缺失数据问题,其中大于某个阈值的观测值被截断到该阈值,或小于某个阈值的观测值被截断到该阈值,或两者兼有。这些分别称为右审查、左审查和区间审查。在这个示例笔记本中,我们考虑区间审查。
高尔夫推杆的模型构建与扩展
- 02 四月 2022
这使用了并紧密遵循Andrew Gelman的案例研究,该研究是用Stan编写的。我们增加了一些新的可视化内容,并避免使用不恰当的先验,但非常感谢他和Stan团队提供的精彩案例研究和软件。
高尔夫推杆的模型构建与扩展
- 02 四月 2022
这使用了并紧密遵循Andrew Gelman的案例研究,该研究是用Stan编写的。我们增加了一些新的可视化内容,并避免了使用不恰当的先验分布,但非常感谢他和Stan团队提供的精彩案例研究和软件。
高尔夫推杆的模型构建与扩展
- 02 四月 2022
这使用了并紧密遵循Andrew Gelman的案例研究,该研究是用Stan编写的。我们增加了一些新的可视化内容,并避免了使用不恰当的先验分布,但非常感谢他和Stan团队提供的精彩案例研究和软件。
高尔夫推杆的模型构建与扩展
- 02 四月 2022
这使用了并紧密遵循Andrew Gelman的案例研究,该研究是用Stan编写的。我们增加了一些新的可视化内容,并避免了使用不恰当的先验分布,但非常感谢他和Stan团队提供的精彩案例研究和软件。
如何将JAX函数包装以便在PyMC中使用
- 24 三月 2022
指令“include”:文件未找到:‘/Users/cw/baidu/code/fin_tool/github/pymc-examples/examples/build/jupyter_execute/build/jupyter_execute/build/jupyter_execute/extra_installs.md’
如何将JAX函数包装以便在PyMC中使用
- 24 三月 2022
指令“include”:未找到文件:‘/Users/cw/baidu/code/fin_tool/github/pymc-examples/examples/build/jupyter_execute/build/jupyter_execute/extra_installs.md’
如何将JAX函数包装以便在PyMC中使用
- 24 三月 2022
指令“include”:未找到文件:‘/Users/cw/baidu/code/fin_tool/github/pymc-examples/examples/build/jupyter_execute/extra_installs.md’
因子分析
- 19 三月 2022
因子分析是一种广泛使用的概率模型,用于识别多元数据中的低秩结构,这些结构编码在潜在变量中。它与主成分分析非常密切相关,仅在假设这些潜在变量的先验分布上有所不同。它也是一个线性高斯模型的良好示例,因为它可以完全描述为底层高斯变量的线性变换。有关因子分析与其他模型关系的概述,您可以查看此图,该图最初由Ghahramani和Roweis发表。
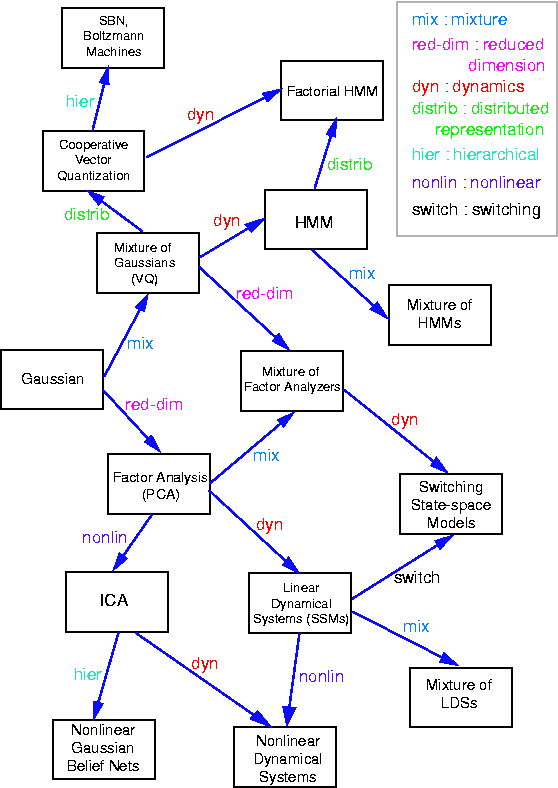{kind=link}
因子分析
- 19 三月 2022
因子分析是一种广泛使用的概率模型,用于识别多元数据中的低秩结构,这些结构编码在潜在变量中。它与主成分分析非常密切相关,仅在假设这些潜在变量的先验分布上有所不同。它也是一个线性高斯模型的良好示例,因为它可以完全描述为底层高斯变量的线性变换。有关因子分析与其他模型关系的概述,您可以查看此图,该图最初由Ghahramani和Roweis发表。
因子分析
- 19 三月 2022
因子分析是一种广泛使用的概率模型,用于识别多元数据中的低秩结构,这些结构编码在潜在变量中。它与主成分分析非常密切相关,仅在假设这些潜在变量的先验分布上有所不同。它也是一个线性高斯模型的良好示例,因为它可以完全描述为底层高斯变量的线性变换。有关因子分析与其他模型关系的概述,您可以查看此图,该图最初由Ghahramani和Roweis发表。
因子分析
- 19 三月 2022
因子分析是一种广泛使用的概率模型,用于识别多元数据中的低秩结构,这些结构编码在潜在变量中。它与主成分分析非常密切相关,仅在假设这些潜在变量的先验分布上有所不同。它也是一个线性高斯模型的良好示例,因为它可以完全描述为底层高斯变量的线性变换。有关因子分析与其他模型关系的概述,您可以查看此图,该图最初由Ghahramani和Roweis发表。
橄榄球预测的分层模型
- 19 三月 2022
在这个例子中,我们将使用PyMC重现Baio和Blangiardo [2010]中描述的第一个模型。然后展示如何从后验预测中采样,以模拟从得分的进球中预测锦标赛结果,这些进球是建模的量。
用于橄榄球预测的分层模型
- 19 三月 2022
在这个例子中,我们将使用PyMC重现Baio和Blangiardo [2010]中描述的第一个模型。然后展示如何从后验预测中采样,以模拟从得分的进球中预测锦标赛结果,这些进球是建模的量。
橄榄球预测的分层模型
- 19 三月 2022
在这个例子中,我们将使用PyMC重现Baio和Blangiardo [2010]中描述的第一个模型。然后展示如何从后验预测中采样,以模拟从得分的进球中预测锦标赛结果,这些进球是建模的量。
橄榄球预测的分层模型
- 19 三月 2022
在这个例子中,我们将使用PyMC重现Baio和Blangiardo [2010]中描述的第一个模型。然后展示如何从后验预测中采样,以模拟从得分的进球中预测锦标赛结果,这些进球是建模的量。