


使用BART建模异方差性#
在本笔记本中,我们展示了如何使用BART来建模异方差性,如pymc-bart论文的第4.1节所述[Quiroga 等, 2022]。我们使用了R包datarium提供的marketing数据集[Kassambara, 2019]。其想法是将营销渠道对销售的贡献建模为预算的函数。
import os
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import pymc_bart as pmb
%config InlineBackend.figure_format = "retina"
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [10, 6]
rng = np.random.default_rng(42)
读取数据#
try:
df = pd.read_csv(os.path.join("..", "data", "marketing.csv"), sep=";", decimal=",")
except FileNotFoundError:
df = pd.read_csv(pm.get_data("marketing.csv"), sep=";", decimal=",")
n_obs = df.shape[0]
df.head()
| youtube | newspaper | sales | ||
|---|---|---|---|---|
| 0 | 276.12 | 45.36 | 83.04 | 26.52 |
| 1 | 53.40 | 47.16 | 54.12 | 12.48 |
| 2 | 20.64 | 55.08 | 83.16 | 11.16 |
| 3 | 181.80 | 49.56 | 70.20 | 22.20 |
| 4 | 216.96 | 12.96 | 70.08 | 15.48 |
EDA#
我们首先查看数据。我们将重点关注Youtube。
fig, ax = plt.subplots()
ax.plot(df["youtube"], df["sales"], "o", c="C0")
ax.set(title="Sales as a function of Youtube budget", xlabel="budget", ylabel="sales");
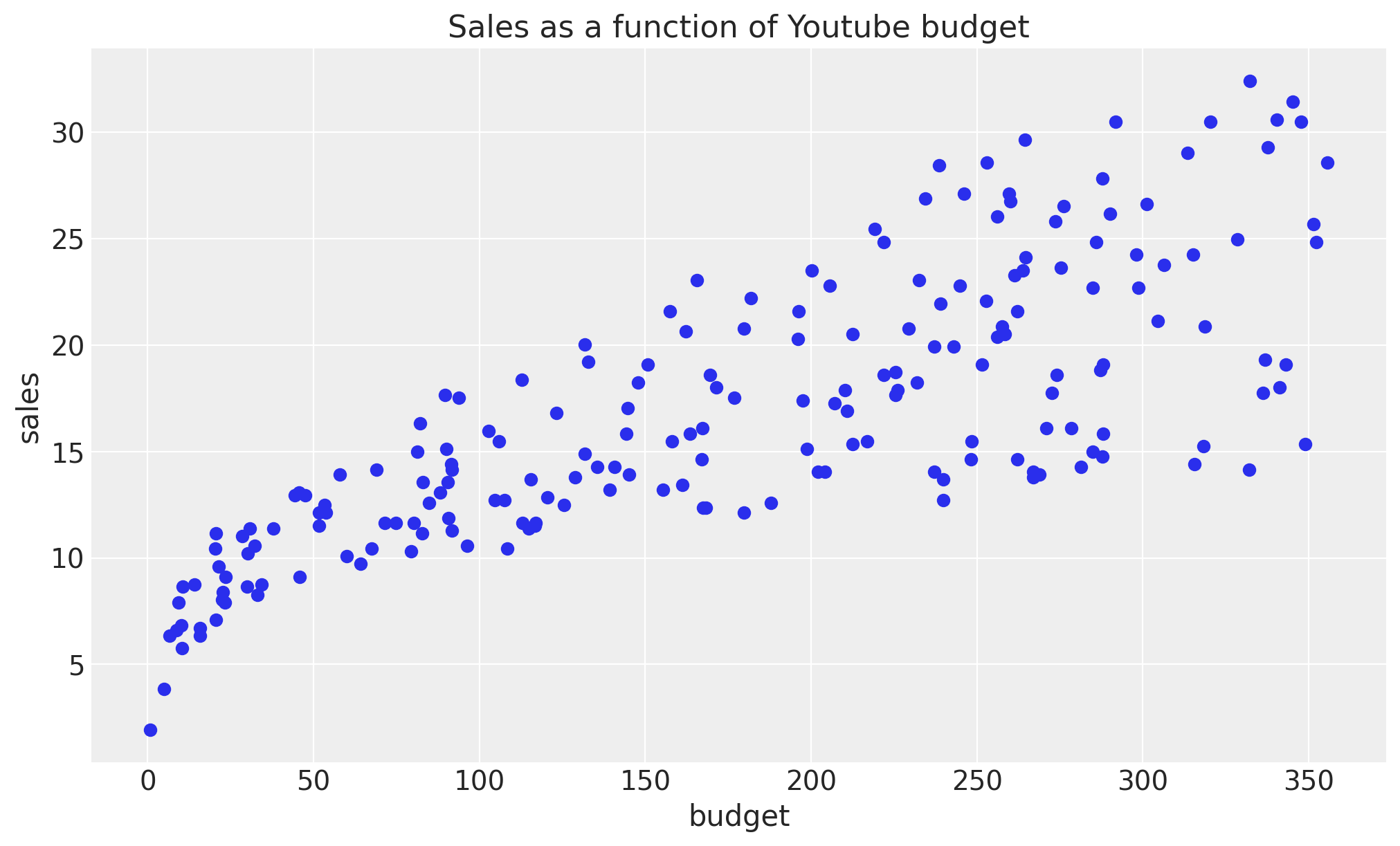
我们清楚地看到,均值和方差都随着预算的增加而增加。一种可能性是手动选择这些函数的显式参数化,例如平方根或对数。然而,在这个例子中,我们希望使用BART模型从数据中学习这些函数。
模型规范#
我们继续准备数据以进行建模。我们将使用预算作为预测变量,销售额作为响应变量。
X = df["youtube"].to_numpy().reshape(-1, 1)
Y = df["sales"].to_numpy()
接下来,我们指定模型。请注意,我们只需要一个BART分布,它可以向量化以同时建模均值和方差。我们使用Gamma分布作为似然函数,因为我们期望销售额为正值。
with pm.Model() as model_marketing_full:
w = pmb.BART("w", X=X, Y=np.log(Y), m=100, shape=(2, n_obs))
y = pm.Gamma("y", mu=pm.math.exp(w[0]), sigma=pm.math.exp(w[1]), observed=Y)
pm.model_to_graphviz(model=model_marketing_full)

我们现在拟合模型。
with model_marketing_full:
idata_marketing_full = pm.sample(2000, random_seed=rng, compute_convergence_checks=False)
posterior_predictive_marketing_full = pm.sample_posterior_predictive(
trace=idata_marketing_full, random_seed=rng
)
Multiprocess sampling (4 chains in 4 jobs)
PGBART: [w]
Sampling 4 chains for 1_000 tune and 2_000 draw iterations (4_000 + 8_000 draws total) took 145 seconds.
Sampling: [y]
结果#
我们现在可以可视化均值的后验预测分布和似然。
posterior_mean = idata_marketing_full.posterior["w"].mean(dim=("chain", "draw"))[0]
w_hdi = az.hdi(ary=idata_marketing_full, group="posterior", var_names=["w"], hdi_prob=0.5)
pps = az.extract(
posterior_predictive_marketing_full, group="posterior_predictive", var_names=["y"]
).T
idx = np.argsort(X[:, 0])
fig, ax = plt.subplots()
az.plot_hdi(
x=X[:, 0],
y=pps,
ax=ax,
hdi_prob=0.90,
fill_kwargs={"alpha": 0.3, "label": r"Observations $90\%$ HDI"},
)
az.plot_hdi(
x=X[:, 0],
hdi_data=np.exp(w_hdi["w"].sel(w_dim_0=0)),
ax=ax,
fill_kwargs={"alpha": 0.6, "label": r"Mean $50\%$ HDI"},
)
ax.plot(df["youtube"], df["sales"], "o", c="C0", label="Raw Data")
ax.legend(loc="upper left")
ax.set(
title="Sales as a function of Youtube budget - Posterior Predictive",
xlabel="budget",
ylabel="sales",
);
/home/osvaldo/anaconda3/envs/pymc/lib/python3.11/site-packages/arviz/plots/hdiplot.py:160: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
hdi_data = hdi(y, hdi_prob=hdi_prob, circular=circular, multimodal=False, **hdi_kwargs)
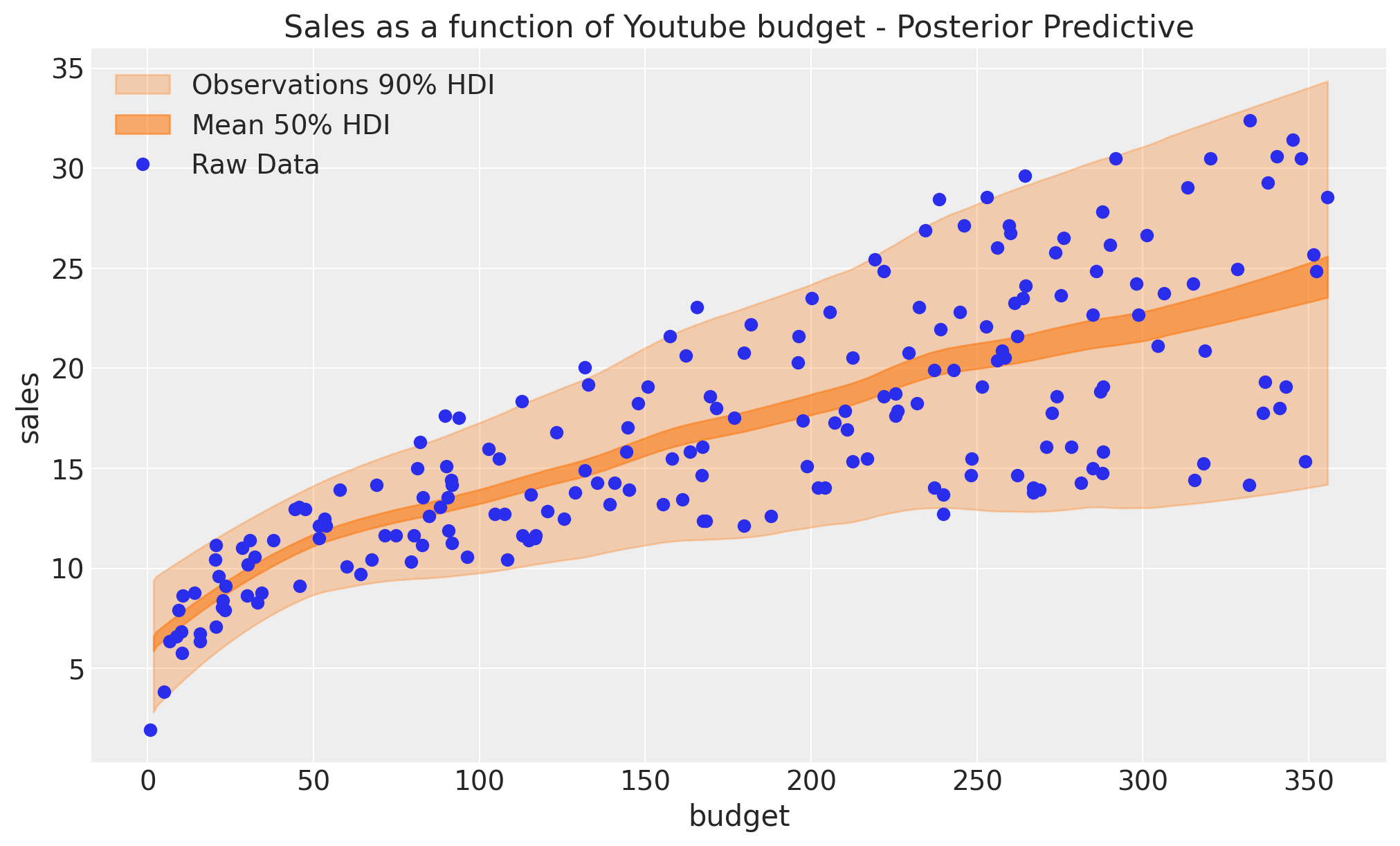
拟合看起来不错!事实上,我们看到均值和方差随着预算的增加而增加。
参考资料#
Miriana Quiroga, Pablo G Garay, Juan M. Alonso, Juan Martin Loyola, 和 Osvaldo A Martin. 贝叶斯加性回归树用于概率编程。2022年。URL: https://arxiv.org/abs/2206.03619, doi:10.48550/ARXIV.2206.03619.
Alboukadel Kassambara. datarium: 用于统计分析和可视化的数据银行. 2019. R 包版本 0.1.0. URL: https://CRAN.R-project.org/package=datarium.
水印#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor
Last updated: Sat Nov 18 2023
Python implementation: CPython
Python version : 3.11.5
IPython version : 8.16.1
pytensor: 2.17.3
arviz : 0.16.1
pandas : 2.1.2
numpy : 1.24.4
matplotlib: 3.8.0
pymc_bart : 0.5.3
pymc : 5.9.2+10.g547bcb481
Watermark: 2.4.3
许可证声明#
本示例库中的所有笔记本均在MIT许可证下提供,该许可证允许修改和重新分发,前提是保留版权和许可证声明。
引用 PyMC 示例#
要引用此笔记本,请使用Zenodo为pymc-examples仓库提供的DOI。
重要
许多笔记本是从其他来源改编的:博客、书籍……在这种情况下,您应该引用原始来源。
同时记得引用代码中使用的相关库。
这是一个BibTeX的引用模板:
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
渲染后可能看起来像: