


断点回归设计分析#
准实验涉及实验干预和定量测量。然而,准实验不涉及将单位(例如细胞、人、公司、学校、州)随机分配到测试组或对照组。这种无法进行随机分配的情况在提出因果关系声明时会带来问题,因为它使得更难论证对照组和测试组之间的任何差异是由于干预而不是由于混杂因素造成的。
回归不连续设计是一种特定的准实验设计形式。它包括一个对照组和一个测试组,但将单位分配到条件是基于一个阈值标准,而不是随机分配的。

回归不连续设计示意图。虚线绿色表示如果我们没有接受治疗,测试组的测试后分数应该在哪里。图片来自https://conjointly.com/kb/regression-discontinuity-design/。#
得分非常低的单位可能在某些维度上与得分非常高的单位系统性地不同。例如,如果我们观察取得最高分的学生和取得最低分的学生,很可能存在混杂变量。得分高的学生可能来自比得分最低的学生更优越的背景。
如果我们给得分最低一半的学生提供额外的辅导(我们的实验干预),那么我们可以很容易想象,在测试组和对照组之间,某些特权度量上存在很大的差异。乍一看,这似乎会使断点回归设计变得无用——随机分配的全部意义在于减少或消除对照组和测试组之间的系统性偏差。但使用阈值似乎会最大化组间混杂变量的差异。这不是一件奇怪的事情吗?
然而,关键点在于,得分略低于和略高于门槛的学生在特权程度上系统性差异的可能性要小得多。因此,如果我们在那些略高于和略低于门槛的学生中发现了一个有意义的断点,那么干预(根据门槛标准应用)是因果关系的解释就更加合理了。
生成模拟数据#
请注意,这里我们假设测量噪声可以忽略不计/为零,但前后测试的真实值存在一些变异性。可以考虑前后测试结果的测量噪声,但我们在本笔记本中不涉及这一点。
Show code cell source
# define true parameters
threshold = 0.0
treatment_effect = 0.7
N = 1000
sd = 0.3 # represents change between pre and post test with zero measurement error
# No measurement error, but random change from pre to post
df = (
pd.DataFrame.from_dict({"x": rng.normal(size=N)})
.assign(treated=lambda x: x.x < threshold)
.assign(y=lambda x: x.x + rng.normal(loc=0, scale=sd, size=N) + treatment_effect * x.treated)
)
df
| x | treated | y | |
|---|---|---|---|
| 0 | -0.989121 | True | 0.050794 |
| 1 | -0.367787 | True | -0.181418 |
| 2 | 1.287925 | False | 1.345912 |
| 3 | 0.193974 | False | 0.430915 |
| 4 | 0.920231 | False | 1.229825 |
| ... | ... | ... | ... |
| 995 | -1.246726 | True | -0.819665 |
| 996 | 0.090428 | False | 0.006909 |
| 997 | 0.370658 | False | -0.027703 |
| 998 | -1.063268 | True | 0.008132 |
| 999 | 0.239116 | False | 0.604780 |
1000行 × 3列
Show code cell source
def plot_data(df):
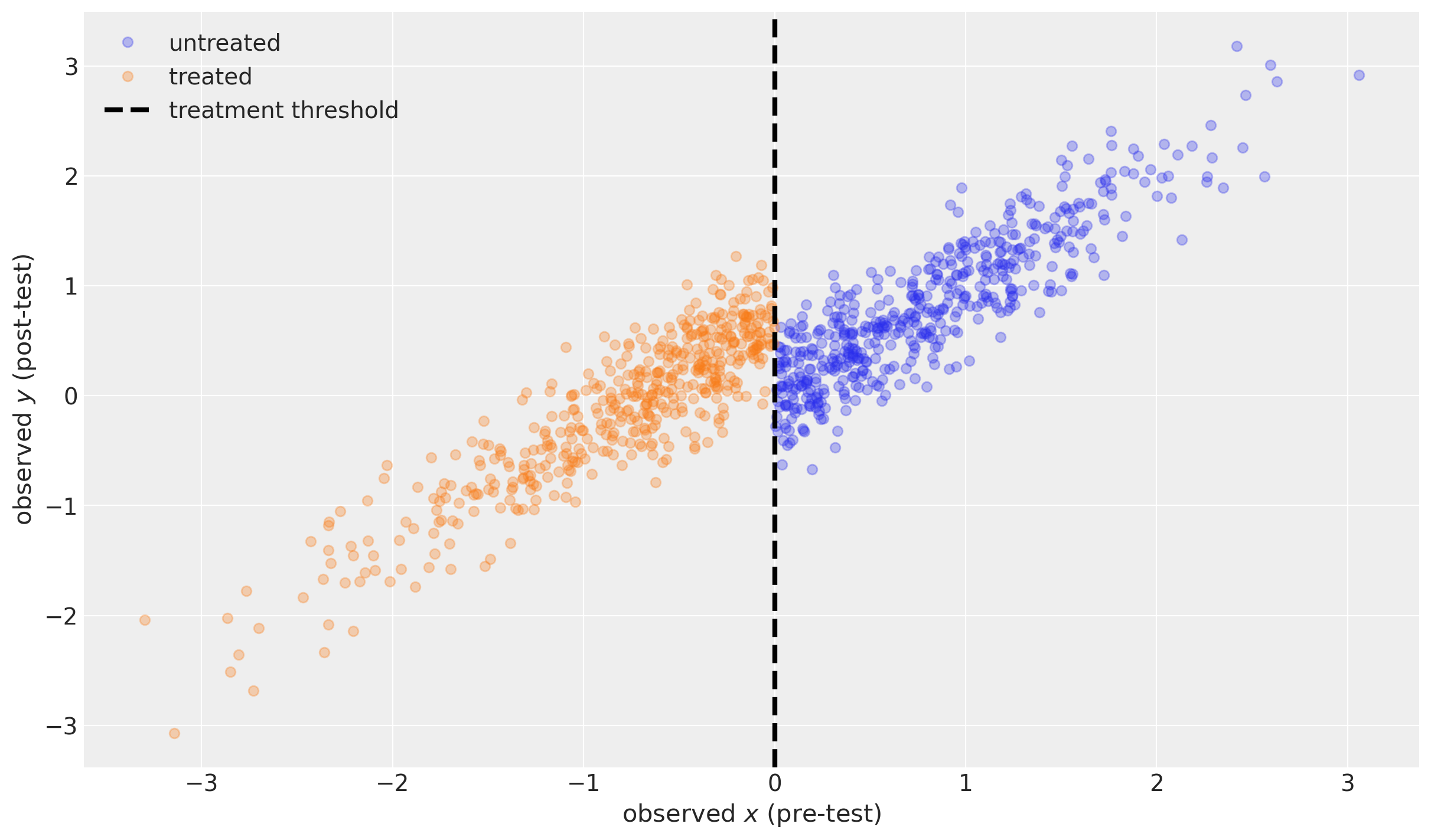
fig, ax = plt.subplots(figsize=(12, 7))
ax.plot(df.x[~df.treated], df.y[~df.treated], "o", alpha=0.3, label="untreated")
ax.plot(df.x[df.treated], df.y[df.treated], "o", alpha=0.3, label="treated")
ax.axvline(x=threshold, color="k", ls="--", lw=3, label="treatment threshold")
ax.set(xlabel=r"observed $x$ (pre-test)", ylabel=r"observed $y$ (post-test)")
ax.legend()
return ax
plot_data(df);
尖锐回归不连续模型#
我们可以将我们的贝叶斯回归不连续模型定义为:
其中:
\(\Delta\) 是不连续性的大小,
\(\sigma\) 是前后测分数变化的标准差,
\(x_i\) 和 \(y_i\) 是单位 \(i\) 的前测和后测观察值,并且
\(treated_i\) 是一个观察到的指示变量(0 表示对照组,1 表示测试组)。
注释:
我们假设没有测量误差。
在这里,我们仅限于使用相同的测量指标(例如心率、教育程度、上臂围)进行前测(\(x\))和后测(\(y\))的情况。因此,未处理的后测指标可以建模为 \(y \sim \text{Normal}(\mu=x, \sigma)\)。
在预测试和后测试的测量仪器不相同的情况下,我们希望将斜率和截距参数构建到\(\mu\)中,以捕捉预测试和后测试测量之间的“汇率”。
我们假设我们已经准确地观察到某个单位是否接受了处理。也就是说,该模型假设了一个没有不确定性的明显断点。
with pm.Model() as model:
x = pm.MutableData("x", df.x, dims="obs_id")
treated = pm.MutableData("treated", df.treated, dims="obs_id")
sigma = pm.HalfNormal("sigma", 1)
delta = pm.Cauchy("effect", alpha=0, beta=1)
mu = pm.Deterministic("mu", x + (delta * treated), dims="obs_id")
pm.Normal("y", mu=mu, sigma=sigma, observed=df.y, dims="obs_id")
pm.model_to_graphviz(model)

推理#
with model:
idata = pm.sample(random_seed=RANDOM_SEED)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [sigma, effect]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
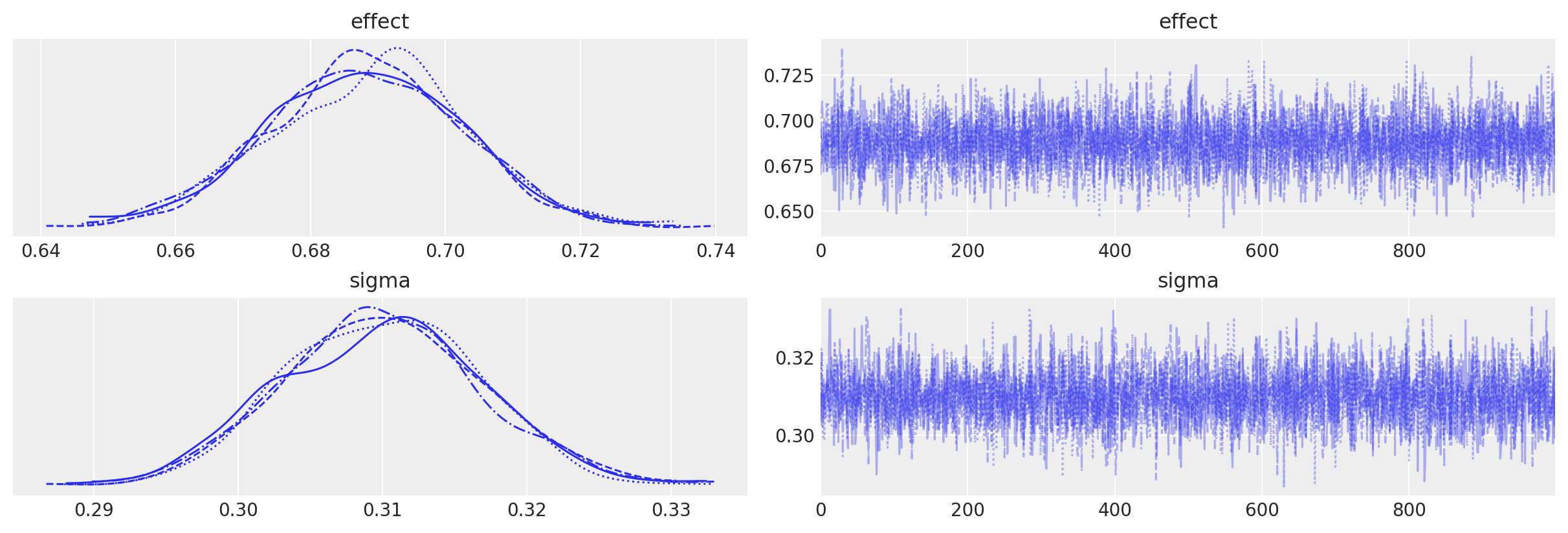
我们可以看到没有采样警告,并且绘制MCMC轨迹图显示没有问题。
az.plot_trace(idata, var_names=["effect", "sigma"]);
我们还可以看到,我们能够准确地恢复真实的不连续性幅度(左)和前后测试之间单位变化的标准差(右)。
az.plot_posterior(
idata, var_names=["effect", "sigma"], ref_val=[treatment_effect, sd], hdi_prob=0.95
);
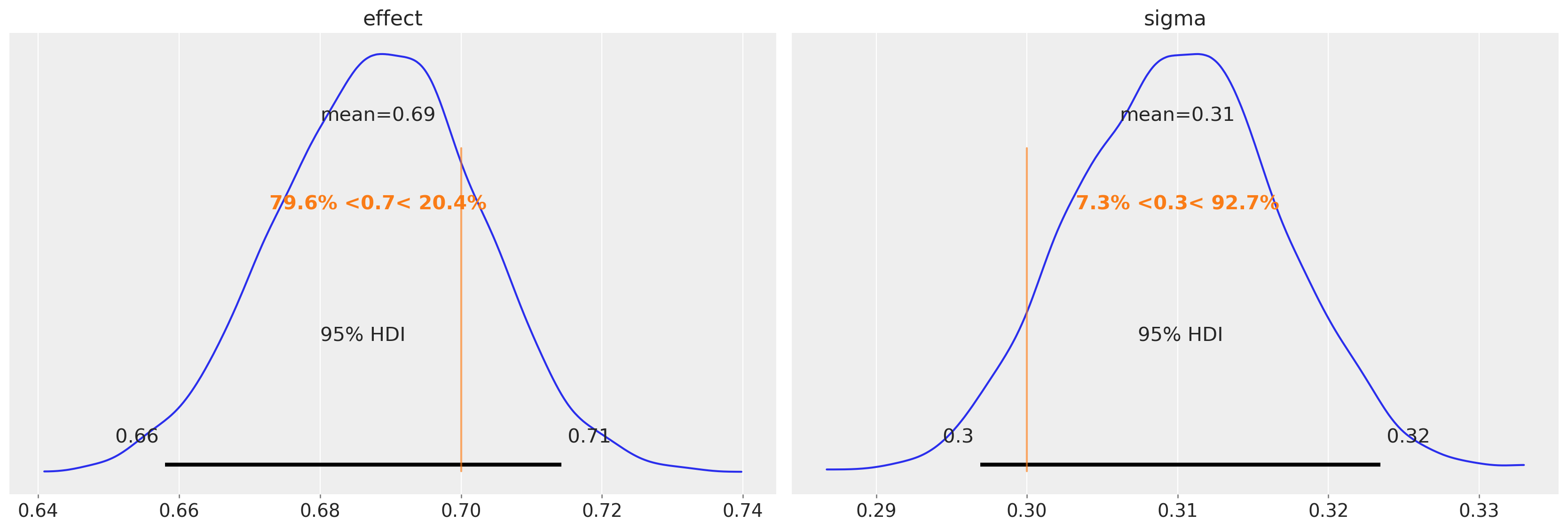
最重要的事情是关于effect参数的后验分布。我们可以利用它来判断效果的强度(例如通过95%的可信区间)或效果的存在/缺失(例如通过贝叶斯因子或ROPE)。
反事实问题#
我们可以使用后验预测来询问,如果我们:
没有单位暴露于治疗(蓝色阴影区域,非常狭窄)
所有单位都暴露在处理(橙色阴影区域)中。
技术说明:正式来说,我们正在进行y的后验预测。多次使用不同的随机种子运行pm.sample_posterior_predictive将每次产生新的和不同的y样本。然而,对于mu来说,情况并非如此(我们不是正式地进行后验预测)。这是因为mu是一个确定性函数(mu = x + delta*treated),因此对于我们已经获得的后验样本delta,mu的值将完全由x和treated数据的值决定)。
# MODEL EXPECTATION WITHOUT TREATMENT ------------------------------------
# probe data
_x = np.linspace(np.min(df.x), np.max(df.x), 500)
_treated = np.zeros(_x.shape)
# posterior prediction (see technical note above)
with model:
pm.set_data({"x": _x, "treated": _treated})
ppc = pm.sample_posterior_predictive(idata, var_names=["mu", "y"])
# plotting
ax = plot_data(df)
az.plot_hdi(
_x,
ppc.posterior_predictive["mu"],
color="C0",
hdi_prob=0.95,
ax=ax,
fill_kwargs={"label": r"$\mu$ untreated"},
)
# MODEL EXPECTATION WITH TREATMENT ---------------------------------------
# probe data
_x = np.linspace(np.min(df.x), np.max(df.x), 500)
_treated = np.ones(_x.shape)
# posterior prediction (see technical note above)
with model:
pm.set_data({"x": _x, "treated": _treated})
ppc = pm.sample_posterior_predictive(idata, var_names=["mu", "y"])
# plotting
az.plot_hdi(
_x,
ppc.posterior_predictive["mu"],
color="C1",
hdi_prob=0.95,
ax=ax,
fill_kwargs={"label": r"$\mu$ treated"},
)
ax.legend()
Sampling: [y]
Sampling: [y]
<matplotlib.legend.Legend at 0x12ff8bfd0>
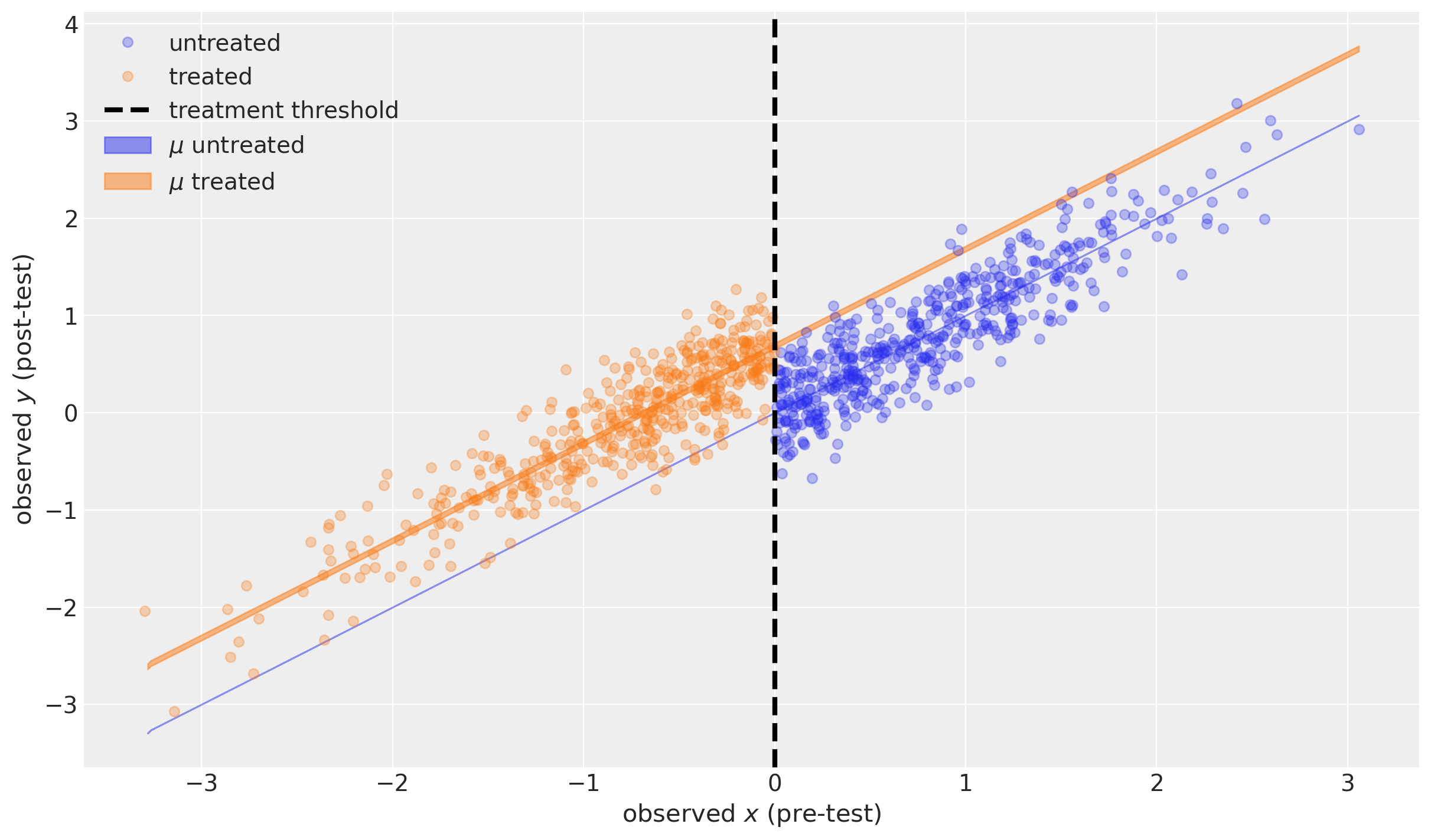
蓝色阴影区域显示了在无治疗情况下,一系列可能的前测值对应的95%可信区间内的后测测量期望值。实际上,这个区间是无限窄的,因为该特定模型假设 \(\mu=x\)(见上文)。
橙色阴影区域显示了在治疗情况下,一系列可能的前测值对应的95%可信区间后测测量期望值。
两者实际上都是非常有趣的反事实推理示例。我们没有观察到任何低于阈值未处理的单元,也没有观察到任何高于阈值已处理的单元。但假设我们的模型是对现实的良好描述,我们可以提出反事实的问题“如果一个高于阈值的单元被处理了会怎样?”和“如果一个低于阈值的单元被处理了会怎样?”
概述#
在本笔记本中,我们仅仅触及了如何分析来自回归不连续设计的数据的表面。可以说,我们将重点限制在几乎最简单的可能情况下,以便我们可以专注于该方法的核心属性,从而允许进行因果推断。
水印#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor,aeppl,xarray
Last updated: Wed Feb 01 2023
Python implementation: CPython
Python version : 3.11.0
IPython version : 8.9.0
pytensor: 2.8.11
aeppl : not installed
xarray : 2023.1.0
arviz : 0.14.0
pandas : 1.5.3
pymc : 5.0.1
matplotlib: 3.6.3
numpy : 1.24.1
Watermark: 2.3.1