


空间数据的条件自回归(CAR)模型#
import os
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import pytensor.tensor as pt
注意
本笔记本使用了不是 PyMC 依赖项的库,因此需要专门安装这些库才能运行此笔记本。打开下面的下拉菜单以获取更多指导。
Extra dependencies install instructions
为了在本地或binder上运行此笔记本,您不仅需要一个安装了所有可选依赖项的PyMC工作环境,还需要安装一些额外的依赖项。有关安装PyMC本身的建议,请参阅安装
您可以使用您喜欢的包管理器安装这些依赖项,我们提供了以下作为示例的pip和conda命令。
$ pip install geopandas libpysal
请注意,如果您想(或需要)从笔记本内部而不是命令行安装软件包,您可以通过运行pip命令的变体来安装软件包:
导入系统
!{sys.executable} -m pip install geopandas libpysal
您不应运行!pip install,因为它可能会在不同的环境中安装包,即使安装了也无法从Jupyter笔记本中使用。
另一个替代方案是使用conda:
$ conda install geopandas libpysal
在安装科学计算Python包时,我们推荐使用conda forge
# THESE ARE THE LIBRARIES THAT ARE NOT DEPENDENCIES ON PYMC
import libpysal
from geopandas import read_file
RANDOM_SEED = 8927
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
条件自回归(CAR)模型#
一组随机效应 \(\{\phi_i\}_{i=1}^N\) 上的 条件自回归 CAR 先验 将随机效应 \(\phi_i\) 建模为具有均值,即观测值 \(i\) 的相邻邻居的随机效应的加权平均值。数学上,这可以表示为
其中 \({j \sim i}\) 表示观测值 \(i\) 的相邻邻居集合,\(n_i\) 表示观测值 \(i\) 拥有的相邻邻居数量,\(w_{ij}\) 是观测值 \(i\) 和 \(j\) 之间的空间关系权重。如果 \(i\) 和 \(j\) 不相邻,则 \(w_{ij}=0\)。最后,\(\sigma_i^2\) 是每个区域的局部变化方差参数。需要注意的是,输入数据需要包括邻接矩阵(表示邻居关系)和权重矩阵 \(\textbf{w}\)(表示空间关系的权重)。我们推断的参数是 \(\{\phi\}_{i=1}^N, \{\sigma_i\}_{i=1}^N\) 和 \(\alpha\)。
模型规范#
在这里,我们将通过一个典型的例子来演示CAR模型的实现:1975年至1980年间苏格兰的唇癌风险数据。原始数据来自[1]。该数据集包括在苏格兰的\(N=56\)个空间单位中观察到的唇癌病例数\(\{y_i\}_{i=1}^N\),以及作为偏移项的预期病例数\(\{E_i\}_{i=1}^N\),一个截距参数,以及一个表示农业、渔业或林业就业比例的区域特定连续变量的参数,记为\(\{x_i\}_{i=1}^N\)。我们希望建立模型来研究唇癌发病率与行业就业分布之间的关系,因为暴露在阳光下是一个风险因素。数学上,模型为
其中 \(a\) 是用于先验分布方差的回归系数的一些选定超参数。
准备数据#
我们需要加载数据集以访问变量 \(\{y_i, x_i, E_i\}_{i=1}^N\)。但更独特的是使用CAR模型时,需要创建必要的地理邻接矩阵。对于我们拟合的模型,所有邻居的权重均为 \(1\),从而避免了权重矩阵的需求。
try:
df_scot_cancer = pd.read_csv(os.path.join("..", "data", "scotland_lips_cancer.csv"))
except FileNotFoundError:
df_scot_cancer = pd.read_csv(pm.get_data("scotland_lips_cancer.csv"))
df_scot_cancer.head()
| CODENO | NAME | CANCER | CEXP | AFF | ADJ | WEIGHTS | |
|---|---|---|---|---|---|---|---|
| 0 | 6126 | Skye-Lochalsh | 9 | 1.38 | 16 | [5, 9, 11, 19] | [1, 1, 1, 1] |
| 1 | 6016 | Banff-Buchan | 39 | 8.66 | 16 | [7, 10] | [1, 1] |
| 2 | 6121 | Caithness | 11 | 3.04 | 10 | [6, 12] | [1, 1] |
| 3 | 5601 | Berwickshire | 9 | 2.53 | 24 | [18, 20, 28] | [1, 1, 1] |
| 4 | 6125 | Ross-Cromarty | 15 | 4.26 | 10 | [1, 11, 12, 13, 19] | [1, 1, 1, 1, 1] |
# observed cancer counts
y = df_scot_cancer["CANCER"].values
# number of observations
N = len(y)
# expected cancer counts E for each county: this is calculated using age-standardized rates of the local population
E = df_scot_cancer["CEXP"].values
logE = np.log(E)
# proportion of the population engaged in agriculture, forestry, or fishing
x = df_scot_cancer["AFF"].values / 10.0
以下是我们创建必要邻接矩阵的步骤,其中矩阵的条目 \(i,j\) 为 \(1\) 如果观测值 \(i\) 和 \(j\) 被认为是邻居,否则为 \(0\)。
# spatial adjacency information: column `ADJ` contains list entries which are preprocessed to obtain adj as a list of lists
adj = (
df_scot_cancer["ADJ"].apply(lambda x: [int(val) for val in x.strip("][").split(",")]).to_list()
)
# change to Python indexing (i.e. -1)
for i in range(len(adj)):
for j in range(len(adj[i])):
adj[i][j] = adj[i][j] - 1
# storing the adjacency matrix as a two-dimensional np.array
adj_matrix = np.zeros((N, N), dtype="int32")
for area in range(N):
adj_matrix[area, adj[area]] = 1
可视化数据#
建模空间数据的一个重要方面是能够有效地可视化数据的时空特性,以及您选择的模型是否捕捉到了这种空间依赖性。
我们加载了苏格兰唇癌数据集的另一个版本,来自libpysal包,用于绘图。
_ = libpysal.examples.load_example("Scotlip")
pth = libpysal.examples.get_path("scotlip.shp")
spat_df = read_file(pth)
spat_df["PROP"] = spat_df["CANCER"] / np.exp(spat_df["CEXP"])
spat_df.head()
| CODENO | AREA | PERIMETER | RECORD_ID | DISTRICT | NAME | CODE | CANCER | POP | CEXP | AFF | geometry | PROP | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6126 | 9.740020e+08 | 184951.0 | 1 | 1 | Skye-Lochalsh | w6126 | 9 | 28324 | 1.38 | 16 | POLYGON ((214091.875 841215.188, 218829.000 83... | 2.264207 |
| 1 | 6016 | 1.461990e+09 | 178224.0 | 2 | 2 | Banff-Buchan | w6016 | 39 | 231337 | 8.66 | 16 | POLYGON ((383866.000 865862.000, 398721.000 86... | 0.006762 |
| 2 | 6121 | 1.753090e+09 | 179177.0 | 3 | 3 | Caithness | w6121 | 11 | 83190 | 3.04 | 10 | POLYGON ((311487.000 968650.000, 320989.000 96... | 0.526184 |
| 3 | 5601 | 8.985990e+08 | 128777.0 | 4 | 4 | Berwickshire | w5601 | 9 | 51710 | 2.53 | 24 | POLYGON ((377180.000 672603.000, 386871.656 67... | 0.716931 |
| 4 | 6125 | 5.109870e+09 | 580792.0 | 5 | 5 | Ross-Cromarty | w6125 | 15 | 129271 | 4.26 | 10 | POLYGON ((278680.062 882371.812, 294960.000 88... | 0.211835 |
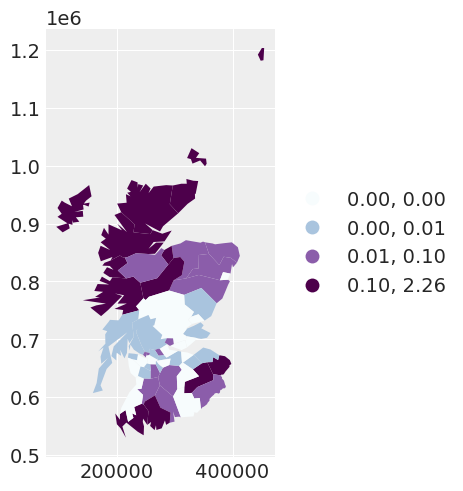
我们最初绘制了每个区域观察到的癌症病例数与预期癌症病例数的关系图。我们在这个图中观察到的空间依赖性表明,我们可能需要考虑为数据建立一个空间模型。
scotland_map = spat_df.plot(
column="PROP",
scheme="QUANTILES",
k=4,
cmap="BuPu",
legend=True,
legend_kwds={"loc": "center left", "bbox_to_anchor": (1, 0.5)},
)
在PyMC中编写一些模型#
我们的第一个模型:一个独立的随机效应模型#
我们首先拟合一个独立的随机效应模型。我们没有对区域之间的空间依赖性进行建模。该模型等价于一个带有正态随机效应的泊松回归模型,数学上看起来像
其中 \(\tau_\text{ind}\) 是独立随机效应精度的未知参数。\(\text{Gamma}\) 先验的值是针对我们的第二个模型选择的,因此我们将推迟到那时再解释我们的选择。
with pm.Model(coords={"area_idx": np.arange(N)}) as independent_model:
beta0 = pm.Normal("beta0", mu=0.0, tau=1.0e-5)
beta1 = pm.Normal("beta1", mu=0.0, tau=1.0e-5)
# variance parameter of the independent random effect
tau_ind = pm.Gamma("tau_ind", alpha=3.2761, beta=1.81)
# independent random effect
theta = pm.Normal("theta", mu=0, tau=tau_ind, dims="area_idx")
# exponential of the linear predictor -> the mean of the likelihood
mu = pm.Deterministic("mu", pt.exp(logE + beta0 + beta1 * x + theta), dims="area_idx")
# likelihood of the observed data
y_i = pm.Poisson("y_i", mu=mu, observed=y, dims="area_idx")
# saving the residual between the observation and the mean response for the area
res = pm.Deterministic("res", y - mu, dims="area_idx")
# sampling the model
independent_idata = pm.sample(2000, tune=2000)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta0, beta1, tau_ind, theta]
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 32 seconds.
我们可以绘制这个第一个模型的残差。
spat_df["INDEPENDENT_RES"] = independent_idata["posterior"]["res"].mean(dim=["chain", "draw"])
independent_map = spat_df.plot(
column="INDEPENDENT_RES",
scheme="QUANTILES",
k=5,
cmap="BuPu",
legend=True,
legend_kwds={"loc": "center left", "bbox_to_anchor": (1, 0.5)},
)
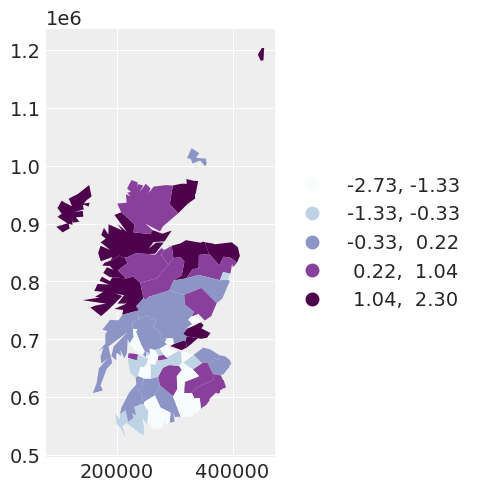
残差的平均值在各区域之间表现出空间相关性。这促使我们通过使用条件自回归(CAR)先验来探索添加一个空间依赖的随机效应。
我们的第二个模型:一个空间随机效应模型(具有固定的空间依赖性)#
让我们先拟合一个模型,该模型为每个区域有两个随机效应:一个是独立的随机效应,另一个是空间的随机效应。这个模型看起来
其中,行 \(\phi_i \big | \mathbf{\phi}_{j\sim i} \sim \text{Normal}\big(\mu=\alpha\sum_{j=1}^{n_i}\phi_j, \tau=\tau_{\text{spat}}\big )\) 表示 CAR 先验,\(\tau_\text{spat}\) 是空间随机效应精度的未知参数,\(\alpha\) 捕捉区域之间的空间依赖程度。在这种情况下,我们固定 \(\alpha=0.95\)。
旁注: 这里我们解释了用于两个随机效应项精度的先验。由于我们有两个随机效应 \(\theta_i\) 和 \(\phi_i\) 对应于每个 \(i\),它们是独立不可识别的,但总和 \(\theta_i + \phi_i\) 是可识别的。然而,通过以这种方式缩放此精度的先验,可能能够解释每个随机效应所解释的方差比例。
with pm.Model(coords={"area_idx": np.arange(N)}) as fixed_spatial_model:
beta0 = pm.Normal("beta0", mu=0.0, tau=1.0e-5)
beta1 = pm.Normal("beta1", mu=0.0, tau=1.0e-5)
# variance parameter of the independent random effect
tau_ind = pm.Gamma("tau_ind", alpha=3.2761, beta=1.81)
# variance parameter of the spatially dependent random effects
tau_spat = pm.Gamma("tau_spat", alpha=1.0, beta=1.0)
# area-specific model parameters
# independent random effect
theta = pm.Normal("theta", mu=0, tau=tau_ind, dims="area_idx")
# spatially dependent random effect, alpha fixed
phi = pm.CAR("phi", mu=np.zeros(N), tau=tau_spat, alpha=0.95, W=adj_matrix, dims="area_idx")
# exponential of the linear predictor -> the mean of the likelihood
mu = pm.Deterministic("mu", pt.exp(logE + beta0 + beta1 * x + theta + phi), dims="area_idx")
# likelihood of the observed data
y_i = pm.Poisson("y_i", mu=mu, observed=y, dims="area_idx")
# saving the residual between the observation and the mean response for the area
res = pm.Deterministic("res", y - mu, dims="area_idx")
# sampling the model
fixed_spatial_idata = pm.sample(2000, tune=2000)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta0, beta1, tau_ind, tau_spat, theta, phi]
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 55 seconds.
通过绘制第二个模型的残差,通过使用CAR先验考虑空间依赖性,我们可以看到模型的残差在空间位置上显得更加独立。
spat_df["SPATIAL_RES"] = fixed_spatial_idata["posterior"]["res"].mean(dim=["chain", "draw"])
fixed_spatial_map = spat_df.plot(
column="SPATIAL_RES",
scheme="quantiles",
k=5,
cmap="BuPu",
legend=True,
legend_kwds={"loc": "center left", "bbox_to_anchor": (1, 0.5)},
)
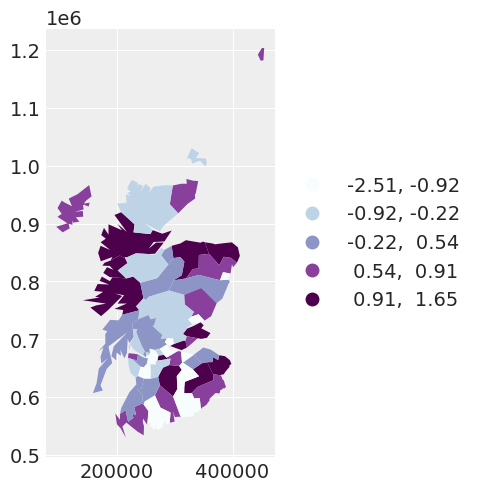
如果我们想要对所指定的模型进行完全贝叶斯处理,我们会估计空间依赖性参数\(\alpha\)。这导致了……
我们的第三个模型:一个具有未知空间依赖性的空间随机效应模型#
模型3和模型2之间的唯一区别在于,在模型3中,\(\alpha\) 是未知的,因此我们为其设置了一个先验 \(\alpha \sim \text{Beta} \big (\alpha = 1, \beta=1\big )\)。
with pm.Model(coords={"area_idx": np.arange(N)}) as car_model:
beta0 = pm.Normal("beta0", mu=0.0, tau=1.0e-5)
beta1 = pm.Normal("beta1", mu=0.0, tau=1.0e-5)
# variance parameter of the independent random effect
tau_ind = pm.Gamma("tau_ind", alpha=3.2761, beta=1.81)
# variance parameter of the spatially dependent random effects
tau_spat = pm.Gamma("tau_spat", alpha=1.0, beta=1.0)
# prior for alpha
alpha = pm.Beta("alpha", alpha=1, beta=1)
# area-specific model parameters
# independent random effect
theta = pm.Normal("theta", mu=0, tau=tau_ind, dims="area_idx")
# spatially dependent random effect
phi = pm.CAR("phi", mu=np.zeros(N), tau=tau_spat, alpha=alpha, W=adj_matrix, dims="area_idx")
# exponential of the linear predictor -> the mean of the likelihood
mu = pm.Deterministic("mu", pt.exp(logE + beta0 + beta1 * x + theta + phi), dims="area_idx")
# likelihood of the observed data
y_i = pm.Poisson("y_i", mu=mu, observed=y, dims="area_idx")
# sampling the model
car_idata = pm.sample(2000, tune=2000)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta0, beta1, tau_ind, tau_spat, alpha, theta, phi]
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 65 seconds.
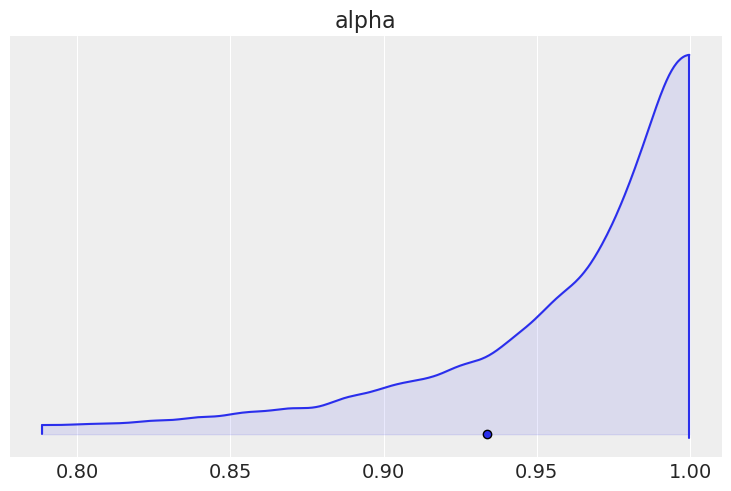
我们可以绘制\(\alpha\)的边际后验分布,并看到它非常接近\(1\),表明存在强烈的空间依赖性。
az.plot_density([car_idata], var_names=["alpha"], shade=0.1)
array([[<AxesSubplot: title={'center': 'alpha'}>]], dtype=object)
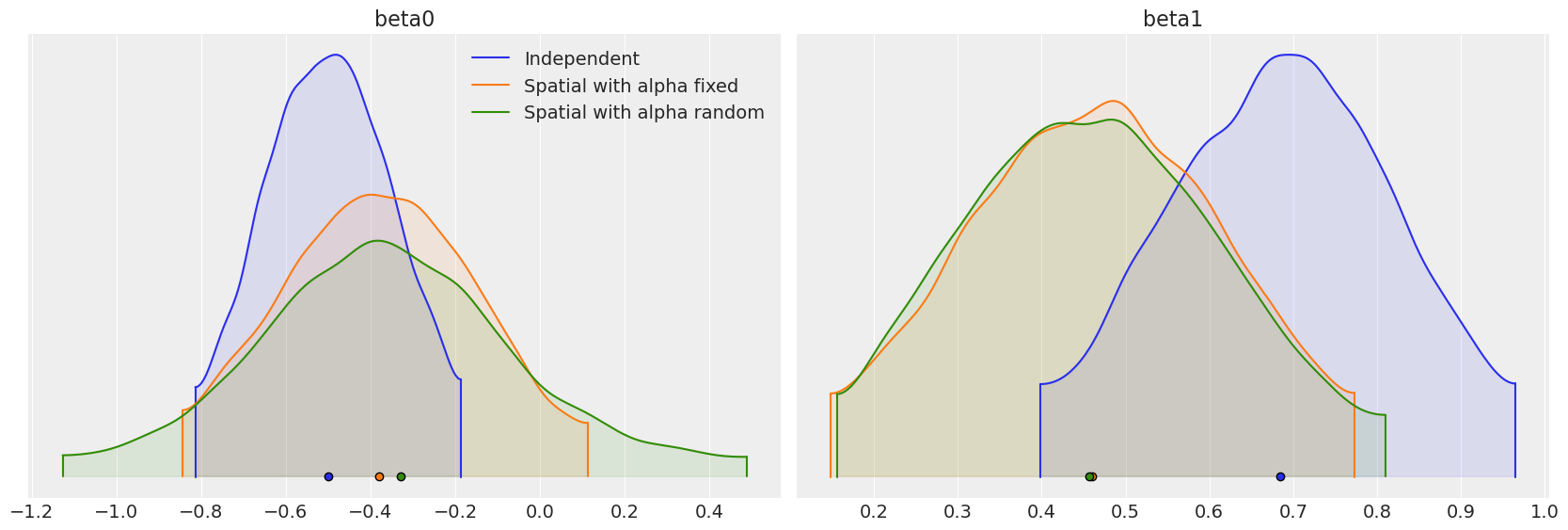
比较我们拟合的三个模型中的回归参数 \(\beta_0\) 和 \(\beta_1\),我们可以看到,考虑观测值之间的空间依赖性能够极大地影响对协变量对响应变量影响的解释。
beta_density = az.plot_density(
[independent_idata, fixed_spatial_idata, car_idata],
data_labels=["Independent", "Spatial with alpha fixed", "Spatial with alpha random"],
var_names=["beta0", "beta1"],
shade=0.1,
)
限制#
我们的最终模型提供了一些证据表明空间依赖参数可能为 \(1\)。然而,在CAR先验的定义中,\(\alpha\) 只能取到并排除 \(1\) 的值。如果 \(\alpha = 1\),我们会得到一个称为 内在条件自回归 (ICAR) 先验的替代先验。ICAR先验在空间模型中更广泛地使用,特别是BYM [Besag 等, 1991]、Leroux [Leroux 等, 2000] 和BYM2 [Riebler 等, 2016] 模型。它还能在大数据集上高效地进行缩放,这是CAR分布的一个限制。目前,正在进行将ICAR先验纳入PyMC的工作。
参考资料#
水印#
%load_ext watermark
%watermark -n -u -v -iv -w -p xarray
Last updated: Mon Jun 05 2023
Python implementation: CPython
Python version : 3.11.0
IPython version : 8.8.0
xarray: 2022.12.0
pymc : 5.0.1
pytensor : 2.8.11
pandas : 1.5.2
numpy : 1.24.1
arviz : 0.14.0
libpysal : 4.7.0
matplotlib: 3.6.2
Watermark: 2.3.1
许可证声明#
本示例库中的所有笔记本均在MIT许可证下提供,该许可证允许修改和重新分发,前提是保留版权和许可证声明。
引用 PyMC 示例#
要引用此笔记本,请使用Zenodo为pymc-examples仓库提供的DOI。
重要
许多笔记本是从其他来源改编的:博客、书籍……在这种情况下,您应该引用原始来源。
同时记得引用代码中使用的相关库。
这是一个BibTeX的引用模板:
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
渲染后可能看起来像: