贝叶斯参数生存分析#
import warnings
import arviz as az
import numpy as np
import pymc as pm
import pytensor.tensor as pt
import scipy as sp
import seaborn as sns
from matplotlib import pyplot as plt
from matplotlib.ticker import StrMethodFormatter
from statsmodels import datasets
print(f"Running on PyMC v{pm.__version__}")
Running on PyMC v5.16.2
%config InlineBackend.figure_format = 'retina'
az.style.use("arviz-darkgrid")
warnings.filterwarnings("ignore")
生存分析研究从受试者进入观察到发生感兴趣事件之间的时间分布。生存分析的一个基本挑战(这也使其在数学上变得有趣)是,通常情况下,并非所有受试者在我们进行分析之前都会经历感兴趣的事件。更具体地说,如果我们研究癌症治疗与死亡之间的时间(正如我们将在本文中讨论的),我们通常希望在所有受试者死亡之前分析我们的数据。这种现象称为删失,是生存分析的基础。
这篇文章展示了在PyMC中使用参数化方法进行贝叶斯生存分析。参数化生存模型在实现和理解上都比半参数化模型更简单;从统计学角度来看,当它们被正确指定时,它们也比非参数化或半参数化方法更强大。关于半参数化 Cox比例风险模型的示例,您可以阅读这篇博客文章,但请注意,该文章使用了旧版本的PyMC,并且在PyMC中实现半参数化模型涉及一些相当复杂的numpy代码和不太明显的概率论等价性。
sns.set()
blue, green, red, purple, gold, teal = sns.color_palette(n_colors=6)
pct_formatter = StrMethodFormatter("{x:.1%}")
df = datasets.get_rdataset("mastectomy", "HSAUR", cache=True).data.assign(
metastized=lambda df: 1.0 * (df.metastized == "yes"), event=lambda df: 1.0 * df.event
)
df.head()
| time | event | metastized | |
|---|---|---|---|
| 0 | 23 | 1.0 | 0.0 |
| 1 | 47 | 1.0 | 0.0 |
| 2 | 69 | 1.0 | 0.0 |
| 3 | 70 | 0.0 | 0.0 |
| 4 | 100 | 0.0 | 0.0 |
列 time 表示乳腺癌患者在乳房切除术后存活的时间,以月为单位。列 event 表示观察是否被删失。如果 event 为1,表示在研究期间观察到了患者的死亡;如果 event 为0,表示患者在研究结束时仍然存活,其生存时间被删失。列 metastized 表示癌症在乳房切除术前是否已经转移。在这篇文章中,我们将使用贝叶斯参数生存回归来量化癌症已经转移和未转移的患者在生存时间上的差异。
加速失效时间模型#
加速失效时间模型是最常见的参数生存回归模型类型。生存分析的基本量是生存函数;如果\(T\)是表示事件发生时间的随机变量,则生存函数为\(S(t) = P(T > t)\)。加速失效时间模型将协变量\(\mathbf{x}\)纳入生存函数中,如下所示:
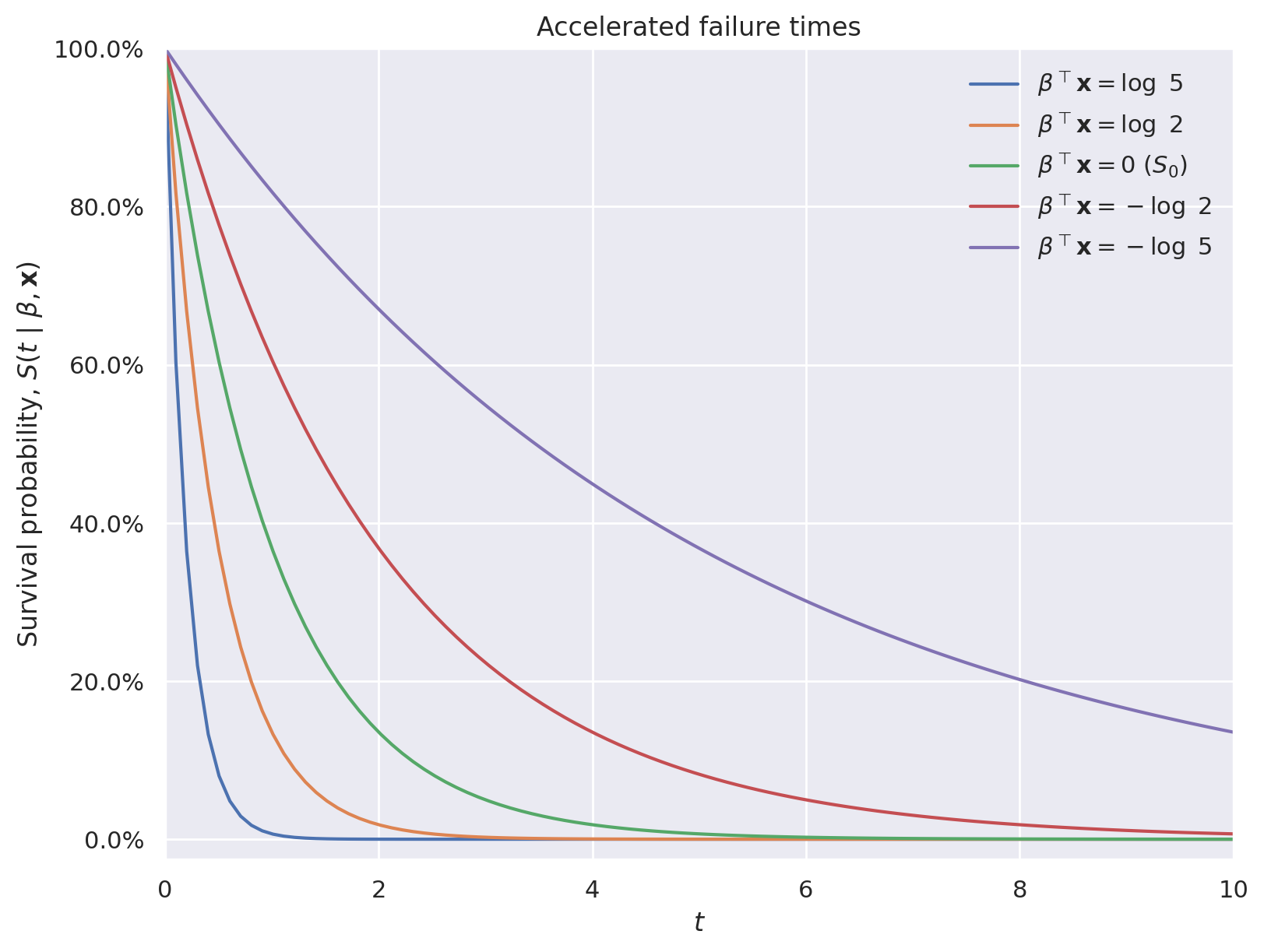
其中 \(S_0(t)\) 是一个固定的基准生存函数。这些模型被称为“加速失效时间”模型,因为当 \(\beta^{\top} \mathbf{x} > 0\) 时,\(\exp\left(\beta^{\top} \mathbf{x}\right) \cdot t > t\),因此协变量的作用是加速所讨论个体的有效时间流逝。下图使用指数生存函数说明了这一现象。
S0 = sp.stats.expon.sf
fig, ax = plt.subplots(figsize=(8, 6))
t = np.linspace(0, 10, 100)
ax.plot(t, S0(5 * t), label=r"$\beta^{\top} \mathbf{x} = \log\ 5$")
ax.plot(t, S0(2 * t), label=r"$\beta^{\top} \mathbf{x} = \log\ 2$")
ax.plot(t, S0(t), label=r"$\beta^{\top} \mathbf{x} = 0$ ($S_0$)")
ax.plot(t, S0(0.5 * t), label=r"$\beta^{\top} \mathbf{x} = -\log\ 2$")
ax.plot(t, S0(0.2 * t), label=r"$\beta^{\top} \mathbf{x} = -\log\ 5$")
ax.set_xlim(0, 10)
ax.set_xlabel(r"$t$")
ax.yaxis.set_major_formatter(pct_formatter)
ax.set_ylim(-0.025, 1)
ax.set_ylabel(r"Survival probability, $S(t\ |\ \beta, \mathbf{x})$")
ax.legend(loc=1)
ax.set_title("Accelerated failure times");
加速失效时间模型等价于\(T\)的对数线性模型,
误差项 \(\varepsilon\) 的分布选择决定了加速失效时间模型的基线生存函数 \(S_0\)。下表显示了几种常见加速失效时间模型中 \(\varepsilon\) 的分布与 \(S_0\) 之间的对应关系。
对数线性误差分布(\(\varepsilon\)) |
基线生存函数(\(S_0\)) |
|---|---|
极值(Gumbel) |
|
加速失效时间模型通常以其基线生存函数命名,\(S_0\)。本文的其余部分将展示如何使用 PyMC 实现 Weibull 和对数逻辑生存回归模型,使用的是乳房切除术数据。
Weibull生存回归#
在这个例子中,协变量是 \(\mathbf{x}_i = \left(1\ x^{\textrm{met}}_i\right)^{\top}\),其中
我们构建协变量矩阵 \(\mathbf{X}\)。
数据的似然性分为两部分指定,一部分用于未删失的样本,另一部分用于删失的样本。由于 \(Y = \eta + \varepsilon\),且 \(\varepsilon \sim \textrm{Gumbel}(0, s)\),因此 \(Y \sim \textrm{Gumbel}(\eta, s)\)。对于未删失的生存时间,似然性实现为
with weibull_model:
censored = pm.Data("censored", df.event.values == 0.0)
我们将观测到的时间转换为对数尺度并进行标准化。
我们对回归系数放置独立的、模糊的正态先验分布,
协变量, \(\mathbf{x}\), 通过 \(\eta = \beta^{\top} \mathbf{x}\) 影响 \(Y = \log T\) 的值。
with weibull_model:
eta = beta.dot(predictors.T)
对于Weibull回归,我们使用
with weibull_model:
s = pm.HalfNormal("s", 5.0)
对于截尾观测,我们只知道它们的实际生存时间超过了它们被观察的总时间。这个概率由Gumbel分布的生存函数给出,
此生存函数在下面实现。
我们现在指定截尾观测的似然函数。
with weibull_model:
censored_like = pm.Potential("censored_like", gumbel_sf(y_cens, eta[censored], s))
我们现在从模型中进行采样。
SEED = 845199 # from random.org, for reproducibility
SAMPLE_KWARGS = {"chains": 4, "tune": 1000, "random_seed": [SEED + i for i in range(4)]}
with weibull_model:
weibull_trace = pm.sample(**SAMPLE_KWARGS)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta, s]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
能量图和缺失信息的贝叶斯分数没有引起对NUTS中混合不良的担忧。
az.plot_energy(weibull_trace, fill_color=("C0", "C1"));
统计量 \(\hat{R}\) 也表明收敛。
<xarray.DataArray 'beta' ()> Size: 8B array(1.00442271)
下面我们绘制参数的后验分布。
az.plot_forest(weibull_trace, figsize=(10, 4));
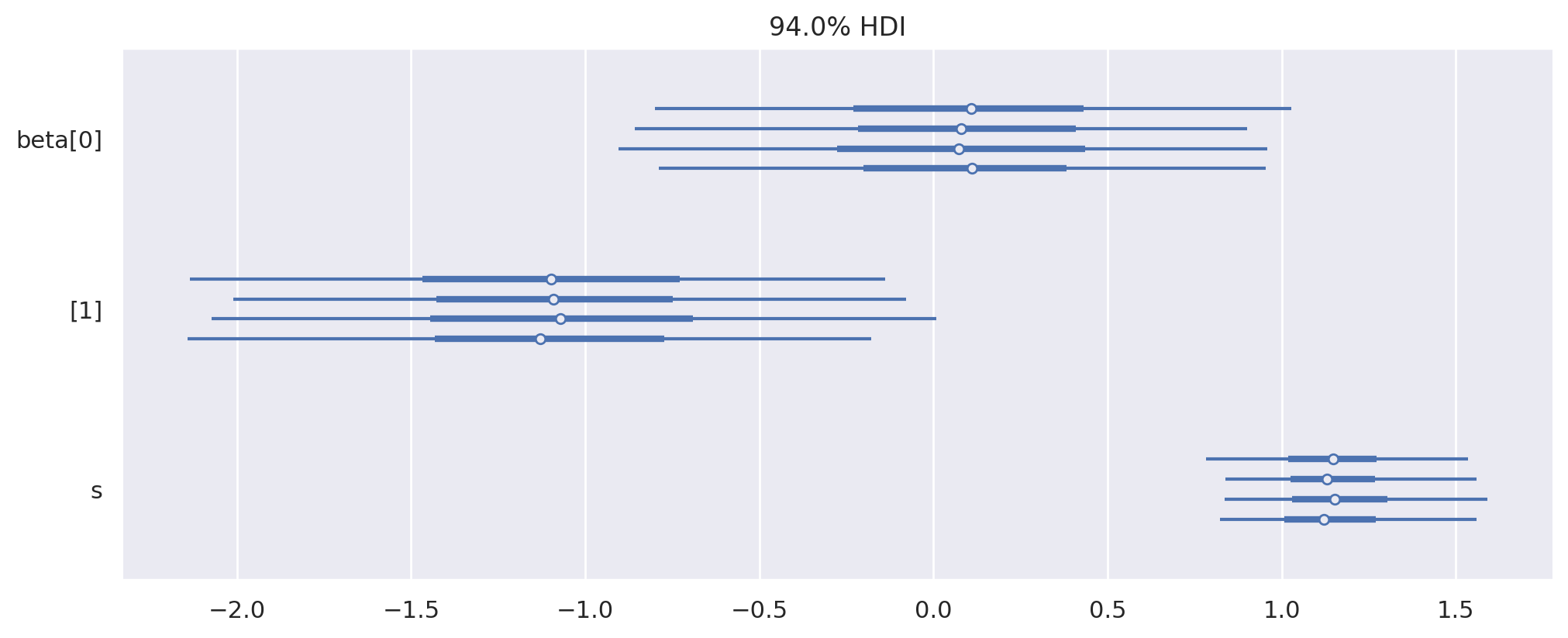
这些有些有趣(特别是\(\beta_1\)的后验分布与零有相当好的分离),但后验预测生存曲线将更具可解释性。
使用数据变量的优势在于,我们现在可以更改它们的值以执行后验预测采样。对于后验预测,我们将\(X\)设置为具有两行,一行用于癌症未转移的受试者,另一行用于癌症已转移的受试者。由于我们想要预测实际的生存时间,因此后验预测的行均未被删失。
X_pp = np.empty((2, 2))
X_pp[:, 0] = 1.0
X_pp[:, 1] = [0, 1]
cens_pp = np.repeat(False, 2)
with weibull_model:
pm.set_data(
{"predictors": X_pp, "censored": cens_pp, "y_obs": np.zeros(2), "y_cens": np.zeros(0)}
)
with weibull_model:
pp_weibull_trace = pm.sample_posterior_predictive(weibull_trace)
Sampling: [events]
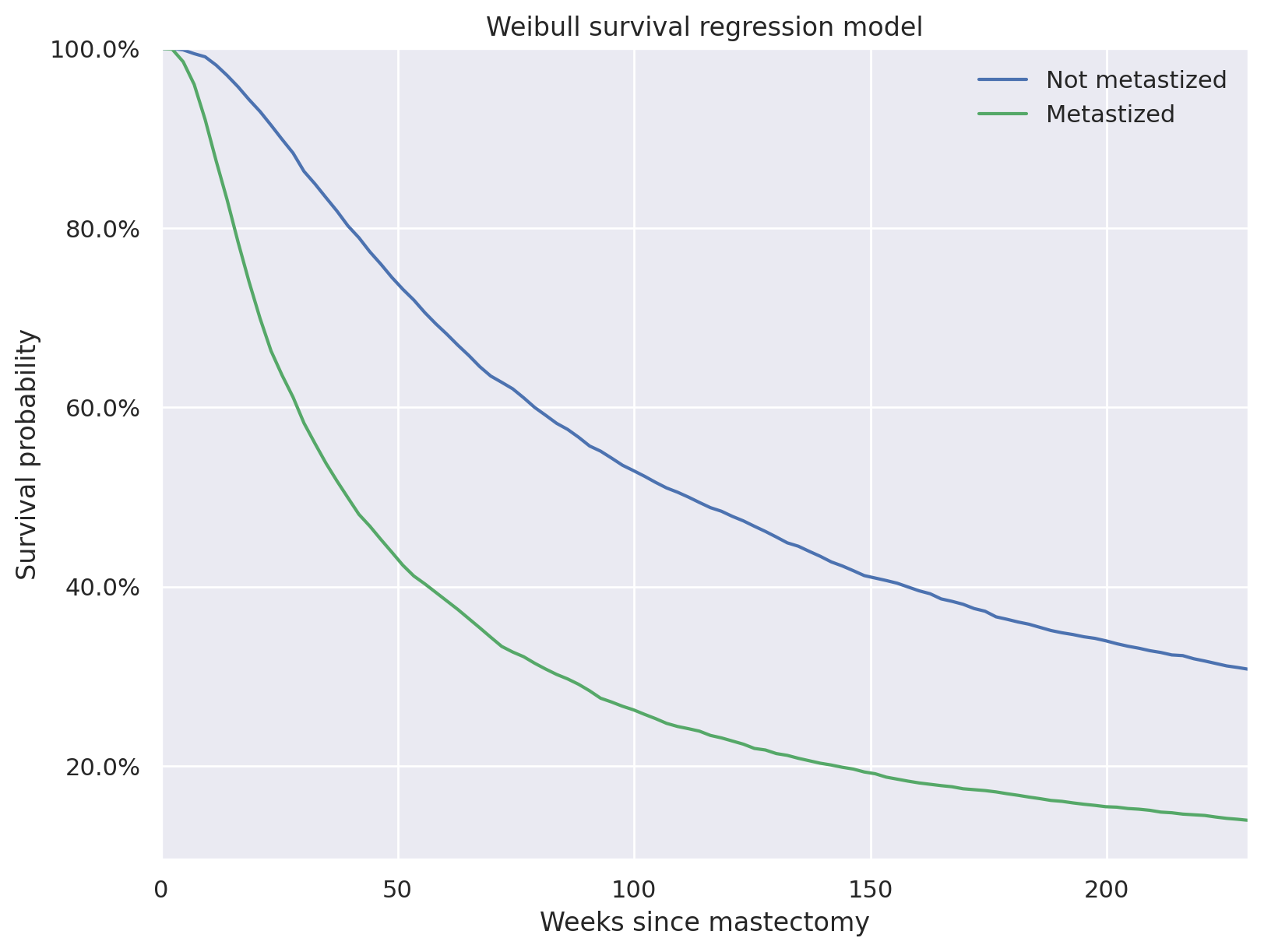
后验预测生存时间显示,平均而言,癌症未转移的患者比癌症已转移的患者存活时间更长。
t_plot = np.linspace(0, 230, 100)
weibull_pp_surv = np.greater_equal.outer(
np.exp(
y.mean()
+ y.std() * az.extract(pp_weibull_trace.posterior_predictive["events"])["events"].values
),
t_plot,
)
weibull_pp_surv_mean = weibull_pp_surv.mean(axis=1)
fig, ax = plt.subplots(figsize=(8, 6))
ax.plot(t_plot, weibull_pp_surv_mean[0], c=blue, label="Not metastized")
ax.plot(t_plot, weibull_pp_surv_mean[1], c=red, label="Metastized")
ax.set_xlim(0, 230)
ax.set_xlabel("Weeks since mastectomy")
ax.set_ylim(top=1)
ax.yaxis.set_major_formatter(pct_formatter)
ax.set_ylabel("Survival probability")
ax.legend(loc=1)
ax.set_title("Weibull survival regression model");
对数-逻辑生存回归#
其他加速失效时间模型可以通过改变\(\varepsilon\)的先验分布以模块化的方式指定。对数逻辑模型对应于\(\varepsilon\)上的逻辑先验。大多数模型规范与上述Weibull模型相同。
with pm.Model() as log_logistic_model:
predictors = pm.Data("predictors", X)
censored = pm.Data("censored", df.event.values == 0.0)
y_obs = pm.Data("y_obs", y_std[df.event.values == 1.0])
y_cens = pm.Data("y_cens", y_std[df.event.values == 0.0])
beta = pm.Normal("beta", 0.0, 5.0, shape=2)
eta = beta.dot(predictors.T)
s = pm.HalfNormal("s", 5.0)
我们使用先验 \(\varepsilon \sim \textrm{Logistic}(0, s)\)。 逻辑分布的生存函数是
所以我们得到了似然值
def logistic_sf(y, mu, s):
return 1.0 - pm.math.sigmoid((y - mu) / s)
with log_logistic_model:
events = pm.Logistic("events", eta[~censored], s, observed=y_obs)
censored_like = pm.Potential("censored_like", logistic_sf(y_cens, eta[censored], s))
我们现在从对数逻辑模型中进行采样。
with log_logistic_model:
log_logistic_trace = pm.sample(**SAMPLE_KWARGS)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta, s]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.
该模型的所有采样诊断结果看起来都很好。
az.plot_energy(log_logistic_trace, fill_color=("C0", "C1"));
<xarray.DataArray 'beta' ()> Size: 8B array(1.00301488)
再次,我们计算该模型的后验期望生存函数。
with log_logistic_model:
pm.set_data(
{"predictors": X_pp, "censored": cens_pp, "y_obs": np.zeros(2), "y_cens": np.zeros(0)}
)
pp_log_logistic_trace = pm.sample_posterior_predictive(log_logistic_trace)
Sampling: [events]
log_logistic_pp_surv = np.greater_equal.outer(
np.exp(
y.mean()
+ y.std()
* az.extract(pp_log_logistic_trace.posterior_predictive["events"])["events"].values
),
t_plot,
)
log_logistic_pp_surv_mean = log_logistic_pp_surv.mean(axis=1)
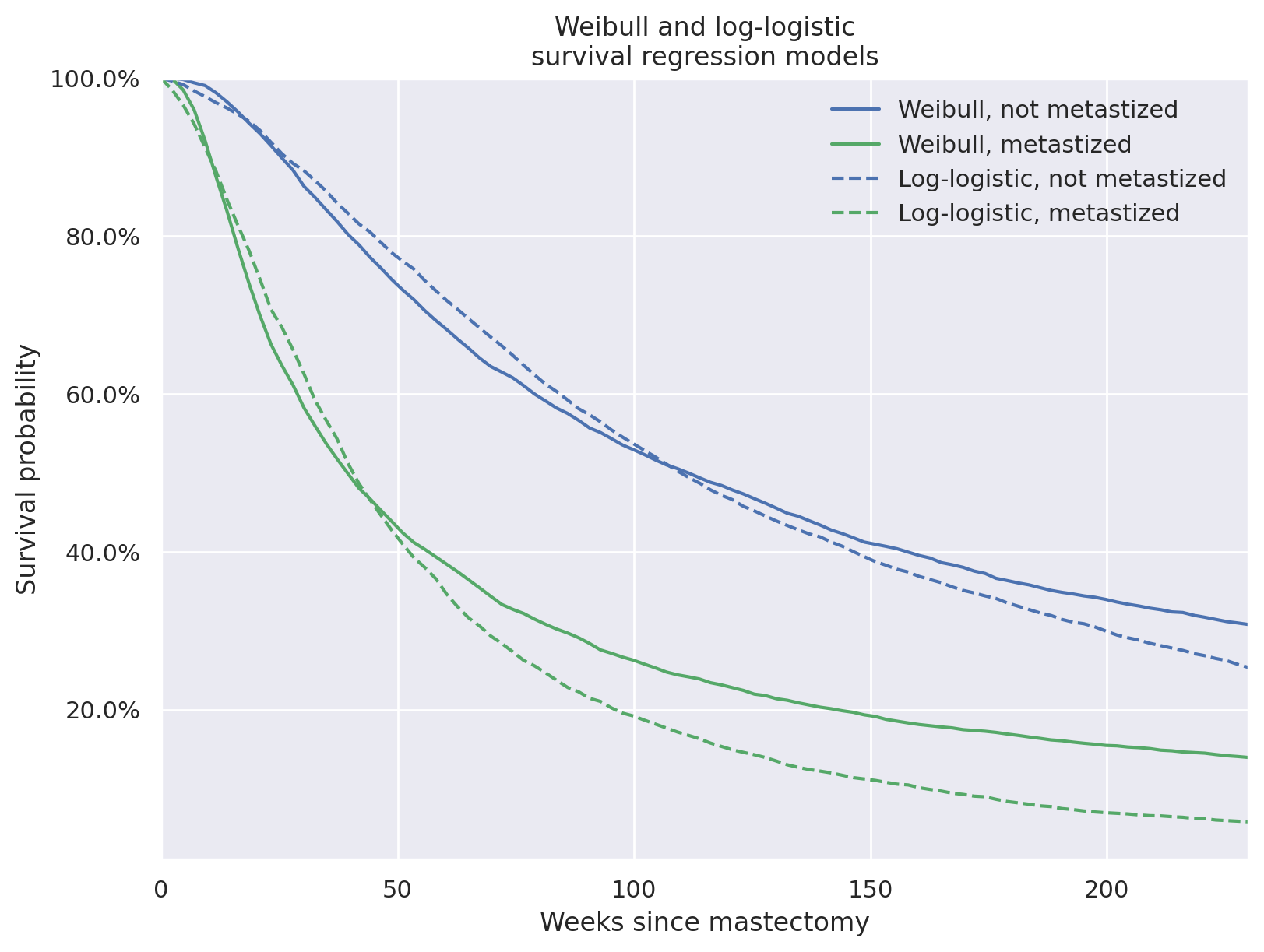
fig, ax = plt.subplots(figsize=(8, 6))
ax.plot(t_plot, weibull_pp_surv_mean[0], c=blue, label="Weibull, not metastized")
ax.plot(t_plot, weibull_pp_surv_mean[1], c=red, label="Weibull, metastized")
ax.plot(t_plot, log_logistic_pp_surv_mean[0], "--", c=blue, label="Log-logistic, not metastized")
ax.plot(t_plot, log_logistic_pp_surv_mean[1], "--", c=red, label="Log-logistic, metastized")
ax.set_xlim(0, 230)
ax.set_xlabel("Weeks since mastectomy")
ax.set_ylim(top=1)
ax.yaxis.set_major_formatter(pct_formatter)
ax.set_ylabel("Survival probability")
ax.legend(loc=1)
ax.set_title("Weibull and log-logistic\nsurvival regression models");
这篇文章是对在PyMC中使用一个相当简单的数据集实现参数化生存回归模型的简短介绍。PyMC的概率编程的模块化特性应该使得将这些技术推广到更复杂和有趣的数据集变得简单。