


辛普森悖论#
辛普森悖论描述了一种情况,即在某个组内两个变量之间可能存在负相关关系,但当来自多个组的数据合并时,这种关系可能会消失甚至反转符号。下面的动图(来自辛普森悖论的维基百科页面)很好地展示了这一点。

另一种描述这个问题的方式是,我们希望估计因果关系 \(x \rightarrow y\)。看似明显的方法是建模 y ~ 1 + x,这将导致我们得出结论(在上述情况下)增加 \(x\) 会导致 \(y\) 减少(见下面的模型1)。然而,\(x\) 和 \(y\) 之间的关系被一个组别变量 \(group\) 混淆了。这个组别变量没有包含在模型中,因此 \(x\) 和 \(y\) 之间的关系是有偏的。如果我们现在考虑 \(group\) 的影响,在某些情况下(例如上图),这可能导致我们完全逆转对 \(x \rightarrow y\) 的估计符号,现在估计增加 \(x\) 会导致 \(y\) 增加。
简而言之,这个“悖论”(或简单地说是遗漏变量偏差)可以通过假设一个因果DAG来解决,该DAG包括主要预测变量和群体成员(混杂变量)如何影响结果变量。我们展示了一个例子,其中我们没有纳入群体成员(因此我们的因果DAG是错误的,或者换句话说,我们的模型是错误指定的;模型1)。然后,我们展示了通过将群体成员作为对\(x\)和\(y\)的因果影响来解决这个问题的两种方法。这在未合并模型(模型2)和层次模型(模型3)中展示。
import arviz as az
import graphviz as gr
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import seaborn as sns
import xarray as xr
%config InlineBackend.figure_format = 'retina'
az.style.use("arviz-darkgrid")
figsize = [12, 4]
plt.rcParams["figure.figsize"] = figsize
rng = np.random.default_rng(1234)
生成数据#
此数据生成受到这个stackexchange问题的启发。它将包含来自\(G=5\)个组的观察结果。数据构建的方式是,每个组内\(x\)和\(y\)之间存在负相关关系,但当所有组合并时,关系变为正相关。
def generate():
group_list = ["one", "two", "three", "four", "five"]
trials_per_group = 20
group_intercepts = rng.normal(0, 1, len(group_list))
group_slopes = np.ones(len(group_list)) * -0.5
group_mx = group_intercepts * 2
group = np.repeat(group_list, trials_per_group)
subject = np.concatenate(
[np.ones(trials_per_group) * i for i in np.arange(len(group_list))]
).astype(int)
intercept = np.repeat(group_intercepts, trials_per_group)
slope = np.repeat(group_slopes, trials_per_group)
mx = np.repeat(group_mx, trials_per_group)
x = rng.normal(mx, 1)
y = rng.normal(intercept + (x - mx) * slope, 1)
data = pd.DataFrame({"group": group, "group_idx": subject, "x": x, "y": y})
return data, group_list
data, group_list = generate()
为了更好地理解,清楚地了解数据的格式是非常有用的。这是长格式数据(也称为窄数据),因为每一行代表一个观察值。我们有一个group列,其中包含组标签,以及一个伴随的数值group_idx列。这在建模时非常有用,因为我们可以将其用作索引来查找组级别的参数估计值。最后,我们有预测变量x和结果y的核心观察值。
display(data)
| group | group_idx | x | y | |
|---|---|---|---|---|
| 0 | one | 0 | -0.294574 | -2.338519 |
| 1 | one | 0 | -4.686497 | -1.448057 |
| 2 | one | 0 | -2.262201 | -1.393728 |
| 3 | one | 0 | -4.873809 | -0.265403 |
| 4 | one | 0 | -2.863929 | -0.774251 |
| ... | ... | ... | ... | ... |
| 95 | five | 4 | 3.981413 | 0.467970 |
| 96 | five | 4 | 1.889102 | 0.553290 |
| 97 | five | 4 | 2.561267 | 2.590966 |
| 98 | five | 4 | 0.147378 | 2.050944 |
| 99 | five | 4 | 2.738073 | 0.517918 |
100行 × 4列
我们可以如下所示地可视化这一点。
fig, ax = plt.subplots(figsize=(8, 6))
sns.scatterplot(data=data, x="x", y="y", hue="group", ax=ax);
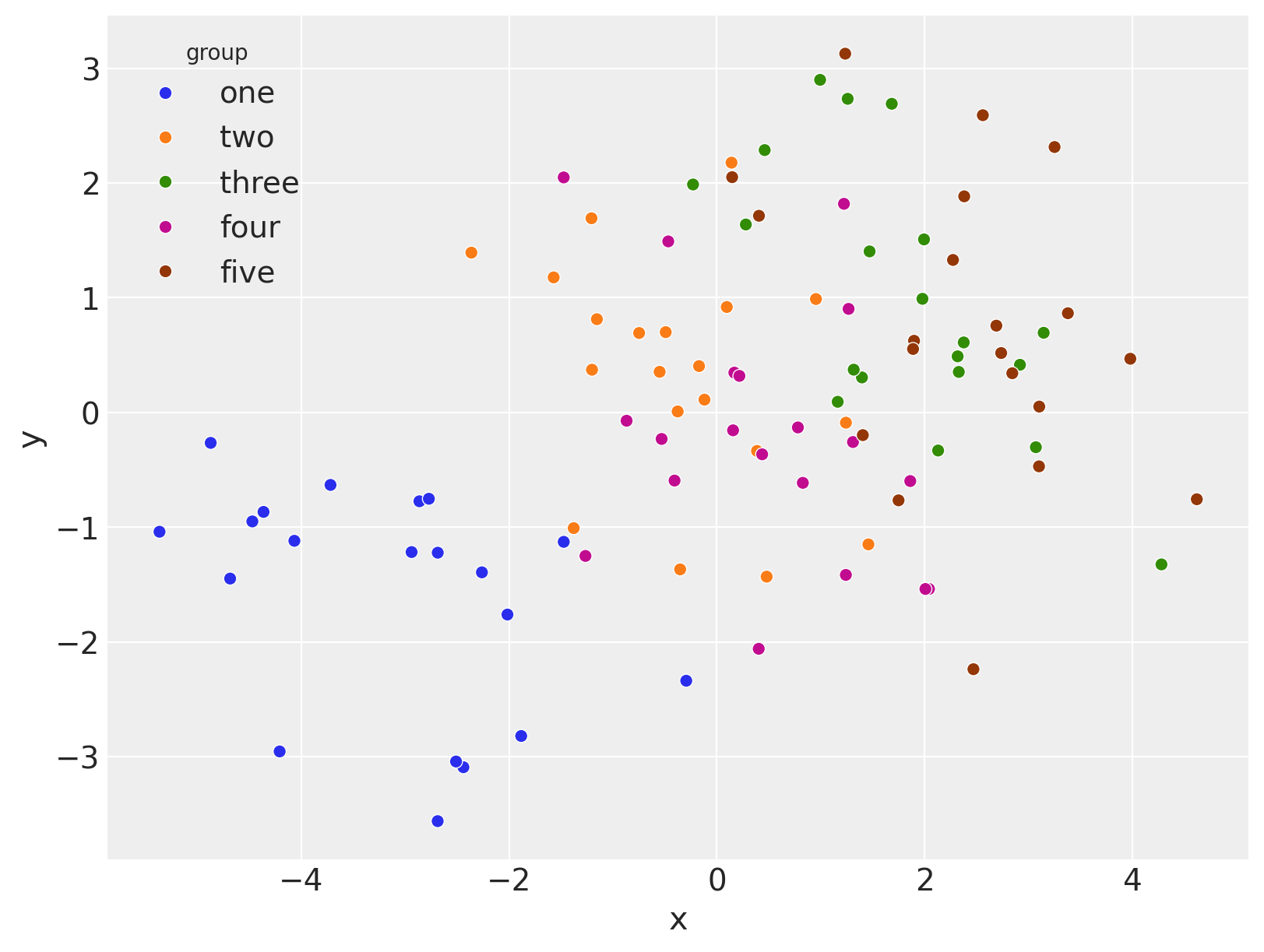
笔记本的其余部分将介绍使用线性模型分析此数据的不同方法。
模型 1:合并回归#
首先我们考察最简单的模型——普通线性回归,它将所有数据汇总,并且不了解数据的组/多层次结构。
从因果关系的角度来看,这种方法体现了这样一种信念,即\(x\)导致\(y\),并且这种关系在所有群体中都是恒定的,或者群体根本不被考虑。这可以在下面的因果DAG中展示。
Show code cell source
g = gr.Digraph()
g.node(name="x", label="x")
g.node(name="y", label="y")
g.edge(tail_name="x", head_name="y")
g

我们可以用数学方式描述这个模型为:
注意
我们也可以用Wilkinson符号将模型1表示为 y ~ 1 + x,这与 y ~ x 等价,因为默认情况下包含截距。
术语
1对应于截距项 \(\beta_0\)。术语
x对应于斜率项 \(\beta_1\)。
所以现在我们可以将其表示为一个 PyMC 模型。我们可以注意到模型的语法与上述数学符号的相似程度。
我们可以可视化DAG,这是一种检查我们的模型是否正确指定的好方法。
pm.model_to_graphviz(model1)

进行推理#
with model1:
idata1 = pm.sample(random_seed=rng)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [β0, β1, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
az.plot_trace(idata1, var_names=["~μ"]);
可视化#
首先,我们将定义一个方便的预测函数,该函数将为我们进行样本外预测。这在可视化模型拟合时将非常方便。
def predict(model: pm.Model, idata: az.InferenceData, predict_at: dict) -> az.InferenceData:
"""Do posterior predictive inference at a set of out of sample points specified by `predict_at`."""
with model:
pm.set_data(predict_at)
idata.extend(pm.sample_posterior_predictive(idata, var_names=["y", "μ"], random_seed=rng))
return idata
现在让我们使用predict函数来进行样本外预测,我们将使用这些预测结果进行可视化。
xi = np.linspace(data.x.min(), data.x.max(), 20)
idata1 = predict(
model=model1,
idata=idata1,
predict_at={"x": xi},
)
Show code cell output
Sampling: [y]
最后,我们现在可以可视化模型拟合数据,以及参数空间中的后验分布。
Show code cell source
def plot_band(xi, var: xr.DataArray, ax, color: str):
ax.plot(xi, var.mean(["chain", "draw"]), color=color)
az.plot_hdi(
xi,
var,
hdi_prob=0.6,
color=color,
fill_kwargs={"alpha": 0.2, "linewidth": 0},
ax=ax,
)
az.plot_hdi(
xi,
var,
hdi_prob=0.95,
color=color,
fill_kwargs={"alpha": 0.2, "linewidth": 0},
ax=ax,
)
def plot(idata: az.InferenceData):
fig, ax = plt.subplots(1, 3, figsize=(12, 4))
# conditional mean plot ---------------------------------------------
ax[0].scatter(data.x, data.y, color="k")
plot_band(xi, idata.posterior_predictive.μ, ax=ax[0], color="k")
ax[0].set(xlabel="x", ylabel="y", title="Conditional mean")
# posterior prediction ----------------------------------------------
ax[1].scatter(data.x, data.y, color="k")
plot_band(xi, idata.posterior_predictive.y, ax=ax[1], color="k")
ax[1].set(xlabel="x", ylabel="y", title="Posterior predictive distribution")
# parameter space ---------------------------------------------------
ax[2].scatter(
az.extract(idata, var_names=["β1"]),
az.extract(idata, var_names=["β0"]),
color="k",
alpha=0.01,
rasterized=True,
)
# formatting
ax[2].set(xlabel="slope", ylabel="intercept", title="Parameter space")
ax[2].axhline(y=0, c="k")
ax[2].axvline(x=0, c="k")
plot(idata1)
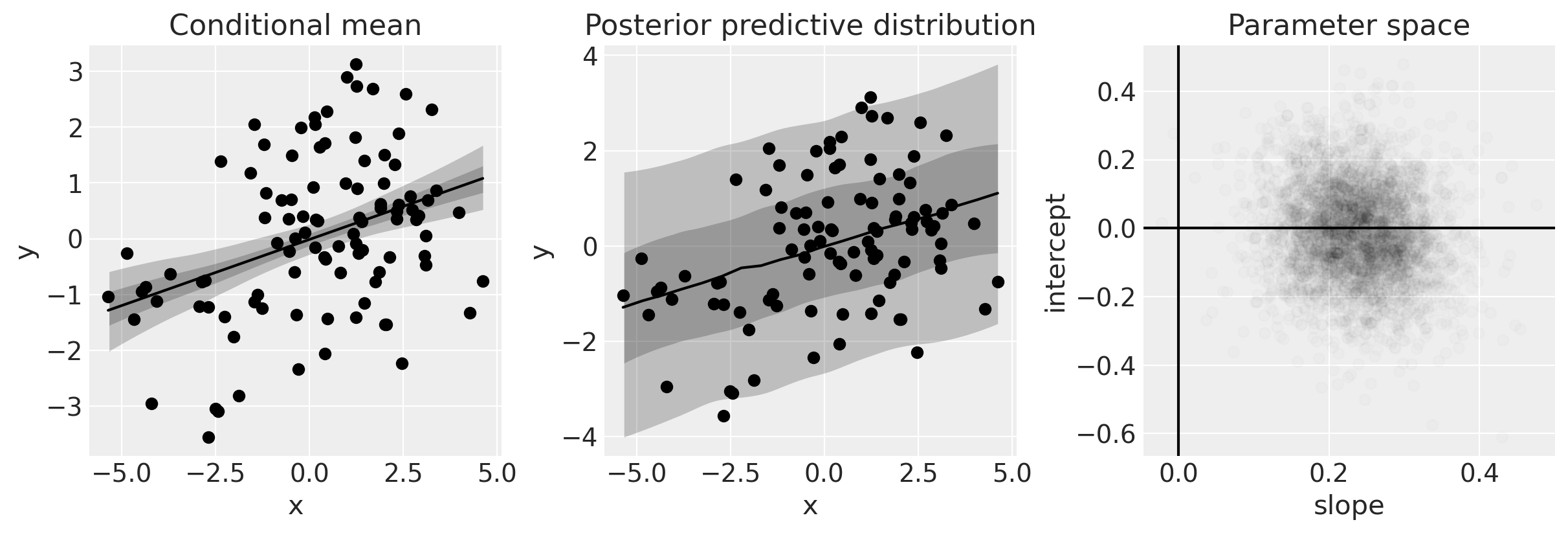
左侧的图显示了数据和条件均值的后验。对于给定的\(x\),我们得到了模型的后验分布(即\(\mu\)的后验分布)。
中间的图显示了条件后验预测分布,它给出了我们对预期数据的描述。直观上,这可以理解为不仅结合了我们对模型的了解(左图),还结合了我们对误差分布的了解。
右侧的图显示了我们在参数空间中的后验信念。
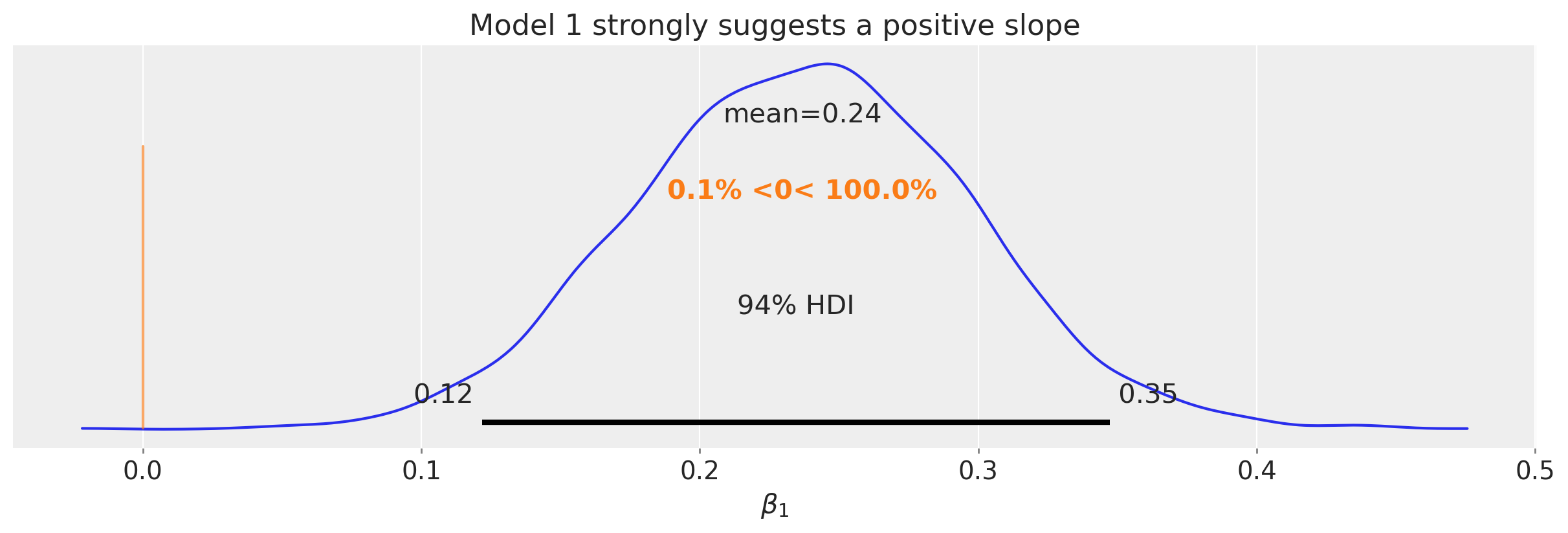
关于这一分析的一个明确之处在于,我们有可信的证据表明 \(x\) 和 \(y\) 是 正 相关的。我们可以从斜率的后验分布中看到这一点(见上图中的右侧面板),我们在下面的图中单独展示了这一点。
Show code cell source
ax = az.plot_posterior(idata1.posterior["β1"], ref_val=0)
ax.set(title="Model 1 strongly suggests a positive slope", xlabel=r"$\beta_1$");
模型 2:包含混杂因素的非池化回归#
我们将在这个分析中使用相同的数据,但这次我们将利用我们的知识,即数据来自不同的组。从因果关系的角度来看,我们正在探讨这样一个概念:\(x\) 和 \(y\) 都受到组别成员身份的影响。这可以在下面的因果有向无环图(DAG)中展示。
Show code cell source
g = gr.Digraph()
g.node(name="x", label="x")
g.node(name="g", label="group")
g.node(name="y", label="y")
g.edge(tail_name="x", head_name="y")
g.edge(tail_name="g", head_name="x")
g.edge(tail_name="g", head_name="y")
g

因此,我们可以看到 \(group\) 是一个 混杂变量。因此,如果我们试图发现 \(x\) 对 \(y\) 的因果关系,我们需要考虑混杂变量 \(group\)。模型1没有这样做,因此得出了错误的结论。但模型2将会考虑这一点。
更具体地说,我们基本上会为每个组内的数据拟合独立的回归。这也可以描述为一个非池化模型。我们可以用数学方式描述这个模型为:
其中 \(g_i\) 是观测值 \(i\) 的组索引。因此,参数 \(\vec{\beta_0}\) 和 \(\vec{\beta_1}\) 现在是长度为 \(G\) 的向量,而不是标量。并且 \([g_i]\) 充当索引,用于查找第 \(i^\text{th}\) 个观测值的组。
注意
我们也可以用Wilkinson符号表示这个模型2为 y ~ 0 + g + x:g。
术语
g捕捉了组特定截距 \(\beta_0[g_i]\) 参数。The
0表示我们没有全局截距项,只保留组特定的截距。术语
x:g捕捉组特定的斜率 \(\beta_1[g_i]\) 参数。
让我们用PyMC代码来表达模型2。
coords = {"group": group_list}
with pm.Model(coords=coords) as model2:
# Define priors
β0 = pm.Normal("β0", 0, sigma=5, dims="group")
β1 = pm.Normal("β1", 0, sigma=5, dims="group")
sigma = pm.Gamma("sigma", 2, 2)
# Data
x = pm.Data("x", data.x, dims="obs_id")
g = pm.Data("g", data.group_idx, dims="obs_id")
# Linear model
μ = pm.Deterministic("μ", β0[g] + β1[g] * x, dims="obs_id")
# Define likelihood
pm.Normal("y", mu=μ, sigma=sigma, observed=data.y, dims="obs_id")
通过绘制该模型的DAG图,可以清楚地看到我们现在为每个组分别设置了截距和斜率参数。
pm.model_to_graphviz(model2)

进行推理#
with model2:
idata2 = pm.sample(random_seed=rng)
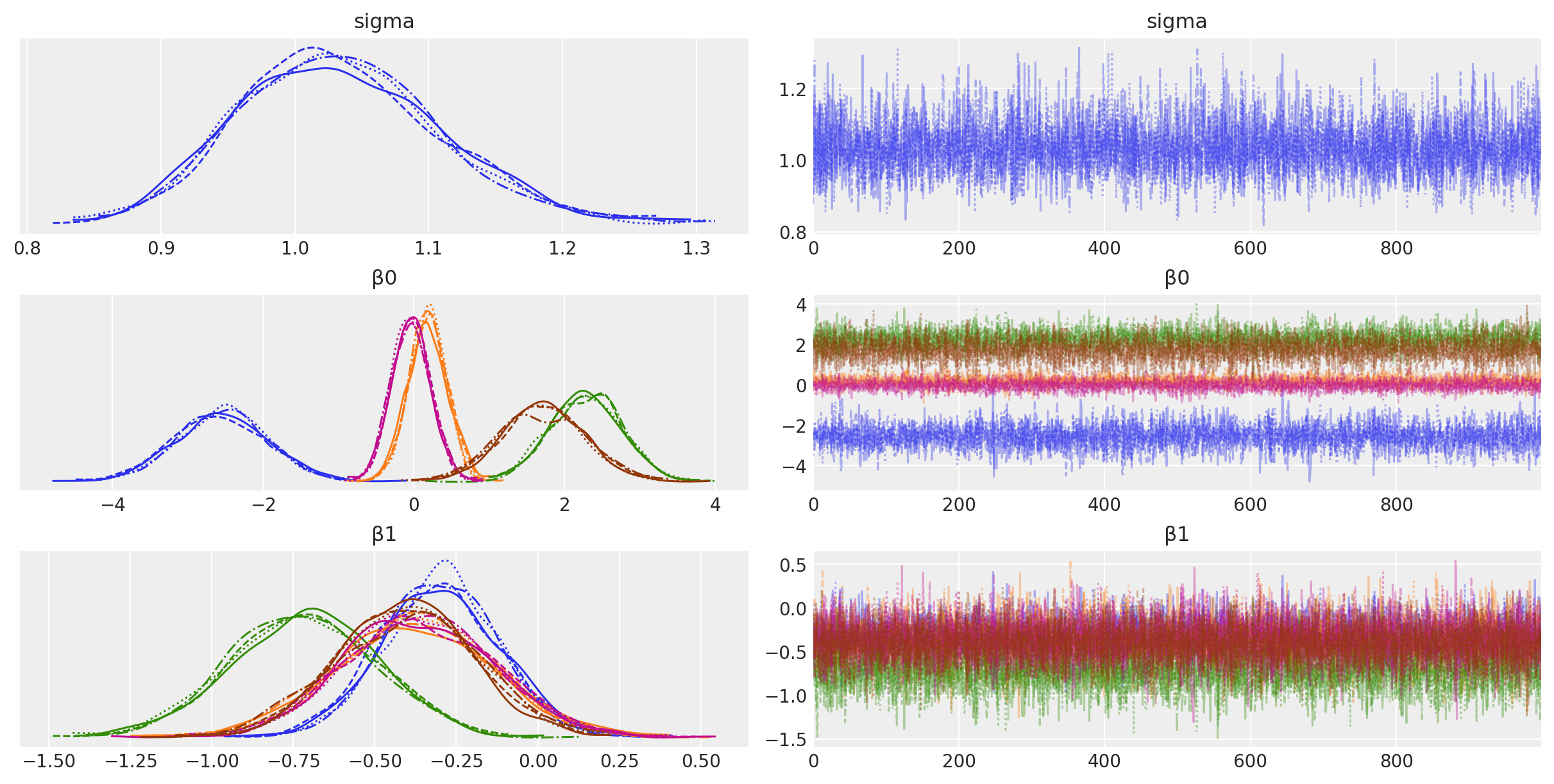
az.plot_trace(idata2, var_names=["~μ"]);
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [β0, β1, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.
可视化#
# Generate values of xi and g for posterior prediction
n_points = 10
n_groups = len(data.group.unique())
# Generate xi values for each group and concatenate them
xi = np.concatenate(
[
np.linspace(group[1].x.min(), group[1].x.max(), n_points)
for group in data.groupby("group_idx")
]
)
# Generate the group indices array g and cast it to integers
g = np.concatenate([[i] * n_points for i in range(n_groups)]).astype(int)
predict_at = {"x": xi, "g": g}
idata2 = predict(
model=model2,
idata=idata2,
predict_at=predict_at,
)
Show code cell output
Sampling: [y]
Show code cell source
def plot(idata):
fig, ax = plt.subplots(1, 3, figsize=(12, 4))
for i in range(len(group_list)):
# conditional mean plot ---------------------------------------------
ax[0].scatter(data.x[data.group_idx == i], data.y[data.group_idx == i], color=f"C{i}")
plot_band(
xi[g == i],
idata.posterior_predictive.μ.isel(obs_id=(g == i)),
ax=ax[0],
color=f"C{i}",
)
# posterior prediction ----------------------------------------------
ax[1].scatter(data.x[data.group_idx == i], data.y[data.group_idx == i], color=f"C{i}")
plot_band(
xi[g == i],
idata.posterior_predictive.y.isel(obs_id=(g == i)),
ax=ax[1],
color=f"C{i}",
)
# formatting
ax[0].set(xlabel="x", ylabel="y", title="Conditional mean")
ax[1].set(xlabel="x", ylabel="y", title="Posterior predictive distribution")
# parameter space ---------------------------------------------------
for i, _ in enumerate(group_list):
ax[2].scatter(
az.extract(idata, var_names="β1")[i, :],
az.extract(idata, var_names="β0")[i, :],
color=f"C{i}",
alpha=0.01,
rasterized=True,
zorder=2,
)
ax[2].set(xlabel="slope", ylabel="intercept", title="Parameter space")
ax[2].axhline(y=0, c="k")
ax[2].axvline(x=0, c="k")
return ax
plot(idata2);
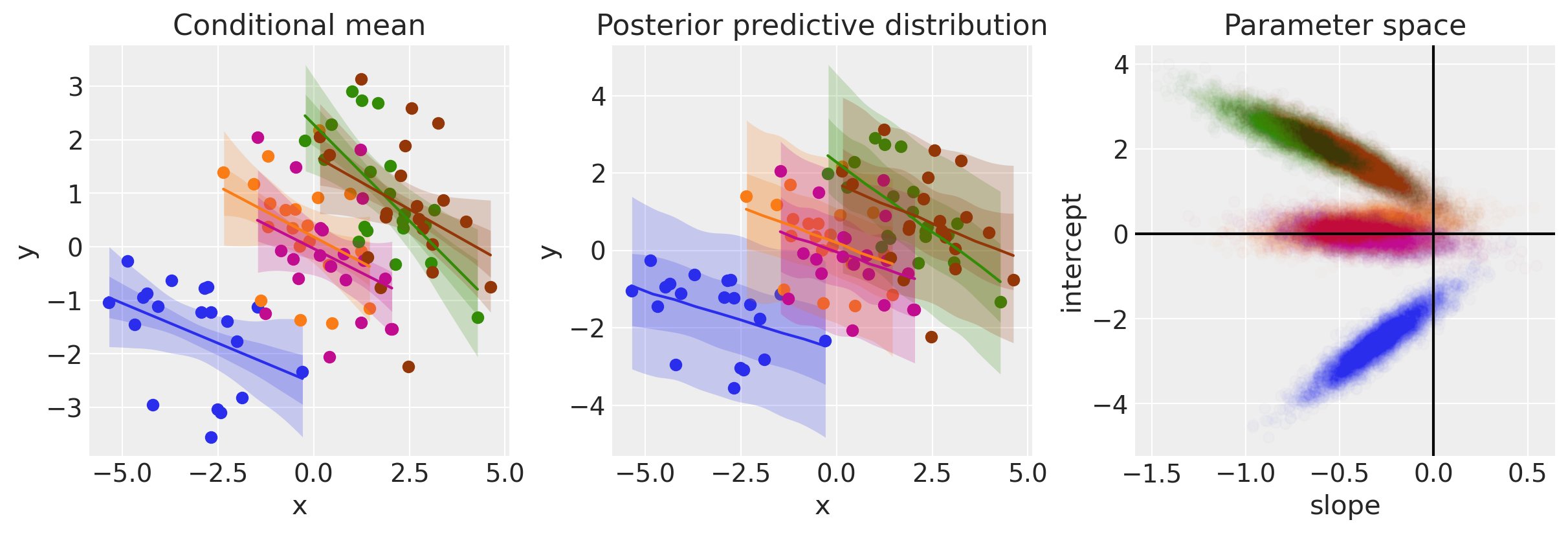
与模型1相比,当我们考虑组别时,我们可以看到现在的证据指向\(x\)和\(y\)之间的负关系。我们可以从上图左侧和中面板的负斜率中看出这一点,也可以从上图左侧斜率参数的后验样本大多数为负值中看出这一点。
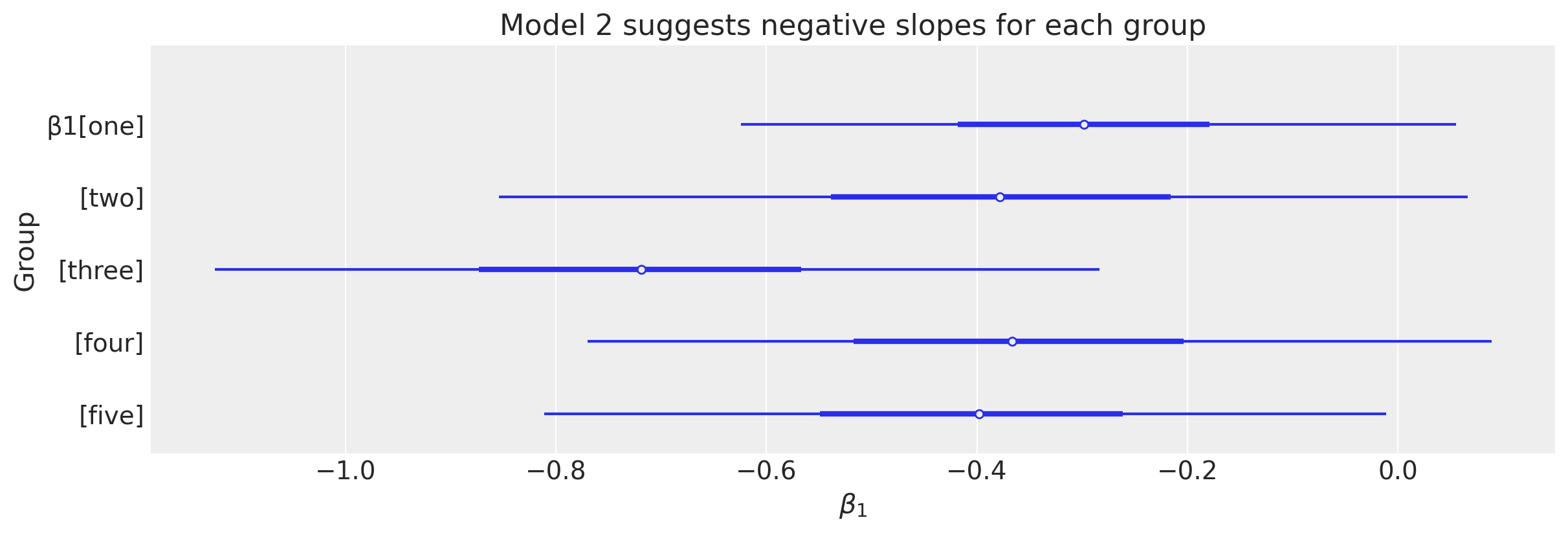
下图更详细地查看了组级别的斜率参数。
Show code cell source
ax = az.plot_forest(idata2.posterior["β1"], combined=True, figsize=figsize)
ax[0].set(
title="Model 2 suggests negative slopes for each group", xlabel=r"$\beta_1$", ylabel="Group"
);
模型 3:包含混杂因素的部分池化模型#
模型3假设与模型2相同的因果DAG(见上文)。然而,我们可以更进一步,结合更多关于数据结构的知识。与其将每个组视为完全独立,我们可以利用这些组是从总体分布中抽取的知识。我们可以将其形式化为:组级别的斜率和截距分别被建模为从总体斜率和截距的偏差。
我们可以用数学方式描述这个模型为:
哪里
\(\beta_0\) 和 \(\beta_1\) 分别是总体水平的截距和斜率。
\(\vec{u_0}\) 和 \(\vec{u_1}\) 是群体水平参数的组级偏差。
\(p_{0\sigma}, p_{1\sigma}\) 是截距和斜率偏差的标准差,可以被视为“收缩参数”。
在极限情况下,\(p_{0\sigma}, p_{1\sigma} \rightarrow \infty\),我们恢复了未合并的模型。
在极限情况下,\(p_{0\sigma}, p_{1\sigma} \rightarrow 0\),我们恢复了合并模型。
注意
我们也可以用Wilkinson符号表示这个模型3为 1 + x + (1 + x | g)。
The
1捕获全局截距,\(\beta_0\)。The
x捕捉全局斜率,\(\beta_1\)。术语
(1 + x | g)捕捉了截距和斜率的组特定项。1 | g捕获了组特定截距偏差 \(\vec{u_0}\) 参数。x | g捕获了组特定斜率偏移 \(\vec{u_1}[g_i]\) 参数。
with pm.Model(coords=coords) as model3:
# Population level priors
β0 = pm.Normal("β0", 0, 5)
β1 = pm.Normal("β1", 0, 5)
# Group level shrinkage
intercept_sigma = pm.Gamma("intercept_sigma", 2, 2)
slope_sigma = pm.Gamma("slope_sigma", 2, 2)
# Group level deflections
u0 = pm.Normal("u0", 0, intercept_sigma, dims="group")
u1 = pm.Normal("u1", 0, slope_sigma, dims="group")
# observations noise prior
sigma = pm.Gamma("sigma", 2, 2)
# Data
x = pm.Data("x", data.x, dims="obs_id")
g = pm.Data("g", data.group_idx, dims="obs_id")
# Linear model
μ = pm.Deterministic("μ", (β0 + u0[g]) + (β1 * x + u1[g] * x), dims="obs_id")
# Define likelihood
pm.Normal("y", mu=μ, sigma=sigma, observed=data.y, dims="obs_id")
该模型的DAG突出了标量总体水平参数 \(\beta_0\) 和 \(\beta_1\) 以及组水平参数 \(\vec{u_0}\) 和 \(\vec{u_1}\)。
pm.model_to_graphviz(model3)

注意
为了完整性,还有另一种等效的方式来编写这个模型。
其中 \(\vec{\beta_0}\) 和 \(\vec{\beta_1}\) 是组级别的参数。这些组级别的参数可以被认为是来自总体级别的截距分布 \(\text{Normal}(p_{0\mu}, p_{0\sigma})\) 和总体级别的斜率分布 \(\text{Normal}(p_{1\mu}, p_{1\sigma})\)。因此,这些分布将代表我们可能对某些尚未观察到的组所期望观察到的内容。
然而,这种模型的表述方式并不能很好地映射到Wilkinson符号上。出于这个原因,我们选择以上述形式呈现模型。关于这个话题的有趣讨论,请参见讨论 #808在bambi仓库中。
另请参阅
我们正在考虑的分层模型包含一个简化,即假设总体水平的斜率和截距是独立的。可以通过使用多元正态分布来放宽这一假设,并建模这些参数之间的任何相关性。有关更多详细信息,请参阅多元正态模型的LKJ Cholesky协方差先验笔记本。
另请参阅
从某种意义上说,从模型2到模型3的转变可以被视为增加了参数,从而增加了模型的复杂性。然而,从另一个角度来看,增加对数据嵌套结构的知识实际上对参数空间施加了约束。可以通过模型比较来在这些模型之间进行仲裁——例如,可以参考GLM: 模型选择笔记本以获取更多详细信息。
进行推理#
with model3:
idata3 = pm.sample(target_accept=0.95, random_seed=rng)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [β0, β1, intercept_sigma, slope_sigma, u0, u1, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 9 seconds.
There were 6 divergences after tuning. Increase `target_accept` or reparameterize.
az.plot_trace(idata3, var_names=["~μ"]);
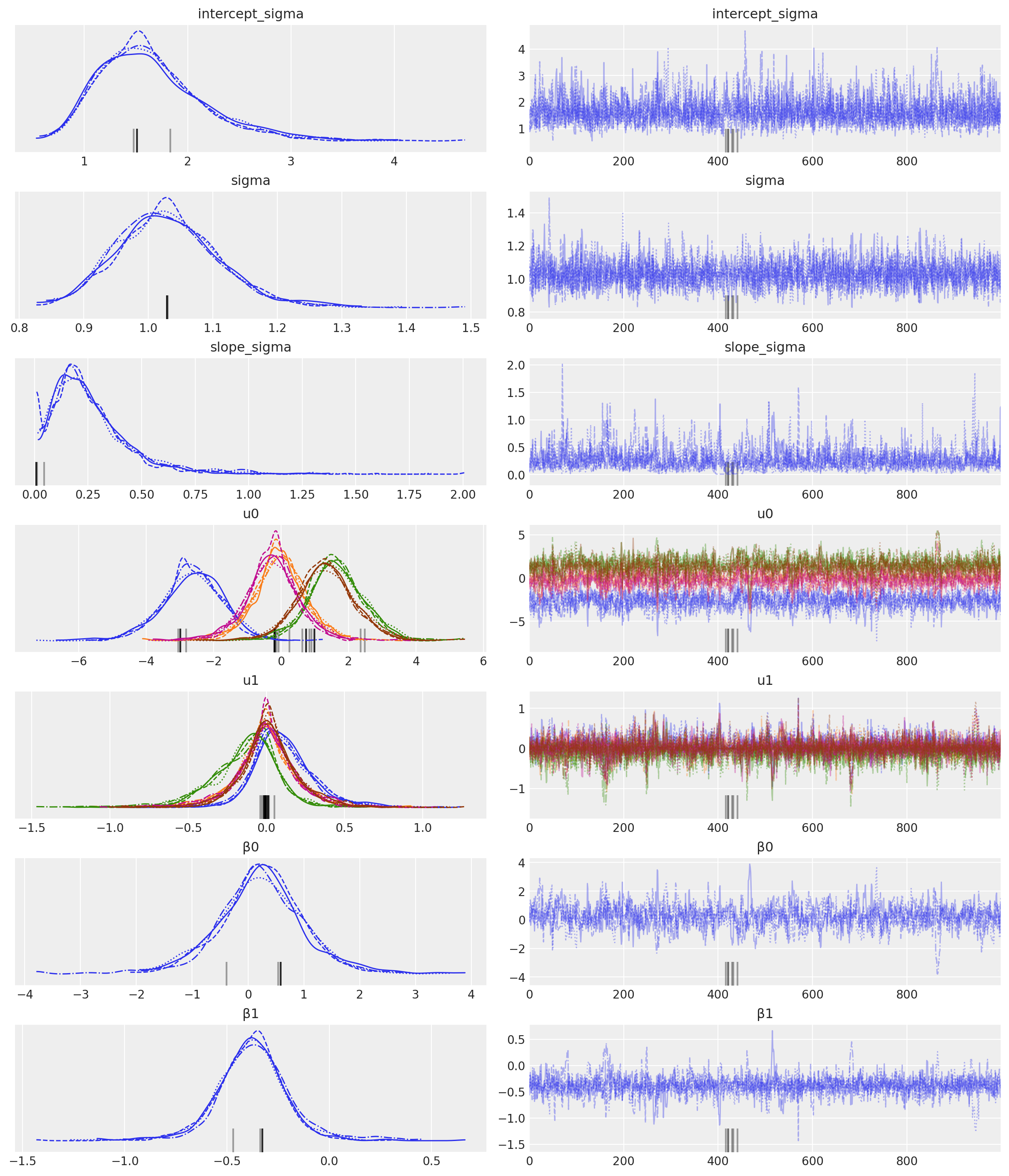
可视化#
# Generate values of xi and g for posterior prediction
n_points = 10
n_groups = len(data.group.unique())
# Generate xi values for each group and concatenate them
xi = np.concatenate(
[
np.linspace(group[1].x.min(), group[1].x.max(), n_points)
for group in data.groupby("group_idx")
]
)
# Generate the group indices array g and cast it to integers
g = np.concatenate([[i] * n_points for i in range(n_groups)]).astype(int)
predict_at = {"x": xi, "g": g}
idata3 = predict(
model=model3,
idata=idata3,
predict_at=predict_at,
)
Show code cell output
Sampling: [y]
Show code cell source
def plot(idata):
fig, ax = plt.subplots(1, 3, figsize=(12, 4))
for i in range(len(group_list)):
# conditional mean plot ---------------------------------------------
ax[0].scatter(data.x[data.group_idx == i], data.y[data.group_idx == i], color=f"C{i}")
plot_band(
xi[g == i],
idata.posterior_predictive.μ.isel(obs_id=(g == i)),
ax=ax[0],
color=f"C{i}",
)
# posterior prediction ----------------------------------------------
ax[1].scatter(data.x[data.group_idx == i], data.y[data.group_idx == i], color=f"C{i}")
plot_band(
xi[g == i],
idata.posterior_predictive.y.isel(obs_id=(g == i)),
ax=ax[1],
color=f"C{i}",
)
# formatting
ax[0].set(xlabel="x", ylabel="y", title="Conditional mean")
ax[1].set(xlabel="x", ylabel="y", title="Posterior predictive distribution")
# parameter space ---------------------------------------------------
for i, _ in enumerate(group_list):
ax[2].scatter(
az.extract(idata, var_names="β1") + az.extract(idata, var_names="u1")[i, :],
az.extract(idata, var_names="β0") + az.extract(idata, var_names="u0")[i, :],
color=f"C{i}",
alpha=0.01,
rasterized=True,
zorder=2,
)
ax[2].set(xlabel="slope", ylabel="intercept", title="Parameter space")
ax[2].axhline(y=0, c="k")
ax[2].axvline(x=0, c="k")
return ax
ax = plot(idata3)
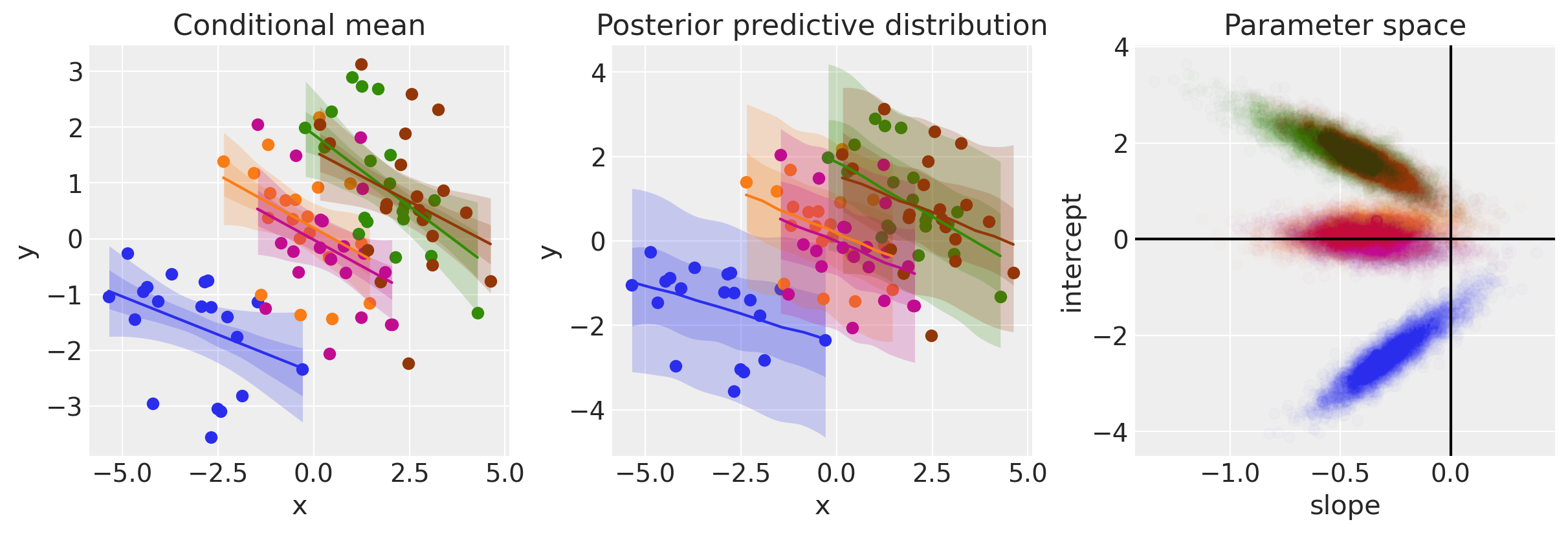
右侧的面板显示了斜率和截距参数的组级别后验分布,以等高线图的形式呈现。我们也可以在下方绘制边缘分布图,以了解我们对斜率小于零的信念程度。
Show code cell source
ax = az.plot_forest(idata2.posterior["β1"], combined=True, figsize=figsize)[0]
ax.set(title="Model 3 suggests negative slopes for each group", xlabel=r"$\beta_1$", ylabel="Group");
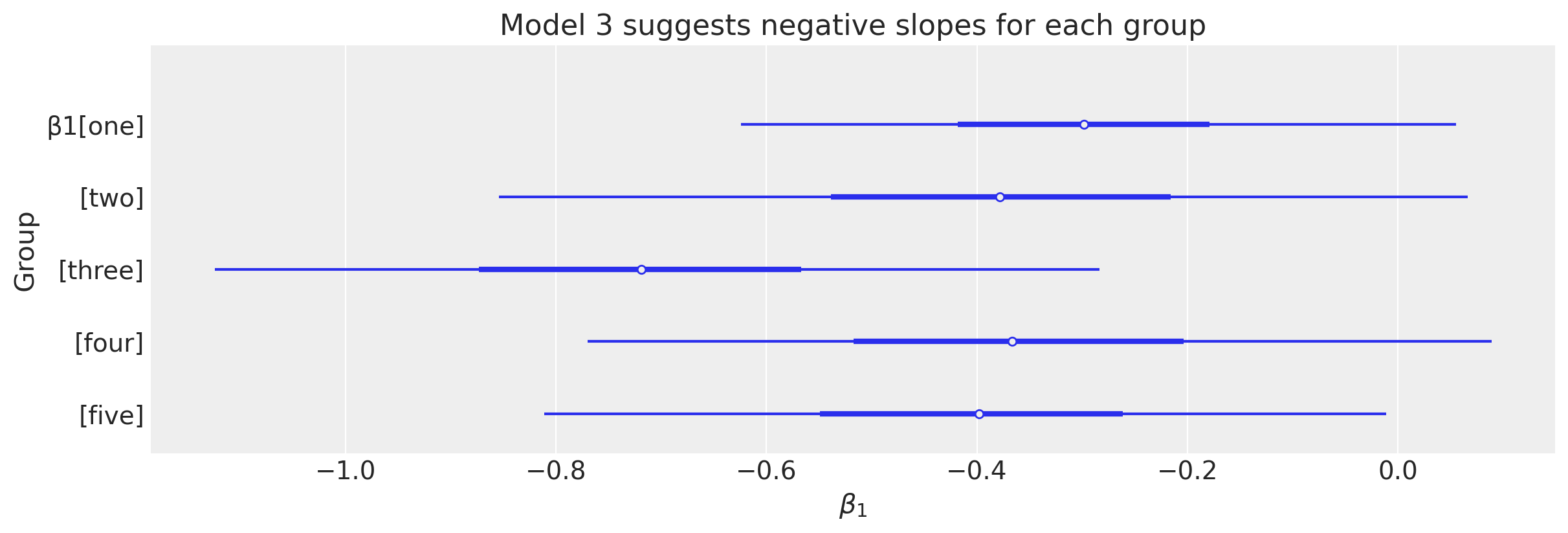
概述#
使用辛普森悖论,我们探讨了3种不同的模型。第一个是简单的线性回归,它将所有数据视为来自一个组。这相当于一个因果DAG,断言\(x\)因果影响\(y\),而\(\text{group}\)被忽略了(即假设与\(x\)或\(y\)因果无关)。我们看到这导致我们相信回归斜率是正的。
虽然这并不一定错,但当我们看到组内数据的回归斜率为负时,这就显得矛盾了。
这个悖论通过更新我们的因果DAG以包含组变量来解决。这就是我们在第二个和第三个模型中所做的。模型2是一个非池化模型,我们基本上为每个组拟合了单独的回归。
模型3假设了相同的因果DAG,但增加了对这些群体是从总体中抽样的认识。这不仅增加了对群体层面回归参数进行推断的能力,还增加了对总体层面进行推断的能力。
水印#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor,xarray
Last updated: Sun Sep 22 2024
Python implementation: CPython
Python version : 3.12.6
IPython version : 8.27.0
pytensor: 2.25.4
xarray : 2024.9.0
matplotlib: 3.9.2
arviz : 0.19.0
pymc : 5.16.2
numpy : 1.26.4
xarray : 2024.9.0
graphviz : 0.20.3
pandas : 2.2.3
seaborn : 0.13.2
Watermark: 2.5.0