Note
Go to the end to download the full example code. or to run this example in your browser via Binder
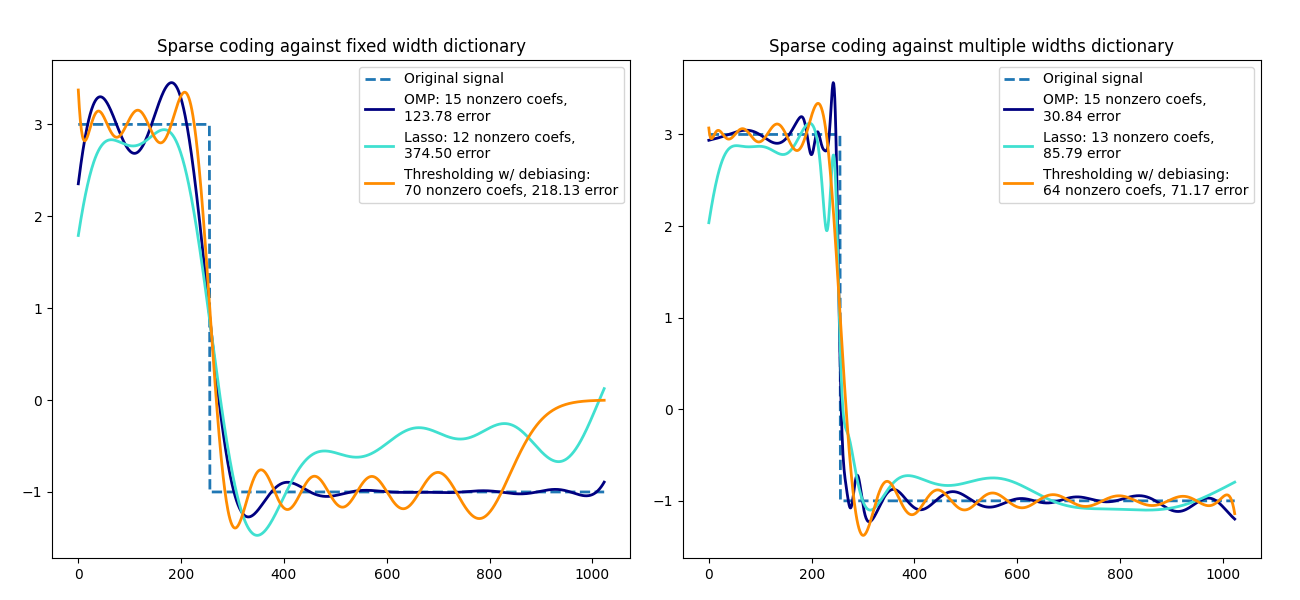
使用预先计算的字典进行稀疏编码#
将信号转换为Ricker小波的稀疏组合。此示例使用
SparseCoder 估计器直观地比较了不同的稀疏编码方法。Ricker(也称为墨西哥帽或高斯的二阶导数)并不是表示这种分段常数信号的特别好的核。因此,可以看到添加不同宽度的原子有多重要,因此激励学习字典以最好地适应您的信号类型。
右侧的更丰富字典在大小上并不大,通过更重的子采样来保持在同一数量级。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import SparseCoder
def ricker_function(resolution, center, width):
"""离散子采样Ricker(墨西哥帽)小波"""
x = np.linspace(0, resolution - 1, resolution)
x = (
(2 / (np.sqrt(3 * width) * np.pi**0.25))
* (1 - (x - center) ** 2 / width**2)
* np.exp(-((x - center) ** 2) / (2 * width**2))
)
return x
def ricker_matrix(width, resolution, n_components):
"""里克(墨西哥帽)小波字典"""
centers = np.linspace(0, resolution - 1, n_components)
D = np.empty((n_components, resolution))
for i, center in enumerate(centers):
D[i] = ricker_function(resolution, center, width)
D /= np.sqrt(np.sum(D**2, axis=1))[:, np.newaxis]
return D
resolution = 1024
subsampling = 3 # subsampling factor
width = 100
n_components = resolution // subsampling
# 计算小波字典
D_fixed = ricker_matrix(width=width, resolution=resolution, n_components=n_components)
D_multi = np.r_[
tuple(
ricker_matrix(width=w, resolution=resolution, n_components=n_components // 5)
for w in (10, 50, 100, 500, 1000)
)
]
# 生成信号
y = np.linspace(0, resolution - 1, resolution)
first_quarter = y < resolution / 4
y[first_quarter] = 3.0
y[np.logical_not(first_quarter)] = -1.0
# 列出以下格式的不同稀疏编码方法:
# (标题, 变换算法, 变换alpha值, 变换非零系数数量, 颜色)
estimators = [
("OMP", "omp", None, 15, "navy"),
("Lasso", "lasso_lars", 2, None, "turquoise"),
]
lw = 2
plt.figure(figsize=(13, 6))
for subplot, (D, title) in enumerate(
zip((D_fixed, D_multi), ("fixed width", "multiple widths"))
):
plt.subplot(1, 2, subplot + 1)
plt.title("Sparse coding against %s dictionary" % title)
plt.plot(y, lw=lw, linestyle="--", label="Original signal")
# 做一个小波近似
for title, algo, alpha, n_nonzero, color in estimators:
coder = SparseCoder(
dictionary=D,
transform_n_nonzero_coefs=n_nonzero,
transform_alpha=alpha,
transform_algorithm=algo,
)
x = coder.transform(y.reshape(1, -1))
density = len(np.flatnonzero(x))
x = np.ravel(np.dot(x, D))
squared_error = np.sum((y - x) ** 2)
plt.plot(
x,
color=color,
lw=lw,
label="%s: %s nonzero coefs,\n%.2f error" % (title, density, squared_error),
)
# 软阈值去偏
coder = SparseCoder(
dictionary=D, transform_algorithm="threshold", transform_alpha=20
)
x = coder.transform(y.reshape(1, -1))
_, idx = np.where(x != 0)
x[0, idx], _, _, _ = np.linalg.lstsq(D[idx, :].T, y, rcond=None)
x = np.ravel(np.dot(x, D))
squared_error = np.sum((y - x) ** 2)
plt.plot(
x,
color="darkorange",
lw=lw,
label="Thresholding w/ debiasing:\n%d nonzero coefs, %.2f error"
% (len(idx), squared_error),
)
plt.axis("tight")
plt.legend(shadow=False, loc="best")
plt.subplots_adjust(0.04, 0.07, 0.97, 0.90, 0.09, 0.2)
plt.show()
Total running time of the script: (0 minutes 0.128 seconds)
Related examples