Note
Go to the end to download the full example code. or to run this example in your browser via Binder
具有多重共线性或相关特征的排列重要性#
在这个示例中,我们计算了特征对训练好的
RandomForestClassifier 的
permutation_importance ,使用的是
Breast cancer wisconsin (diagnostic) dataset 。该模型在测试数据集上可以轻松获得约97%的准确率。由于该数据集包含多重共线性特征,排列重要性显示没有一个特征是重要的,这与高测试准确率相矛盾。
我们演示了一种可能的处理多重共线性的方法,包括对特征的Spearman等级相关性进行层次聚类,选择一个阈值,并从每个聚类中保留一个特征。
Note
随机森林在乳腺癌数据上的特征重要性#
首先,我们定义一个函数来简化绘图:
from sklearn.inspection import permutation_importance
def plot_permutation_importance(clf, X, y, ax):
result = permutation_importance(clf, X, y, n_repeats=10, random_state=42, n_jobs=2)
perm_sorted_idx = result.importances_mean.argsort()
ax.boxplot(
result.importances[perm_sorted_idx].T,
vert=False,
labels=X.columns[perm_sorted_idx],
)
ax.axvline(x=0, color="k", linestyle="--")
return ax
我们接着在 Breast cancer wisconsin (diagnostic) dataset 上训练一个 RandomForestClassifier ,并在测试集上评估其准确性:
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
X, y = load_breast_cancer(return_X_y=True, as_frame=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
print(f"Baseline accuracy on test data: {clf.score(X_test, y_test):.2}")
Baseline accuracy on test data: 0.97
接下来,我们绘制基于树的特征重要性和置换重要性。置换重要性是在训练集上计算的,以显示模型在训练过程中对每个特征的依赖程度。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
mdi_importances = pd.Series(clf.feature_importances_, index=X_train.columns)
tree_importance_sorted_idx = np.argsort(clf.feature_importances_)
tree_indices = np.arange(0, len(clf.feature_importances_)) + 0.5
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 8))
mdi_importances.sort_values().plot.barh(ax=ax1)
ax1.set_xlabel("Gini importance")
plot_permutation_importance(clf, X_train, y_train, ax2)
ax2.set_xlabel("Decrease in accuracy score")
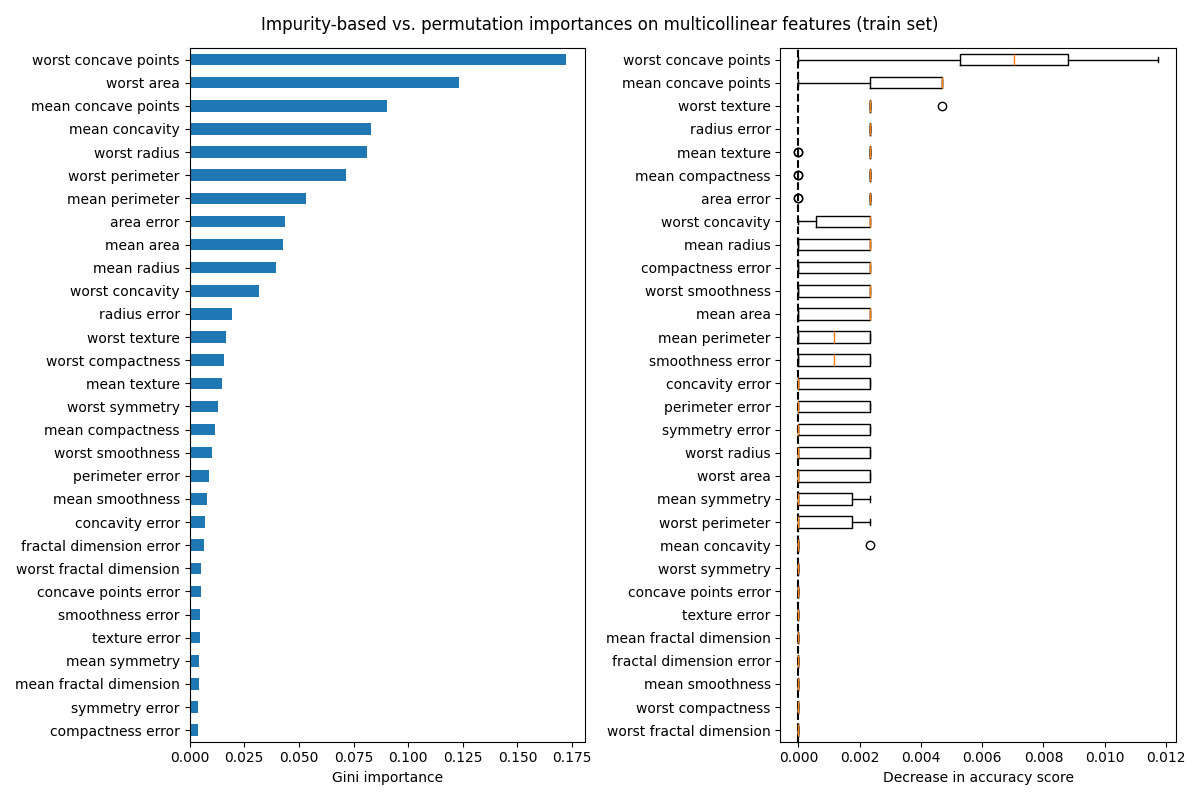
fig.suptitle(
"Impurity-based vs. permutation importances on multicollinear features (train set)"
)
_ = fig.tight_layout()
/app/scikit-learn-main-origin/examples/inspection/plot_permutation_importance_multicollinear.py:31: MatplotlibDeprecationWarning:
The 'labels' parameter of boxplot() has been renamed 'tick_labels' since Matplotlib 3.9; support for the old name will be dropped in 3.11.
左侧的图显示了模型的Gini重要性。由于scikit-learn实现的:class:~sklearn.ensemble.RandomForestClassifier 在每次分裂时使用了:math:sqrt{n_text{features}} 特征的随机子集,它能够稀释任何单个相关特征的主导地位。因此,单个特征的重要性可能在相关特征之间分布得更均匀。由于这些特征具有较大的基数且分类器不过拟合,我们可以相对信任这些值。
右侧图表中的排列重要性显示,排列一个特征最多会使准确率下降 0.012 ,这表明没有一个特征是重要的。这与作为基线计算的高测试准确率相矛盾:某些特征一定是重要的。
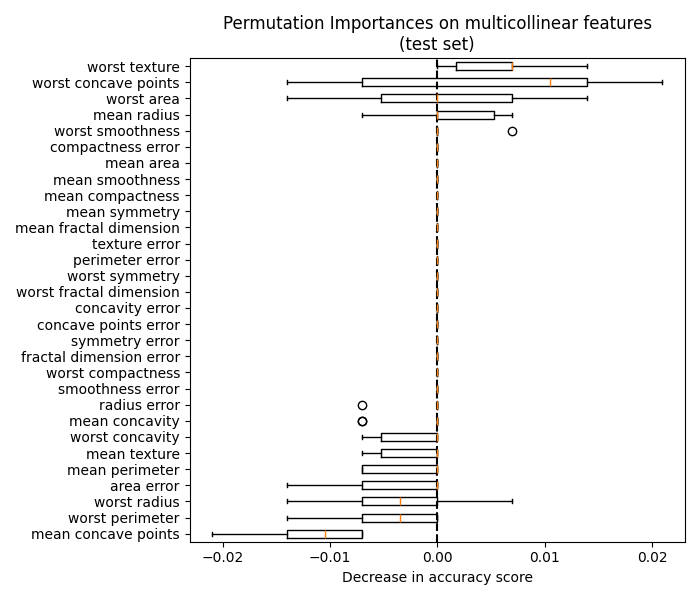
同样,测试集上计算的准确率变化似乎是由偶然因素驱动的:
fig, ax = plt.subplots(figsize=(7, 6))
plot_permutation_importance(clf, X_test, y_test, ax)
ax.set_title("Permutation Importances on multicollinear features\n(test set)")
ax.set_xlabel("Decrease in accuracy score")
_ = ax.figure.tight_layout()
/app/scikit-learn-main-origin/examples/inspection/plot_permutation_importance_multicollinear.py:31: MatplotlibDeprecationWarning:
The 'labels' parameter of boxplot() has been renamed 'tick_labels' since Matplotlib 3.9; support for the old name will be dropped in 3.11.
尽管如此,仍然可以在存在相关特征的情况下计算有意义的排列重要性,如下节所示。
处理多重共线性特征#
当特征存在共线性时,置换一个特征对模型性能的影响很小,因为模型可以从一个相关特征中获取相同的信息。请注意,这并不适用于所有的预测模型,具体情况取决于它们的底层实现。
一种处理多重共线性特征的方法是对斯皮尔曼等级相关系数进行层次聚类,选择一个阈值,并从每个簇中保留一个特征。首先,我们绘制相关特征的热图:
from scipy.cluster import hierarchy
from scipy.spatial.distance import squareform
from scipy.stats import spearmanr
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 8))
corr = spearmanr(X).correlation
# 确保相关矩阵是对称的
corr = (corr + corr.T) / 2
np.fill_diagonal(corr, 1)
# 在使用Ward链接法进行层次聚类之前,我们将相关矩阵转换为距离矩阵。
distance_matrix = 1 - np.abs(corr)
dist_linkage = hierarchy.ward(squareform(distance_matrix))
dendro = hierarchy.dendrogram(
dist_linkage, labels=X.columns.to_list(), ax=ax1, leaf_rotation=90
)
dendro_idx = np.arange(0, len(dendro["ivl"]))
ax2.imshow(corr[dendro["leaves"], :][:, dendro["leaves"]])
ax2.set_xticks(dendro_idx)
ax2.set_yticks(dendro_idx)
ax2.set_xticklabels(dendro["ivl"], rotation="vertical")
ax2.set_yticklabels(dendro["ivl"])
_ = fig.tight_layout()
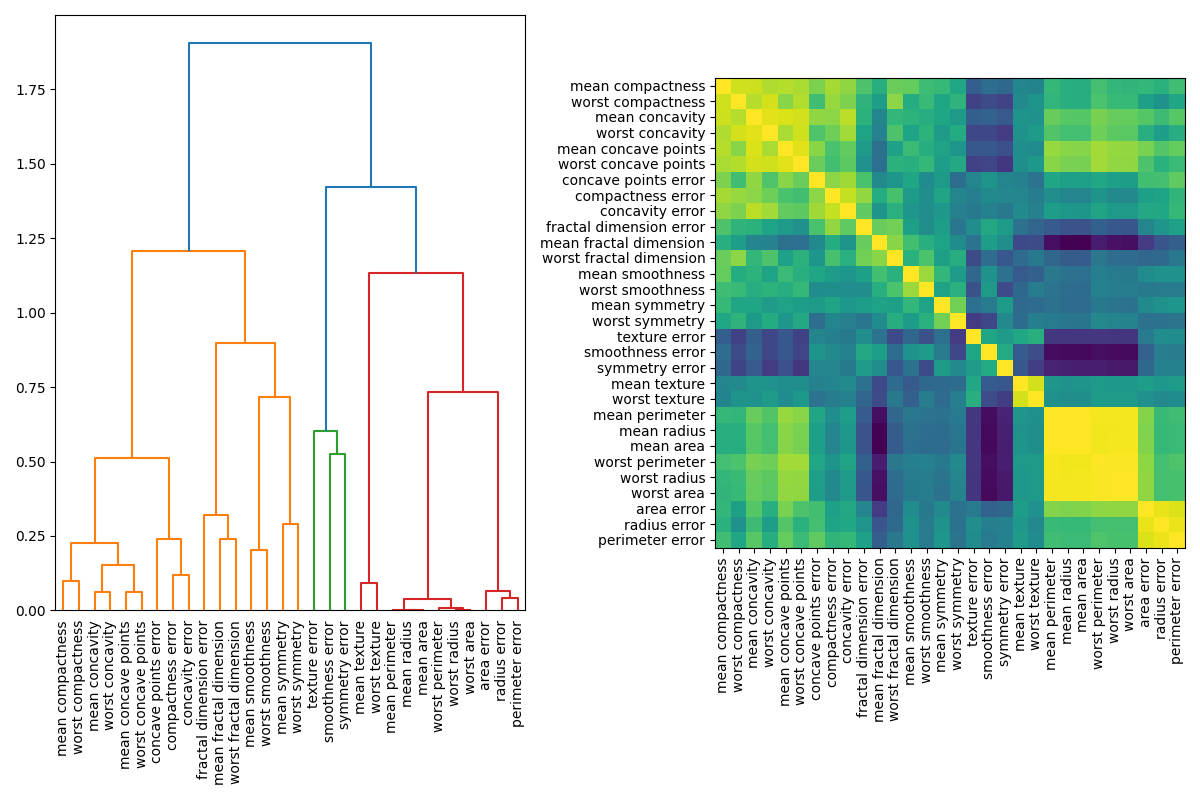
接下来,我们通过目视检查树状图手动选择一个阈值,将特征分组为簇,并从每个簇中选择一个特征保留,从数据集中选择这些特征,并训练一个新的随机森林。与在完整数据集上训练的随机森林相比,新随机森林的测试准确率变化不大。
from collections import defaultdict
cluster_ids = hierarchy.fcluster(dist_linkage, 1, criterion="distance")
cluster_id_to_feature_ids = defaultdict(list)
for idx, cluster_id in enumerate(cluster_ids):
cluster_id_to_feature_ids[cluster_id].append(idx)
selected_features = [v[0] for v in cluster_id_to_feature_ids.values()]
selected_features_names = X.columns[selected_features]
X_train_sel = X_train[selected_features_names]
X_test_sel = X_test[selected_features_names]
clf_sel = RandomForestClassifier(n_estimators=100, random_state=42)
clf_sel.fit(X_train_sel, y_train)
print(
"Baseline accuracy on test data with features removed:"
f" {clf_sel.score(X_test_sel, y_test):.2}"
)
Baseline accuracy on test data with features removed: 0.97
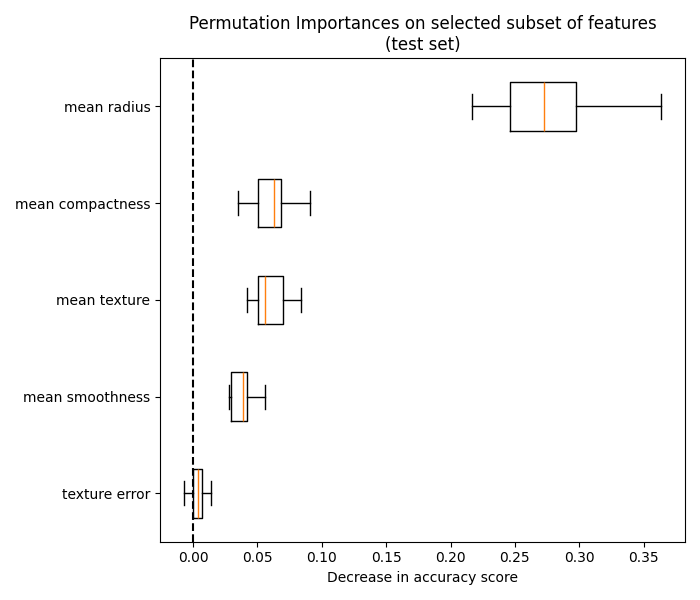
我们终于可以探索所选特征子集的排列重要性了:
fig, ax = plt.subplots(figsize=(7, 6))
plot_permutation_importance(clf_sel, X_test_sel, y_test, ax)
ax.set_title("Permutation Importances on selected subset of features\n(test set)")
ax.set_xlabel("Decrease in accuracy score")
ax.figure.tight_layout()
plt.show()
/app/scikit-learn-main-origin/examples/inspection/plot_permutation_importance_multicollinear.py:31: MatplotlibDeprecationWarning:
The 'labels' parameter of boxplot() has been renamed 'tick_labels' since Matplotlib 3.9; support for the old name will be dropped in 3.11.
Total running time of the script: (0 minutes 2.634 seconds)
Related examples