import numpy as np
import torch
import torch.nn as nn
from typing import Optional
from neuralforecast.common._base_windows import BaseWindows
from neuralforecast.losses.pytorch import DistributionLoss, MQLossDeepAR
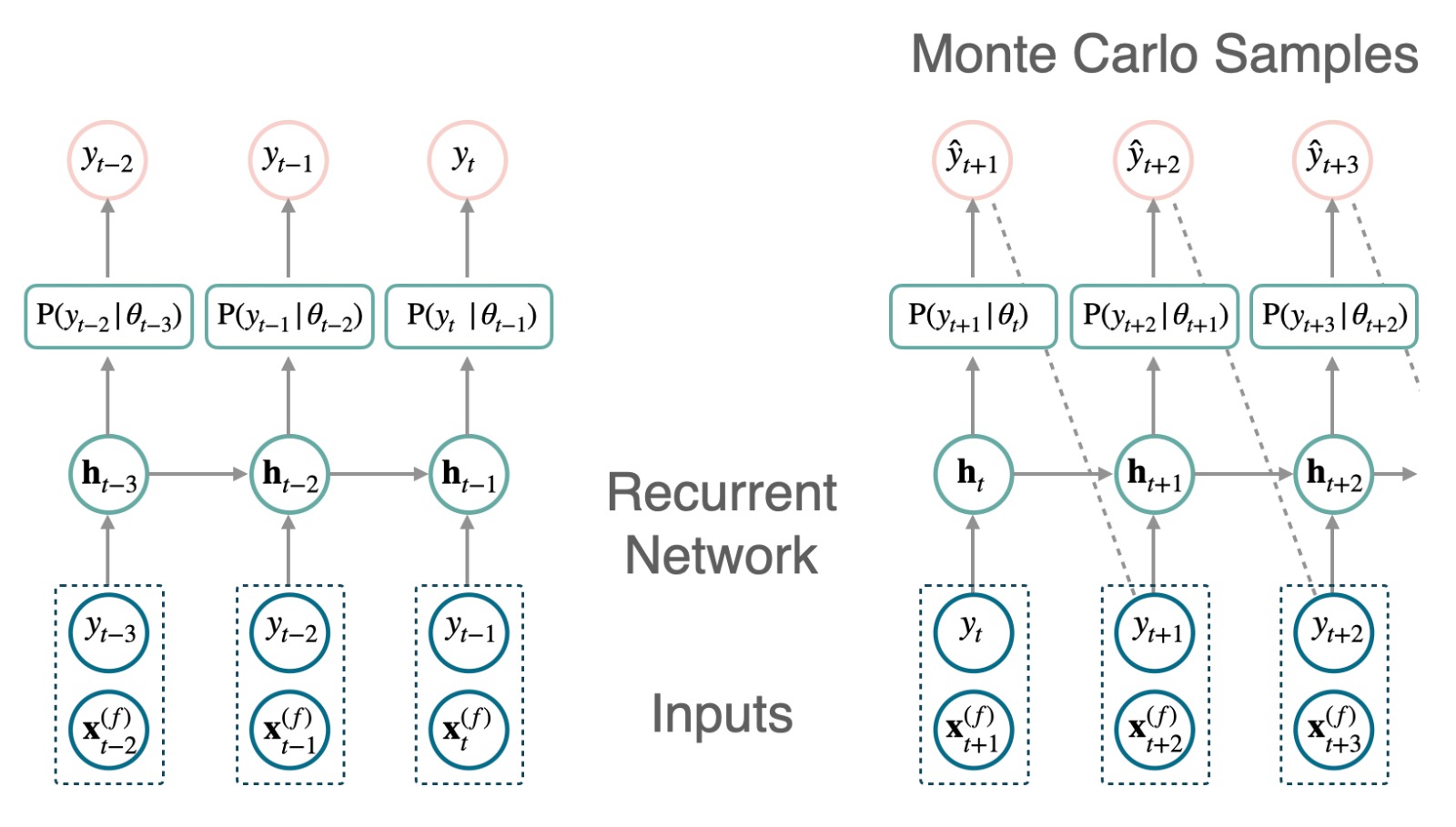
DeepAR模型基于自回归递归神经网络(RNN)在面板数据上通过交叉学习优化生成概率预测。DeepAR利用马尔可夫链蒙特卡洛采样器获得其预测分布,条件概率如下: \[\mathbb{P}(\mathbf{y}_{[t+1:t+H]}|\;\mathbf{y}_{[:t]},\; \mathbf{x}^{(f)}_{[:t+H]},\; \mathbf{x}^{(s)})\]
其中,\(\mathbf{x}^{(s)}\)是静态外生输入,\(\mathbf{x}^{(f)}_{[:t+H]}\)是在预测时间点可用的未来外生输入。 预测是通过将隐状态\(\mathbf{h}_{t}\)转换为预测分布参数\(\theta_{t}\),然后通过蒙特卡洛采样轨迹生成样本\(\mathbf{\hat{y}}_{[t+1:t+H]}\)来获得的。
\[ \begin{align} \mathbf{h}_{t} &= \textrm{RNN}([\mathbf{y}_{t},\mathbf{x}^{(f)}_{t+1},\mathbf{x}^{(s)}], \mathbf{h}_{t-1})\\ \mathbf{\theta}_{t}&=\textrm{Linear}(\mathbf{h}_{t}) \\ \hat{y}_{t+1}&=\textrm{sample}(\;\mathrm{P}(y_{t+1}\;|\;\mathbf{\theta}_{t})\;) \end{align} \]
参考文献
- David Salinas, Valentin Flunkert, Jan Gasthaus, Tim Januschowski (2020). “DeepAR: 使用自回归递归网络进行概率预测”. 国际预测期刊.
- Alexander Alexandrov 等 (2020). “GluonTS: 在Python中进行概率与神经时间序列建模”. 机器学习研究期刊.
外生变量、损失和参数可用性
考虑到推理过程中的采样程序,DeepAR仅支持DistributionLoss作为训练损失。
请注意,DeepAR通过蒙特卡洛生成非参数预测分布。我们在验证过程中也使用这种采样程序,使其更接近推理程序。因此,仅MQLoss可用于验证。
此外,蒙特卡洛意味着历史外生变量对模型不可用。
import logging
import warnings
from fastcore.test import test_eq
from nbdev.showdoc import show_doclogging.getLogger("pytorch_lightning").setLevel(logging.ERROR)
warnings.filterwarnings("ignore")class Decoder(nn.Module):
"""Multi-Layer Perceptron Decoder
**Parameters:**<br>
`in_features`: int, dimension of input.<br>
`out_features`: int, dimension of output.<br>
`hidden_size`: int, dimension of hidden layers.<br>
`num_layers`: int, number of hidden layers.<br>
"""
def __init__(self, in_features, out_features, hidden_size, hidden_layers):
super().__init__()
if hidden_layers == 0:
# 输入层
layers = [nn.Linear(in_features=in_features, out_features=out_features)]
else:
# 输入层
layers = [nn.Linear(in_features=in_features, out_features=hidden_size), nn.ReLU()]
# 隐藏层
for i in range(hidden_layers - 2):
layers += [nn.Linear(in_features=hidden_size, out_features=hidden_size), nn.ReLU()]
# 输出层
layers += [nn.Linear(in_features=hidden_size, out_features=out_features)]
# 按层存储为 ModuleList
self.layers = nn.Sequential(*layers)
def forward(self, x):
return self.layers(x)class DeepAR(BaseWindows):
""" DeepAR
**Parameters:**<br>
`h`: int, Forecast horizon. <br>
`input_size`: int, autorregresive inputs size, y=[1,2,3,4] input_size=2 -> y_[t-2:t]=[1,2].<br>
`lstm_n_layers`: int=2, number of LSTM layers.<br>
`lstm_hidden_size`: int=128, LSTM hidden size.<br>
`lstm_dropout`: float=0.1, LSTM dropout.<br>
`decoder_hidden_layers`: int=0, number of decoder MLP hidden layers. Default: 0 for linear layer. <br>
`decoder_hidden_size`: int=0, decoder MLP hidden size. Default: 0 for linear layer.<br>
`trajectory_samples`: int=100, number of Monte Carlo trajectories during inference.<br>
`stat_exog_list`: str list, static exogenous columns.<br>
`hist_exog_list`: str list, historic exogenous columns.<br>
`futr_exog_list`: str list, future exogenous columns.<br>
`exclude_insample_y`: bool=False, the model skips the autoregressive features y[t-input_size:t] if True.<br>
`loss`: PyTorch module, instantiated train loss class from [losses collection](https://nixtla.github.io/neuralforecast/losses.pytorch.html).<br>
`valid_loss`: PyTorch module=`loss`, instantiated valid loss class from [losses collection](https://nixtla.github.io/neuralforecast/losses.pytorch.html).<br>
`max_steps`: int=1000, maximum number of training steps.<br>
`learning_rate`: float=1e-3, Learning rate between (0, 1).<br>
`num_lr_decays`: int=-1, Number of learning rate decays, evenly distributed across max_steps.<br>
`early_stop_patience_steps`: int=-1, Number of validation iterations before early stopping.<br>
`val_check_steps`: int=100, Number of training steps between every validation loss check.<br>
`batch_size`: int=32, number of different series in each batch.<br>
`valid_batch_size`: int=None, number of different series in each validation and test batch, if None uses batch_size.<br>
`windows_batch_size`: int=1024, number of windows to sample in each training batch, default uses all.<br>
`inference_windows_batch_size`: int=-1, number of windows to sample in each inference batch, -1 uses all.<br>
`start_padding_enabled`: bool=False, if True, the model will pad the time series with zeros at the beginning, by input size.<br>
`step_size`: int=1, step size between each window of temporal data.<br>
`scaler_type`: str='identity', type of scaler for temporal inputs normalization see [temporal scalers](https://nixtla.github.io/neuralforecast/common.scalers.html).<br>
`random_seed`: int, random_seed for pytorch initializer and numpy generators.<br>
`num_workers_loader`: int=os.cpu_count(), workers to be used by `TimeSeriesDataLoader`.<br>
`drop_last_loader`: bool=False, if True `TimeSeriesDataLoader` drops last non-full batch.<br>
`alias`: str, optional, Custom name of the model.<br>
`optimizer`: Subclass of 'torch.optim.Optimizer', optional, user specified optimizer instead of the default choice (Adam).<br>
`optimizer_kwargs`: dict, optional, list of parameters used by the user specified `optimizer`.<br>
`lr_scheduler`: Subclass of 'torch.optim.lr_scheduler.LRScheduler', optional, user specified lr_scheduler instead of the default choice (StepLR).<br>
`lr_scheduler_kwargs`: dict, optional, list of parameters used by the user specified `lr_scheduler`.<br>
`**trainer_kwargs`: int, keyword trainer arguments inherited from [PyTorch Lighning's trainer](https://pytorch-lightning.readthedocs.io/en/stable/api/pytorch_lightning.trainer.trainer.Trainer.html?highlight=trainer).<br>
**References**<br>
- [David Salinas, Valentin Flunkert, Jan Gasthaus, Tim Januschowski (2020). "DeepAR: Probabilistic forecasting with autoregressive recurrent networks". International Journal of Forecasting.](https://www.sciencedirect.com/science/article/pii/S0169207019301888)<br>
- [Alexander Alexandrov et. al (2020). "GluonTS: Probabilistic and Neural Time Series Modeling in Python". Journal of Machine Learning Research.](https://www.jmlr.org/papers/v21/19-820.html)<br>
"""
# Class attributes
SAMPLING_TYPE = 'windows'
EXOGENOUS_FUTR = True
EXOGENOUS_HIST = False
EXOGENOUS_STAT = True
def __init__(self,
h,
input_size: int = -1,
lstm_n_layers: int = 2,
lstm_hidden_size: int = 128,
lstm_dropout: float = 0.1,
decoder_hidden_layers: int = 0,
decoder_hidden_size: int = 0,
trajectory_samples: int = 100,
futr_exog_list = None,
hist_exog_list = None,
stat_exog_list = None,
exclude_insample_y = False,
loss = DistributionLoss(distribution='StudentT', level=[80, 90], return_params=False),
valid_loss = MQLoss(level=[80, 90]),
max_steps: int = 1000,
learning_rate: float = 1e-3,
num_lr_decays: int = 3,
early_stop_patience_steps: int =-1,
val_check_steps: int = 100,
batch_size: int = 32,
valid_batch_size: Optional[int] = None,
windows_batch_size: int = 1024,
inference_windows_batch_size: int = -1,
start_padding_enabled = False,
step_size: int = 1,
scaler_type: str = 'identity',
random_seed: int = 1,
num_workers_loader = 0,
drop_last_loader = False,
optimizer = None,
optimizer_kwargs = None,
lr_scheduler = None,
lr_scheduler_kwargs = None,
**trainer_kwargs):
if exclude_insample_y:
raise Exception('DeepAR has no possibility for excluding y.')
if not loss.is_distribution_output:
raise Exception('DeepAR only supports distributional outputs.')
if str(type(valid_loss)) not in ["<class 'neuralforecast.losses.pytorch.MQLoss'>"]:
raise Exception('DeepAR only supports MQLoss as validation loss.')
if loss.return_params:
raise Exception('DeepAR does not return distribution parameters due to Monte Carlo sampling.')
# Inherit BaseWindows class
super(DeepAR, self).__init__(h=h,
input_size=input_size,
futr_exog_list=futr_exog_list,
hist_exog_list=hist_exog_list,
stat_exog_list=stat_exog_list,
exclude_insample_y = exclude_insample_y,
loss=loss,
valid_loss=valid_loss,
max_steps=max_steps,
learning_rate=learning_rate,
num_lr_decays=num_lr_decays,
early_stop_patience_steps=early_stop_patience_steps,
val_check_steps=val_check_steps,
batch_size=batch_size,
windows_batch_size=windows_batch_size,
valid_batch_size=valid_batch_size,
inference_windows_batch_size=inference_windows_batch_size,
start_padding_enabled=start_padding_enabled,
step_size=step_size,
scaler_type=scaler_type,
num_workers_loader=num_workers_loader,
drop_last_loader=drop_last_loader,
random_seed=random_seed,
optimizer=optimizer,
optimizer_kwargs=optimizer_kwargs,
lr_scheduler=lr_scheduler,
lr_scheduler_kwargs=lr_scheduler_kwargs,
**trainer_kwargs)
self.horizon_backup = self.h # Used because h=0 during training
self.trajectory_samples = trajectory_samples
# LSTM
self.encoder_n_layers = lstm_n_layers
self.encoder_hidden_size = lstm_hidden_size
self.encoder_dropout = lstm_dropout
# LSTM input size (1 for target variable y)
input_encoder = 1 + self.futr_exog_size + self.stat_exog_size
# Instantiate model
self.hist_encoder = nn.LSTM(input_size=input_encoder,
hidden_size=self.encoder_hidden_size,
num_layers=self.encoder_n_layers,
dropout=self.encoder_dropout,
batch_first=True)
# Decoder MLP
self.decoder = Decoder(in_features=lstm_hidden_size,
out_features=self.loss.outputsize_multiplier,
hidden_size=decoder_hidden_size,
hidden_layers=decoder_hidden_layers)
# Override BaseWindows method
def training_step(self, batch, batch_idx):
# During training h=0
self.h = 0
y_idx = batch['y_idx']
# Create and normalize windows [Ws, L, C]
windows = self._create_windows(batch, step='train')
original_insample_y = windows['temporal'][:, :, y_idx].clone() # windows: [B, L, Feature] -> [B, L]
original_insample_y = original_insample_y[:,1:] # Remove first (shift in DeepAr, cell at t outputs t+1)
windows = self._normalization(windows=windows, y_idx=y_idx)
# 解析窗口
insample_y, insample_mask, _, _, _, futr_exog, stat_exog = self._parse_windows(batch, windows)
windows_batch = dict(insample_y=insample_y, # [Ws, L]
insample_mask=insample_mask, # [Ws, L]
futr_exog=futr_exog, # [Ws, L+H]
hist_exog=None, # None
stat_exog=stat_exog,
y_idx=y_idx) # [Ws, 1]
# 模型预测
output = self.train_forward(windows_batch)
if self.loss.is_distribution_output:
_, y_loc, y_scale = self._inv_normalization(y_hat=original_insample_y,
temporal_cols=batch['temporal_cols'],
y_idx=y_idx)
outsample_y = original_insample_y
distr_args = self.loss.scale_decouple(output=output, loc=y_loc, scale=y_scale)
mask = insample_mask[:,1:].clone() # Remove first (shift in DeepAr, cell at t outputs t+1)
loss = self.loss(y=outsample_y, distr_args=distr_args, mask=mask)
else:
raise Exception('DeepAR only supports distributional outputs.')
if torch.isnan(loss):
print('Model Parameters', self.hparams)
print('insample_y', torch.isnan(insample_y).sum())
print('outsample_y', torch.isnan(outsample_y).sum())
print('output', torch.isnan(output).sum())
raise Exception('Loss is NaN, training stopped.')
self.log(
'train_loss',
loss.item(),
batch_size=outsample_y.size(0),
prog_bar=True,
on_epoch=True,
)
self.train_trajectories.append((self.global_step, loss.item()))
self.h = self.horizon_backup # Restore horizon
return loss
def validation_step(self, batch, batch_idx):
self.h == self.horizon_backup
if self.val_size == 0:
return np.nan
# 待办事项:计算窗口数量的临时解决方案
windows = self._create_windows(batch, step='val')
n_windows = len(windows['temporal'])
y_idx = batch['y_idx']
# 批处理中的窗口数量
windows_batch_size = self.inference_windows_batch_size
if windows_batch_size < 0:
windows_batch_size = n_windows
n_batches = int(np.ceil(n_windows/windows_batch_size))
valid_losses = []
batch_sizes = []
for i in range(n_batches):
# 创建并标准化窗口 [Ws, L+H, C]
w_idxs = np.arange(i*windows_batch_size,
min((i+1)*windows_batch_size, n_windows))
windows = self._create_windows(batch, step='val', w_idxs=w_idxs)
original_outsample_y = torch.clone(windows['temporal'][:,-self.h:,0])
windows = self._normalization(windows=windows, y_idx=y_idx)
# 解析窗口
insample_y, insample_mask, _, outsample_mask, \
_, futr_exog, stat_exog = self._parse_windows(batch, windows)
windows_batch = dict(insample_y=insample_y,
insample_mask=insample_mask,
futr_exog=futr_exog,
hist_exog=None,
stat_exog=stat_exog,
temporal_cols=batch['temporal_cols'],
y_idx=y_idx)
# 模型预测
output_batch = self(windows_batch)
# 蒙特卡罗方法已经返回了带有均值和分位数的y_hat。
output_batch = output_batch[:,:, 1:] # 去除均值
valid_loss_batch = self.valid_loss(y=original_outsample_y, y_hat=output_batch, mask=outsample_mask)
valid_losses.append(valid_loss_batch)
batch_sizes.append(len(output_batch))
valid_loss = torch.stack(valid_losses)
batch_sizes = torch.tensor(batch_sizes, device=valid_loss.device)
batch_size = torch.sum(batch_sizes)
valid_loss = torch.sum(valid_loss * batch_sizes) / batch_size
if torch.isnan(valid_loss):
raise Exception('Loss is NaN, training stopped.')
self.log(
'valid_loss',
valid_loss.item(),
batch_size=batch_size,
prog_bar=True,
on_epoch=True,
)
self.validation_step_outputs.append(valid_loss)
return valid_loss
def predict_step(self, batch, batch_idx):
self.h == self.horizon_backup
# 待办事项:计算窗口数量的临时解决方案
windows = self._create_windows(batch, step='predict')
n_windows = len(windows['temporal'])
y_idx = batch['y_idx']
# 批处理中的窗口数量
windows_batch_size = self.inference_windows_batch_size
if windows_batch_size < 0:
windows_batch_size = n_windows
n_batches = int(np.ceil(n_windows/windows_batch_size))
y_hats = []
for i in range(n_batches):
# 创建并标准化窗口 [Ws, L+H, C]
w_idxs = np.arange(i*windows_batch_size,
min((i+1)*windows_batch_size, n_windows))
windows = self._create_windows(batch, step='predict', w_idxs=w_idxs)
windows = self._normalization(windows=windows, y_idx=y_idx)
# 解析窗口
insample_y, insample_mask, _, _, _, futr_exog, stat_exog = self._parse_windows(batch, windows)
windows_batch = dict(insample_y=insample_y, # [Ws, L]
insample_mask=insample_mask, # [Ws, L]
futr_exog=futr_exog, # [Ws, L+H]
stat_exog=stat_exog,
temporal_cols=batch['temporal_cols'],
y_idx=y_idx)
# 模型预测
y_hat = self(windows_batch)
# 蒙特卡罗方法已经返回了带有均值和分位数的y_hat。
y_hats.append(y_hat)
y_hat = torch.cat(y_hats, dim=0)
return y_hat
def train_forward(self, windows_batch):
# 解析Windows批处理文件
encoder_input = windows_batch['insample_y'][:,:, None] # <- [B,T,1]
futr_exog = windows_batch['futr_exog']
stat_exog = windows_batch['stat_exog']
#[B, input_size-1, X]
encoder_input = encoder_input[:,:-1,:] # 移除最后一个(在DeepAr中,t时刻的单元输出t+1)
_, input_size = encoder_input.shape[:2]
if self.futr_exog_size > 0:
# 外生未来转移(t 预测 t+1,最后一个输出在样本外)
encoder_input = torch.cat((encoder_input, futr_exog[:,1:,:]), dim=2)
if self.stat_exog_size > 0:
stat_exog = stat_exog.unsqueeze(1).repeat(1, input_size, 1) # [B, S] -> [B, input_size-1, S]
encoder_input = torch.cat((encoder_input, stat_exog), dim=2)
# RNN 前向传播
hidden_state, _ = self.hist_encoder(encoder_input) # [B, 输入尺寸-1, RNN隐藏状态]
# 解码器前向传播
output = self.decoder(hidden_state) # [B, 输入尺寸-1, 输出尺寸]
output = self.loss.domain_map(output)
return output
def forward(self, windows_batch):
# 解析Windows批处理文件
encoder_input = windows_batch['insample_y'][:,:, None] # <- [B,L,1]
futr_exog = windows_batch['futr_exog'] # <- [B,L+H, n_f]
stat_exog = windows_batch['stat_exog']
y_idx = windows_batch['y_idx']
#[B, seq_len, X]
batch_size, input_size = encoder_input.shape[:2]
if self.futr_exog_size > 0:
futr_exog_input_window = futr_exog[:,1:input_size+1,:] # 将 y_t 与 futr_exog_t+1 对齐
encoder_input = torch.cat((encoder_input, futr_exog_input_window), dim=2)
if self.stat_exog_size > 0:
stat_exog_input_window = stat_exog.unsqueeze(1).repeat(1, input_size, 1) # [B, S] -> [B, input_size, S]
encoder_input = torch.cat((encoder_input, stat_exog_input_window), dim=2)
# 利用输入大小为 `input_size` 的历史数据来预测预测窗口的前 `h` 个值。
_, h_c_tuple = self.hist_encoder(encoder_input)
h_n = h_c_tuple[0] # [层数, 批次大小, LSTM隐藏状态]
c_n = h_c_tuple[1] # [层数, 批次大小, LSTM隐藏状态]
# 在批处理维度上向量化轨迹样本 [1]
h_n = torch.repeat_interleave(h_n, self.trajectory_samples, 1) # [层数, B*轨迹样本数, RNN隐藏状态]
c_n = torch.repeat_interleave(c_n, self.trajectory_samples, 1) # [层数, B*轨迹样本数, RNN隐藏状态]
# 逆归一化尺度
y_scale = self.scaler.x_scale[:, 0, [y_idx]].squeeze(-1).to(encoder_input.device)
y_loc = self.scaler.x_shift[:, 0, [y_idx]].squeeze(-1).to(encoder_input.device)
y_scale = torch.repeat_interleave(y_scale, self.trajectory_samples, 0)
y_loc = torch.repeat_interleave(y_loc, self.trajectory_samples, 0)
# 递归策略预测
quantiles = self.loss.quantiles.to(encoder_input.device)
y_hat = torch.zeros(batch_size, self.h, len(quantiles)+1, device=encoder_input.device)
for tau in range(self.h):
# 解码器前向传播
last_layer_h = h_n[-1] # [B*轨迹样本, LSTM隐藏状态]
output = self.decoder(last_layer_h)
output = self.loss.domain_map(output)
# 反归一化
distr_args = self.loss.scale_decouple(output=output, loc=y_loc, scale=y_scale)
# 添加水平(1)维度
distr_args = list(distr_args)
for i in range(len(distr_args)):
distr_args[i] = distr_args[i].unsqueeze(-1)
distr_args = tuple(distr_args)
samples_tau, _, _ = self.loss.sample(distr_args=distr_args, num_samples=1)
samples_tau = samples_tau.reshape(batch_size, self.trajectory_samples)
sample_mean = torch.mean(samples_tau, dim=-1).to(encoder_input.device)
quants = torch.quantile(input=samples_tau,
q=quantiles, dim=-1).to(encoder_input.device)
y_hat[:,tau,0] = sample_mean
y_hat[:,tau,1:] = quants.permute((1,0)) # [Q, B] -> [B, Q]
# 如果已经在最后一步(无需预测下一步),则停止。
if tau+1 == self.h:
continue
# 标准化以用作输入
encoder_input = self.scaler.scaler(samples_tau.flatten(), y_loc, y_scale) # [B*n_样本]
encoder_input = encoder_input[:, None, None] # [B*n_样本, 1, 1]
# 更新输入
if self.futr_exog_size > 0:
futr_exog_tau = futr_exog[:,[input_size+tau+1],:] # [B, 1, n_f]
futr_exog_tau = torch.repeat_interleave(futr_exog_tau, self.trajectory_samples, 0) # [B*n_样本, 1, n_特征]
encoder_input = torch.cat((encoder_input, futr_exog_tau), dim=2) # [B*n_samples, 1, 1+n_f]
if self.stat_exog_size > 0:
stat_exog_tau = torch.repeat_interleave(stat_exog, self.trajectory_samples, 0) # [B*n_样本, n_s]
encoder_input = torch.cat((encoder_input, stat_exog_tau[:,None,:]), dim=2) # [B*n_samples, 1, 1+n_f+n_s]
_, h_c_tuple = self.hist_encoder(encoder_input, (h_n, c_n))
h_n = h_c_tuple[0] # [层数, 批次大小, RNN隐藏状态]
c_n = h_c_tuple[1] # [层数, 批次大小, RNN隐藏状态]
return y_hatshow_doc(DeepAR, title_level=3)show_doc(DeepAR.fit, name='DeepAR.fit', title_level=3)show_doc(DeepAR.predict, name='DeepAR.predict', title_level=3)使用示例
import pandas as pd
import matplotlib.pyplot as plt
from neuralforecast import NeuralForecast
from neuralforecast.models import DeepAR
from neuralforecast.losses.pytorch import DistributionLoss
from neuralforecast.utils import AirPassengersPanel, AirPassengersStatic
Y_train_df = AirPassengersPanel[AirPassengersPanel.ds<AirPassengersPanel['ds'].values[-12]] # 132次列车
Y_test_df = AirPassengersPanel[AirPassengersPanel.ds>=AirPassengersPanel['ds'].values[-12]].reset_index(drop=True) # 12项测试
nf = NeuralForecast(
models=[DeepAR(h=12,
input_size=48,
lstm_n_layers=3,
trajectory_samples=100,
loss=DistributionLoss(distribution='Normal', level=[80, 90], return_params=False),
learning_rate=0.005,
stat_exog_list=['airline1'],
futr_exog_list=['trend'],
max_steps=100,
val_check_steps=10,
early_stop_patience_steps=-1,
scaler_type='standard',
enable_progress_bar=True),
],
freq='M'
)
nf.fit(df=Y_train_df, static_df=AirPassengersStatic, val_size=12)
Y_hat_df = nf.predict(futr_df=Y_test_df)
# 绘制分位数预测图
Y_hat_df = Y_hat_df.reset_index(drop=False).drop(columns=['unique_id','ds'])
plot_df = pd.concat([Y_test_df, Y_hat_df], axis=1)
plot_df = pd.concat([Y_train_df, plot_df])
plot_df = plot_df[plot_df.unique_id=='Airline1'].drop('unique_id', axis=1)
plt.plot(plot_df['ds'], plot_df['y'], c='black', label='True')
plt.plot(plot_df['ds'], plot_df['DeepAR-median'], c='blue', label='median')
plt.fill_between(x=plot_df['ds'][-12:],
y1=plot_df['DeepAR-lo-90'][-12:].values,
y2=plot_df['DeepAR-hi-90'][-12:].values,
alpha=0.4, label='level 90')
plt.legend()
plt.grid()
plt.plot()Give us a ⭐ on Github