import math
import numpy as np
from typing import Optional #, 任意, 元组
import torch
import torch.nn as nn
import torch.nn.functional as F
from neuralforecast.common._base_windows import BaseWindows
from neuralforecast.common._modules import RevIN
from neuralforecast.losses.pytorch import MAEPatchTST
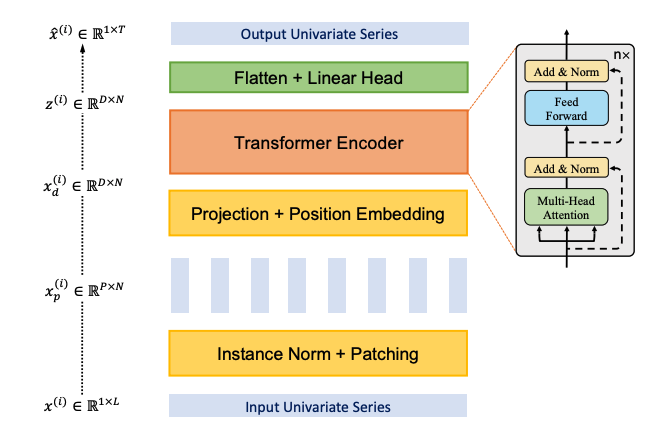
PatchTST模型是一种基于变压器(Transformer)的高效多变量时间序列预测模型。
它基于两个关键组件: - 将时间序列分割成窗口(补丁),作为变压器的输入令牌 - 渠道独立性,每个通道包含一个单一的单变量时间序列。
参考文献
- Nie, Y., Nguyen, N. H., Sinthong, P., & Kalagnanam, J. (2022). “一系列时间价值64个词:使用变换器的长期预测”
from fastcore.test import test_eq
from nbdev.showdoc import show_doc1. 骨干
辅助函数
class 转置(nn.Module):
"""
转置
"""
def __init__(self, *dims, contiguous=False):
super().__init__()
self.dims, self.contiguous = dims, contiguous
def forward(self, x):
if self.contiguous: return x.transpose(*self.dims).contiguous()
else: return x.transpose(*self.dims)
def get_activation_fn(activation):
if callable(activation): return activation()
elif activation.lower() == "relu": return nn.ReLU()
elif activation.lower() == "gelu": return nn.GELU()
raise ValueError(f'{activation} is not available. You can use "relu", "gelu", or a callable') 位置编码
def PositionalEncoding(q_len, hidden_size, normalize=True):
pe = torch.zeros(q_len, hidden_size)
position = torch.arange(0, q_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, hidden_size, 2) * -(math.log(10000.0) / hidden_size))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
if normalize:
pe = pe - pe.mean()
pe = pe / (pe.std() * 10)
return pe
SinCosPosEncoding = PositionalEncoding
def Coord2dPosEncoding(q_len, hidden_size, exponential=False, normalize=True, eps=1e-3):
x = .5 if exponential else 1
i = 0
for i in range(100):
cpe = 2 * (torch.linspace(0, 1, q_len).reshape(-1, 1) ** x) * (torch.linspace(0, 1, hidden_size).reshape(1, -1) ** x) - 1
if abs(cpe.mean()) <= eps: break
elif cpe.mean() > eps: x += .001
else: x -= .001
i += 1
if normalize:
cpe = cpe - cpe.mean()
cpe = cpe / (cpe.std() * 10)
return cpe
def Coord1dPosEncoding(q_len, exponential=False, normalize=True):
cpe = (2 * (torch.linspace(0, 1, q_len).reshape(-1, 1)**(.5 if exponential else 1)) - 1)
if normalize:
cpe = cpe - cpe.mean()
cpe = cpe / (cpe.std() * 10)
return cpe
def positional_encoding(pe, learn_pe, q_len, hidden_size):
# 位置编码
if pe == None:
W_pos = torch.empty((q_len, hidden_size)) # pe = None 和 learn_pe = False 可用于衡量 pe 的影响
nn.init.uniform_(W_pos, -0.02, 0.02)
learn_pe = False
elif pe == 'zero':
W_pos = torch.empty((q_len, 1))
nn.init.uniform_(W_pos, -0.02, 0.02)
elif pe == 'zeros':
W_pos = torch.empty((q_len, hidden_size))
nn.init.uniform_(W_pos, -0.02, 0.02)
elif pe == 'normal' or pe == 'gauss':
W_pos = torch.zeros((q_len, 1))
torch.nn.init.normal_(W_pos, mean=0.0, std=0.1)
elif pe == 'uniform':
W_pos = torch.zeros((q_len, 1))
nn.init.uniform_(W_pos, a=0.0, b=0.1)
elif pe == 'lin1d': W_pos = Coord1dPosEncoding(q_len, exponential=False, normalize=True)
elif pe == 'exp1d': W_pos = Coord1dPosEncoding(q_len, exponential=True, normalize=True)
elif pe == 'lin2d': W_pos = Coord2dPosEncoding(q_len, hidden_size, exponential=False, normalize=True)
elif pe == 'exp2d': W_pos = Coord2dPosEncoding(q_len, hidden_size, exponential=True, normalize=True)
elif pe == 'sincos': W_pos = PositionalEncoding(q_len, hidden_size, normalize=True)
else: raise ValueError(f"{pe} is not a valid pe (positional encoder. Available types: 'gauss'=='normal', \
'zeros', 'zero', uniform', 'lin1d', 'exp1d', 'lin2d', 'exp2d', 'sincos', None.)")
return nn.Parameter(W_pos, requires_grad=learn_pe)编码器
class PatchTST_骨干网络(nn.Module):
"""
PatchTST_骨干网络
"""
def __init__(self, c_in:int, c_out:int, input_size:int, h:int, patch_len:int, stride:int, max_seq_len:Optional[int]=1024,
n_layers:int=3, hidden_size=128, n_heads=16, d_k:Optional[int]=None, d_v:Optional[int]=None,
linear_hidden_size:int=256, norm:str='BatchNorm', attn_dropout:float=0., dropout:float=0., act:str="gelu", key_padding_mask:str='auto',
padding_var:Optional[int]=None, attn_mask:Optional[torch.Tensor]=None, res_attention:bool=True, pre_norm:bool=False, store_attn:bool=False,
pe:str='zeros', learn_pe:bool=True, fc_dropout:float=0., head_dropout = 0, padding_patch = None,
pretrain_head:bool=False, head_type = 'flatten', individual = False, revin = True, affine = True, subtract_last = False):
super().__init__()
# 逆向创新
self.revin = revin
if self.revin: self.revin_layer = RevIN(c_in, affine=affine, subtract_last=subtract_last)
# 补丁
self.patch_len = patch_len
self.stride = stride
self.padding_patch = padding_patch
patch_num = int((input_size - patch_len)/stride + 1)
if padding_patch == 'end': # 可以修改为一般情况
self.padding_patch_layer = nn.ReplicationPad1d((0, stride))
patch_num += 1
# 骨干
self.backbone = TSTiEncoder(c_in, patch_num=patch_num, patch_len=patch_len, max_seq_len=max_seq_len,
n_layers=n_layers, hidden_size=hidden_size, n_heads=n_heads, d_k=d_k, d_v=d_v, linear_hidden_size=linear_hidden_size,
attn_dropout=attn_dropout, dropout=dropout, act=act, key_padding_mask=key_padding_mask, padding_var=padding_var,
attn_mask=attn_mask, res_attention=res_attention, pre_norm=pre_norm, store_attn=store_attn,
pe=pe, learn_pe=learn_pe)
# 头
self.head_nf = hidden_size * patch_num
self.n_vars = c_in
self.c_out = c_out
self.pretrain_head = pretrain_head
self.head_type = head_type
self.individual = individual
if self.pretrain_head:
self.head = self.create_pretrain_head(self.head_nf, c_in, fc_dropout) # 自定义头部作为部分函数传递,附带其所有关键字参数
elif head_type == 'flatten':
self.head = 扁头(self.individual, self.n_vars, self.head_nf, h, c_out, head_dropout=head_dropout)
def forward(self, z): # z: [批次大小 x 变量数 x 序列长度]
# 规范
if self.revin:
z = z.permute(0,2,1)
z = self.revin_layer(z, 'norm')
z = z.permute(0,2,1)
# 进行补丁修复
if self.padding_patch == 'end':
z = self.padding_patch_layer(z)
z = z.unfold(dimension=-1, size=self.patch_len, step=self.stride) # z: [批次大小 x 变量数 x 补丁数量 x 补丁长度]
z = z.permute(0,1,3,2) # z: [批次大小 x 变量数 x 补丁长度 x 补丁数量]
# 模型
z = self.backbone(z) # z: [bs x nvars x 隐藏层大小 x 分块数]
z = self.head(z) # z: [bs x nvars x h]
# 去归一化
if self.revin:
z = z.permute(0,2,1)
z = self.revin_layer(z, 'denorm')
z = z.permute(0,2,1)
return z
def create_pretrain_head(self, head_nf, vars, dropout):
return nn.Sequential(nn.Dropout(dropout),
nn.Conv1d(head_nf, vars, 1)
)
class 扁头(nn.Module):
"""
扁头
"""
def __init__(self, individual, n_vars, nf, h, c_out, head_dropout=0):
super().__init__()
self.individual = individual
self.n_vars = n_vars
self.c_out = c_out
if self.individual:
self.linears = nn.ModuleList()
self.dropouts = nn.ModuleList()
self.flattens = nn.ModuleList()
for i in range(self.n_vars):
self.flattens.append(nn.Flatten(start_dim=-2))
self.linears.append(nn.Linear(nf, h*c_out))
self.dropouts.append(nn.Dropout(head_dropout))
else:
self.flatten = nn.Flatten(start_dim=-2)
self.linear = nn.Linear(nf, h*c_out)
self.dropout = nn.Dropout(head_dropout)
def forward(self, x): # x: [批次大小 x 变量数 x 隐藏层大小 x 分块数量]
if self.individual:
x_out = []
for i in range(self.n_vars):
z = self.flattens[i](x[:,i,:,:]) # z: [bs x 隐藏层大小 * 分块数量]
z = self.linears[i](z) # z: [bs x h]
z = self.dropouts[i](z)
x_out.append(z)
x = torch.stack(x_out, dim=1) # x: [批次大小 x 变量数 x 高度]
else:
x = self.flatten(x)
x = self.linear(x)
x = self.dropout(x)
return x
class TSTiEncoder(nn.Module): #i 表示与通道无关
"""
TSTiEncoder
"""
def __init__(self, c_in, patch_num, patch_len, max_seq_len=1024,
n_layers=3, hidden_size=128, n_heads=16, d_k=None, d_v=None,
linear_hidden_size=256, norm='BatchNorm', attn_dropout=0., dropout=0., act="gelu", store_attn=False,
key_padding_mask='auto', padding_var=None, attn_mask=None, res_attention=True, pre_norm=False,
pe='zeros', learn_pe=True):
super().__init__()
self.patch_num = patch_num
self.patch_len = patch_len
# 输入编码
q_len = patch_num
self.W_P = nn.Linear(patch_len, hidden_size) # 等式1:特征向量在d维向量空间上的投影
self.seq_len = q_len
# 位置编码
self.W_pos = positional_encoding(pe, learn_pe, q_len, hidden_size)
# 残差丢弃
self.dropout = nn.Dropout(dropout)
# 编码器
self.encoder = TST编码器(q_len, hidden_size, n_heads, d_k=d_k, d_v=d_v, linear_hidden_size=linear_hidden_size, norm=norm, attn_dropout=attn_dropout, dropout=dropout,
pre_norm=pre_norm, activation=act, res_attention=res_attention, n_layers=n_layers, store_attn=store_attn)
def forward(self, x) -> torch.Tensor: # x: [批次大小 x 变量数 x 补丁长度 x 补丁数量]
n_vars = x.shape[1]
# 输入编码
x = x.permute(0,1,3,2) # x: [批次大小 x 变量数 x 补丁数量 x 补丁长度]
x = self.W_P(x) # x: [批次大小 x 变量数 x 补丁数量 x 隐藏层大小]
u = torch.reshape(x, (x.shape[0]*x.shape[1],x.shape[2],x.shape[3])) # u: [bs * nvars x patch_num x hidden_size]
u = self.dropout(u + self.W_pos) # u: [bs * nvars x patch_num x hidden_size]
# 编码器
z = self.encoder(u) # z: [bs * nvars x patch_num x hidden_size]
z = torch.reshape(z, (-1,n_vars,z.shape[-2],z.shape[-1])) # z: [批次大小 x 变量数 x 补丁数量 x 隐藏层大小]
z = z.permute(0,1,3,2) # z: [bs x nvars x 隐藏层大小 x 分块数]
return z
class TST编码器(nn.Module):
"""
TST编码器
"""
def __init__(self, q_len, hidden_size, n_heads, d_k=None, d_v=None, linear_hidden_size=None,
norm='BatchNorm', attn_dropout=0., dropout=0., activation='gelu',
res_attention=False, n_layers=1, pre_norm=False, store_attn=False):
super().__init__()
self.layers = nn.ModuleList([TST编码器Layer(q_len, hidden_size, n_heads=n_heads, d_k=d_k, d_v=d_v, linear_hidden_size=linear_hidden_size, norm=norm,
attn_dropout=attn_dropout, dropout=dropout,
activation=activation, res_attention=res_attention,
pre_norm=pre_norm, store_attn=store_attn) for i in range(n_layers)])
self.res_attention = res_attention
def forward(self, src:torch.Tensor, key_padding_mask:Optional[torch.Tensor]=None, attn_mask:Optional[torch.Tensor]=None):
output = src
scores = None
if self.res_attention:
for mod in self.layers: output, scores = mod(output, prev=scores, key_padding_mask=key_padding_mask, attn_mask=attn_mask)
return output
else:
for mod in self.layers: output = mod(output, key_padding_mask=key_padding_mask, attn_mask=attn_mask)
return output
class TST编码器Layer(nn.Module):
"""
TST编码器Layer
"""
def __init__(self, q_len, hidden_size, n_heads, d_k=None, d_v=None, linear_hidden_size=256, store_attn=False,
norm='BatchNorm', attn_dropout=0, dropout=0., bias=True, activation="gelu", res_attention=False, pre_norm=False):
super().__init__()
assert not hidden_size%n_heads, f"hidden_size ({hidden_size}) must be divisible by n_heads ({n_heads})"
d_k = hidden_size // n_heads if d_k is None else d_k
d_v = hidden_size // n_heads if d_v is None else d_v
# 多头注意力机制
self.res_attention = res_attention
self.self_attn = 多头注意力机制(hidden_size, n_heads, d_k, d_v, attn_dropout=attn_dropout,
proj_dropout=dropout, res_attention=res_attention)
# 加法与归一化
self.dropout_attn = nn.Dropout(dropout)
if "batch" in norm.lower():
self.norm_attn = nn.Sequential(Transpose(1,2), nn.BatchNorm1d(hidden_size), Transpose(1,2))
else:
self.norm_attn = nn.LayerNorm(hidden_size)
# 逐位置前馈网络
self.ff = nn.Sequential(nn.Linear(hidden_size, linear_hidden_size, bias=bias),
get_activation_fn(activation),
nn.Dropout(dropout),
nn.Linear(linear_hidden_size, hidden_size, bias=bias))
# 加法与归一化
self.dropout_ffn = nn.Dropout(dropout)
if "batch" in norm.lower():
self.norm_ffn = nn.Sequential(Transpose(1,2), nn.BatchNorm1d(hidden_size), Transpose(1,2))
else:
self.norm_ffn = nn.LayerNorm(hidden_size)
self.pre_norm = pre_norm
self.store_attn = store_attn
def forward(self, src:torch.Tensor, prev:Optional[torch.Tensor]=None,
key_padding_mask:Optional[torch.Tensor]=None,
attn_mask:Optional[torch.Tensor]=None): # -> 元组[torch.Tensor, 任意]:
# 多头注意力机制 sublayer
if self.pre_norm:
src = self.norm_attn(src)
# #多头注意力机制
if self.res_attention:
src2, attn, scores = self.self_attn(src, src, src, prev,
key_padding_mask=key_padding_mask, attn_mask=attn_mask)
else:
src2, attn = self.self_attn(src, src, src, key_padding_mask=key_padding_mask, attn_mask=attn_mask)
if self.store_attn:
self.attn = attn
# #添加与归一化
src = src + self.dropout_attn(src2) # 添加:带有残差丢弃的残差连接
if not self.pre_norm:
src = self.norm_attn(src)
# 前馈子层
if self.pre_norm:
src = self.norm_ffn(src)
## 逐位置前馈网络
src2 = self.ff(src)
# #添加与归一化
src = src + self.dropout_ffn(src2) # 添加:带有残差丢弃的残差连接
if not self.pre_norm:
src = self.norm_ffn(src)
if self.res_attention:
return src, scores
else:
return src
class 多头注意力机制(nn.Module):
"""
多头注意力机制
"""
def __init__(self, hidden_size, n_heads, d_k=None, d_v=None,
res_attention=False, attn_dropout=0., proj_dropout=0., qkv_bias=True, lsa=False):
"""
Multi Head Attention Layer
Input shape:
Q: [batch_size (bs) x max_q_len x hidden_size]
K, V: [batch_size (bs) x q_len x hidden_size]
mask: [q_len x q_len]
"""
super().__init__()
d_k = hidden_size // n_heads if d_k is None else d_k
d_v = hidden_size // n_heads if d_v is None else d_v
self.n_heads, self.d_k, self.d_v = n_heads, d_k, d_v
self.W_Q = nn.Linear(hidden_size, d_k * n_heads, bias=qkv_bias)
self.W_K = nn.Linear(hidden_size, d_k * n_heads, bias=qkv_bias)
self.W_V = nn.Linear(hidden_size, d_v * n_heads, bias=qkv_bias)
# 缩放点积注意力(多头)
self.res_attention = res_attention
self.sdp_attn = _ScaledDotProductAttention(hidden_size, n_heads, attn_dropout=attn_dropout,
res_attention=self.res_attention, lsa=lsa)
# 项目产出
self.to_out = nn.Sequential(nn.Linear(n_heads * d_v, hidden_size), nn.Dropout(proj_dropout))
def forward(self, Q:torch.Tensor, K:Optional[torch.Tensor]=None, V:Optional[torch.Tensor]=None, prev:Optional[torch.Tensor]=None,
key_padding_mask:Optional[torch.Tensor]=None, attn_mask:Optional[torch.Tensor]=None):
bs = Q.size(0)
if K is None: K = Q
if V is None: V = Q
# 线性(多头部拆分)
q_s = self.W_Q(Q).view(bs, -1, self.n_heads, self.d_k).transpose(1,2) # q_s : [批量大小 x 注意力头数 x 最大查询长度 x 键维度]
k_s = self.W_K(K).view(bs, -1, self.n_heads, self.d_k).permute(0,2,3,1) # k_s : [bs x n_heads x d_k x q_len] - 转置(1,2) + 转置(2,3)
v_s = self.W_V(V).view(bs, -1, self.n_heads, self.d_v).transpose(1,2) # v_s : [批量大小 x 注意力头数 x 查询长度 x 值维度]
# 应用缩放点积注意力(多头)
if self.res_attention:
output, attn_weights, attn_scores = self.sdp_attn(q_s, k_s, v_s,
prev=prev, key_padding_mask=key_padding_mask, attn_mask=attn_mask)
else:
output, attn_weights = self.sdp_attn(q_s, k_s, v_s, key_padding_mask=key_padding_mask, attn_mask=attn_mask)
# 输出:[批量大小 x 注意力头数 x 查询长度 x 值维度],注意力权重:[批量大小 x 注意力头数 x 查询长度 x 查询长度],得分:[批量大小 x 注意力头数 x 最大查询长度 x 查询长度]
# 回到原始输入维度
output = output.transpose(1, 2).contiguous().view(bs, -1, self.n_heads * self.d_v) # 输出:[批次大小 x 查询长度 x 注意力头数 * 值维度]
output = self.to_out(output)
if self.res_attention: return output, attn_weights, attn_scores
else: return output, attn_weights
class _ScaledDotProductAttention(nn.Module):
"""
Scaled Dot-Product Attention module (Attention is all you need by Vaswani et al., 2017) with optional residual attention from previous layer
(Realformer: Transformer likes residual attention by He et al, 2020) and locality self sttention (Vision Transformer for Small-Size Datasets
by Lee et al, 2021)
"""
def __init__(self, hidden_size, n_heads, attn_dropout=0., res_attention=False, lsa=False):
super().__init__()
self.attn_dropout = nn.Dropout(attn_dropout)
self.res_attention = res_attention
head_dim = hidden_size // n_heads
self.scale = nn.Parameter(torch.tensor(head_dim ** -0.5), requires_grad=lsa)
self.lsa = lsa
def forward(self, q:torch.Tensor, k:torch.Tensor, v:torch.Tensor,
prev:Optional[torch.Tensor]=None, key_padding_mask:Optional[torch.Tensor]=None,
attn_mask:Optional[torch.Tensor]=None):
'''
Input shape:
q : [bs x n_heads x max_q_len x d_k]
k : [bs x n_heads x d_k x seq_len]
v : [bs x n_heads x seq_len x d_v]
prev : [bs x n_heads x q_len x seq_len]
key_padding_mask: [bs x seq_len]
attn_mask : [1 x seq_len x seq_len]
Output shape:
output: [bs x n_heads x q_len x d_v]
attn : [bs x n_heads x q_len x seq_len]
scores : [bs x n_heads x q_len x seq_len]
'''
# 缩放矩阵乘法(q, k) - 输入序列中所有位置对的相似度得分
attn_scores = torch.matmul(q, k) * self.scale # attn_scores : [批量大小 x 注意力头数 x 最大查询长度 x 查询长度]
# 添加前一层的预softmax注意力分数(可选)
if prev is not None: attn_scores = attn_scores + prev
# 注意力掩码(可选)
if attn_mask is not None: # attn_mask,形状为 [q_len x seq_len] - 仅在 q_len 等于 seq_len 时使用
if attn_mask.dtype == torch.bool:
attn_scores.masked_fill_(attn_mask, -np.inf)
else:
attn_scores += attn_mask
# 关键填充掩码(可选)
if key_padding_mask is not None: # 形状为 [bs x q_len] 的掩码(仅在 max_w_len 等于 q_len 时)
attn_scores.masked_fill_(key_padding_mask.unsqueeze(1).unsqueeze(2), -np.inf)
# 规范alize the attention weights
attn_weights = F.softmax(attn_scores, dim=-1) # attn_weights:[批量大小 x 注意力头数 x 最大查询长度 x 查询长度]
attn_weights = self.attn_dropout(attn_weights)
# 根据注意力权重计算新值
output = torch.matmul(attn_weights, v) # 输出:[批大小 x 注意力头数 x 最大查询长度 x 值维度]
if self.res_attention: return output, attn_weights, attn_scores
else: return output, attn_weights2. 模型
class PatchTST(BaseWindows):
""" PatchTST
The PatchTST model is an efficient Transformer-based model for multivariate time series forecasting.
It is based on two key components:
- segmentation of time series into windows (patches) which are served as input tokens to Transformer
- channel-independence, where each channel contains a single univariate time series.
**Parameters:**<br>
`h`: int, Forecast horizon. <br>
`input_size`: int, autorregresive inputs size, y=[1,2,3,4] input_size=2 -> y_[t-2:t]=[1,2].<br>
`stat_exog_list`: str list, static exogenous columns.<br>
`hist_exog_list`: str list, historic exogenous columns.<br>
`futr_exog_list`: str list, future exogenous columns.<br>
`exclude_insample_y`: bool=False, the model skips the autoregressive features y[t-input_size:t] if True.<br>
`encoder_layers`: int, number of layers for encoder.<br>
`n_heads`: int=16, number of multi-head's attention.<br>
`hidden_size`: int=128, units of embeddings and encoders.<br>
`linear_hidden_size`: int=256, units of linear layer.<br>
`dropout`: float=0.1, dropout rate for residual connection.<br>
`fc_dropout`: float=0.1, dropout rate for linear layer.<br>
`head_dropout`: float=0.1, dropout rate for Flatten head layer.<br>
`attn_dropout`: float=0.1, dropout rate for attention layer.<br>
`patch_len`: int=32, length of patch. Note: patch_len = min(patch_len, input_size + stride).<br>
`stride`: int=16, stride of patch.<br>
`revin`: bool=True, bool to use RevIn.<br>
`revin_affine`: bool=False, bool to use affine in RevIn.<br>
`revin_substract_last`: bool=False, bool to use substract last in RevIn.<br>
`activation`: str='ReLU', activation from ['gelu','relu'].<br>
`res_attention`: bool=False, bool to use residual attention.<br>
`batch_normalization`: bool=False, bool to use batch normalization.<br>
`learn_pos_embedding`: bool=True, bool to learn positional embedding.<br>
`loss`: PyTorch module, instantiated train loss class from [losses collection](https://nixtla.github.io/neuralforecast/losses.pytorch.html).<br>
`valid_loss`: PyTorch module=`loss`, instantiated valid loss class from [losses collection](https://nixtla.github.io/neuralforecast/losses.pytorch.html).<br>
`max_steps`: int=1000, maximum number of training steps.<br>
`learning_rate`: float=1e-3, Learning rate between (0, 1).<br>
`num_lr_decays`: int=-1, Number of learning rate decays, evenly distributed across max_steps.<br>
`early_stop_patience_steps`: int=-1, Number of validation iterations before early stopping.<br>
`val_check_steps`: int=100, Number of training steps between every validation loss check.<br>
`batch_size`: int=32, number of different series in each batch.<br>
`valid_batch_size`: int=None, number of different series in each validation and test batch, if None uses batch_size.<br>
`windows_batch_size`: int=1024, number of windows to sample in each training batch, default uses all.<br>
`inference_windows_batch_size`: int=1024, number of windows to sample in each inference batch.<br>
`start_padding_enabled`: bool=False, if True, the model will pad the time series with zeros at the beginning, by input size.<br>
`step_size`: int=1, step size between each window of temporal data.<br>
`scaler_type`: str='identity', type of scaler for temporal inputs normalization see [temporal scalers](https://nixtla.github.io/neuralforecast/common.scalers.html).<br>
`random_seed`: int, random_seed for pytorch initializer and numpy generators.<br>
`num_workers_loader`: int=os.cpu_count(), workers to be used by `TimeSeriesDataLoader`.<br>
`drop_last_loader`: bool=False, if True `TimeSeriesDataLoader` drops last non-full batch.<br>
`alias`: str, optional, Custom name of the model.<br>
`optimizer`: Subclass of 'torch.optim.Optimizer', optional, user specified optimizer instead of the default choice (Adam).<br>
`optimizer_kwargs`: dict, optional, list of parameters used by the user specified `optimizer`.<br>
`lr_scheduler`: Subclass of 'torch.optim.lr_scheduler.LRScheduler', optional, user specified lr_scheduler instead of the default choice (StepLR).<br>
`lr_scheduler_kwargs`: dict, optional, list of parameters used by the user specified `lr_scheduler`.<br>
`**trainer_kwargs`: int, keyword trainer arguments inherited from [PyTorch Lighning's trainer](https://pytorch-lightning.readthedocs.io/en/stable/api/pytorch_lightning.trainer.trainer.Trainer.html?highlight=trainer).<br>
**References:**<br>
-[Nie, Y., Nguyen, N. H., Sinthong, P., & Kalagnanam, J. (2022). "A Time Series is Worth 64 Words: Long-term Forecasting with Transformers"](https://arxiv.org/pdf/2211.14730.pdf)
"""
# 类属性
SAMPLING_TYPE = 'windows'
EXOGENOUS_FUTR = False
EXOGENOUS_HIST = False
EXOGENOUS_STAT = False
def __init__(self,
h,
input_size,
stat_exog_list = None,
hist_exog_list = None,
futr_exog_list = None,
exclude_insample_y = False,
encoder_layers: int = 3,
n_heads: int = 16,
hidden_size: int = 128,
linear_hidden_size: int = 256,
dropout: float = 0.2,
fc_dropout: float = 0.2,
head_dropout: float = 0.0,
attn_dropout: float = 0.,
patch_len: int = 16,
stride: int = 8,
revin: bool = True,
revin_affine: bool = False,
revin_subtract_last: bool = True,
activation: str = "gelu",
res_attention: bool = True,
batch_normalization: bool = False,
learn_pos_embed: bool = True,
loss = MAE(),
valid_loss = None,
max_steps: int = 5000,
learning_rate: float = 1e-4,
num_lr_decays: int = -1,
early_stop_patience_steps: int =-1,
val_check_steps: int = 100,
batch_size: int = 32,
valid_batch_size: Optional[int] = None,
windows_batch_size = 1024,
inference_windows_batch_size: int = 1024,
start_padding_enabled = False,
step_size: int = 1,
scaler_type: str = 'identity',
random_seed: int = 1,
num_workers_loader: int = 0,
drop_last_loader: bool = False,
optimizer = None,
optimizer_kwargs = None,
lr_scheduler = None,
lr_scheduler_kwargs = None,
**trainer_kwargs):
super(PatchTST, self).__init__(h=h,
input_size=input_size,
hist_exog_list=hist_exog_list,
stat_exog_list=stat_exog_list,
futr_exog_list = futr_exog_list,
exclude_insample_y = exclude_insample_y,
loss=loss,
valid_loss=valid_loss,
max_steps=max_steps,
learning_rate=learning_rate,
num_lr_decays=num_lr_decays,
early_stop_patience_steps=early_stop_patience_steps,
val_check_steps=val_check_steps,
batch_size=batch_size,
valid_batch_size=valid_batch_size,
windows_batch_size=windows_batch_size,
inference_windows_batch_size=inference_windows_batch_size,
start_padding_enabled=start_padding_enabled,
step_size=step_size,
scaler_type=scaler_type,
num_workers_loader=num_workers_loader,
drop_last_loader=drop_last_loader,
random_seed=random_seed,
optimizer=optimizer,
optimizer_kwargs=optimizer_kwargs,
lr_scheduler=lr_scheduler,
lr_scheduler_kwargs=lr_scheduler_kwargs,
**trainer_kwargs)
# 无论用户输入如何,强制执行正确的patch_len。
patch_len = min(input_size + stride, patch_len)
c_out = self.loss.outputsize_multiplier
# 固定的超参数
c_in = 1 # 始终单变量
padding_patch='end' # 结尾处的填充
pretrain_head = False # 无预训练头部
norm = 'BatchNorm' # 使用批量归一化(如果 batch_normalization 为 True)
pe = 'zeros' # 位置编码的初始零值
d_k = None # 关键维度
d_v = None # 价值维度
store_attn = False # 存储注意力权重
head_type = 'flatten' # 头型
individual = False # 每个时间序列的独立头
max_seq_len = 1024 # 未使用
key_padding_mask = 'auto' # 未使用
padding_var = None # 未使用
attn_mask = None # 未使用
self.model = PatchTST_backbone(c_in=c_in, c_out=c_out, input_size=input_size, h=h, patch_len=patch_len, stride=stride,
max_seq_len=max_seq_len, n_layers=encoder_layers, hidden_size=hidden_size,
n_heads=n_heads, d_k=d_k, d_v=d_v, linear_hidden_size=linear_hidden_size, norm=norm, attn_dropout=attn_dropout,
dropout=dropout, act=activation, key_padding_mask=key_padding_mask, padding_var=padding_var,
attn_mask=attn_mask, res_attention=res_attention, pre_norm=batch_normalization, store_attn=store_attn,
pe=pe, learn_pe=learn_pos_embed, fc_dropout=fc_dropout, head_dropout=head_dropout, padding_patch = padding_patch,
pretrain_head=pretrain_head, head_type=head_type, individual=individual, revin=revin, affine=revin_affine,
subtract_last=revin_subtract_last)
def forward(self, windows_batch): # x: [批次, 输入大小]
# 解析Windows批处理文件
insample_y = windows_batch['insample_y']
#insample_mask = windows_batch['insample_mask']
#hist_exog = windows_batch['hist_exog']
#stat_exog = windows_batch['stat_exog']
#futr_exog = windows_batch['futr_exog']
# 为通道添加维度
x = insample_y.unsqueeze(-1) # [Ws,L,1]
x = x.permute(0,2,1) # x: [批次, 1, 输入尺寸]
x = self.model(x)
x = x.reshape(x.shape[0], self.h, -1) # x: [批次, 高度, 输出通道数]
# 域图
forecast = self.loss.domain_map(x)
return forecastshow_doc(PatchTST)show_doc(PatchTST.fit, name='PatchTST.fit')show_doc(PatchTST.predict, name='PatchTST.predict')使用示例
import pandas as pd
import matplotlib.pyplot as plt
from neuralforecast import NeuralForecast
from neuralforecast.models import PatchTST
from neuralforecast.losses.pytorch import DistributionLoss
from neuralforecast.utils import AirPassengersPanel, AirPassengersStatic, augment_calendar_df
AirPassengersPanel, calendar_cols = augment_calendar_df(df=AirPassengersPanel, freq='M')
Y_train_df = AirPassengersPanel[AirPassengersPanel.ds<AirPassengersPanel['ds'].values[-12]] # 132次列车
Y_test_df = AirPassengersPanel[AirPassengersPanel.ds>=AirPassengersPanel['ds'].values[-12]].reset_index(drop=True) # 12项测试
model = PatchTST(h=12,
input_size=104,
patch_len=24,
stride=24,
revin=False,
hidden_size=16,
n_heads=4,
scaler_type='robust',
loss=DistributionLoss(distribution='StudentT', level=[80, 90]),
#损失=MAE()
learning_rate=1e-3,
max_steps=500,
val_check_steps=50,
early_stop_patience_steps=2)
nf = NeuralForecast(
models=[model],
freq='M'
)
nf.fit(df=Y_train_df, static_df=AirPassengersStatic, val_size=12)
forecasts = nf.predict(futr_df=Y_test_df)
Y_hat_df = forecasts.reset_index(drop=False).drop(columns=['unique_id','ds'])
plot_df = pd.concat([Y_test_df, Y_hat_df], axis=1)
plot_df = pd.concat([Y_train_df, plot_df])
if model.loss.is_distribution_output:
plot_df = plot_df[plot_df.unique_id=='Airline1'].drop('unique_id', axis=1)
plt.plot(plot_df['ds'], plot_df['y'], c='black', label='True')
plt.plot(plot_df['ds'], plot_df['PatchTST-median'], c='blue', label='median')
plt.fill_between(x=plot_df['ds'][-12:],
y1=plot_df['PatchTST-lo-90'][-12:].values,
y2=plot_df['PatchTST-hi-90'][-12:].values,
alpha=0.4, label='level 90')
plt.grid()
plt.legend()
plt.plot()
else:
plot_df = plot_df[plot_df.unique_id=='Airline1'].drop('unique_id', axis=1)
plt.plot(plot_df['ds'], plot_df['y'], c='black', label='True')
plt.plot(plot_df['ds'], plot_df['PatchTST'], c='blue', label='Forecast')
plt.legend()
plt.grid()Give us a ⭐ on Github