mars.dataframe.DataFrame.plot.kde#
- DataFrame.plot.kde(*args, **kwargs)#
使用高斯核生成核密度估计图。
在统计学中,核密度估计 (KDE) 是一种非参数方法,用于估计随机变量的概率密度函数 (PDF)。该函数使用高斯核,并包括自动带宽确定。
- Parameters
bw_method (str, scalar 或 callable, 可选) – 用于计算估计器带宽的方法。可以是 ‘scott’,‘silverman’,一个标量常量或一个可调用对象。 如果为None(默认),则使用‘scott’。 有关更多信息,请参见
scipy.stats.gaussian_kde。ind (NumPy 数组 或 int, 可选) – 用于估计 PDF 的评估点。如果为 None(默认),将使用 1000 个均匀间隔的点。如果ind是 NumPy 数组,KDE 在传递的点上进行评估。如果ind是一个整数,则使用ind个均匀间隔的点。
**kwargs – 额外的关键字参数已在
pandas.%(this-datatype)s.plot()中记录。
- Return type
另请参阅
scipy.stats.gaussian_kde使用高斯核的核密度估计的表示。这是内部用来估计概率密度函数的函数。
示例
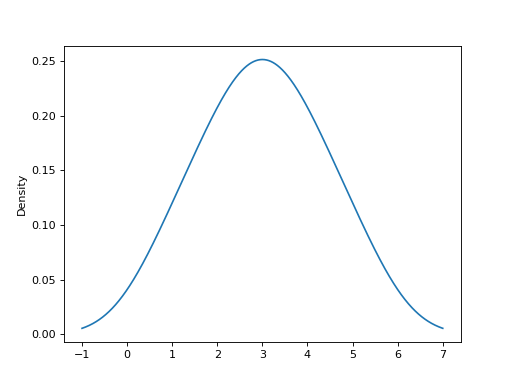
给定一系列从未知分布中随机采样的点,使用KDE自动带宽确定估计其概率密度函数(PDF)并绘制结果,在1000个等间距的点(默认)评估它们:
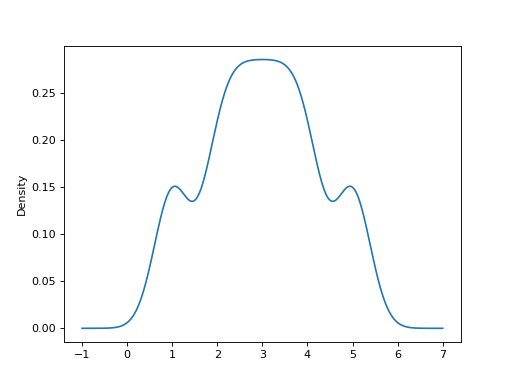
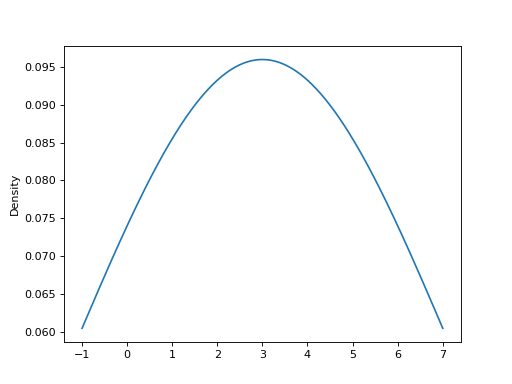
可以指定一个标量带宽。使用较小的带宽值可能导致过拟合,而使用较大的带宽值可能会导致欠拟合:
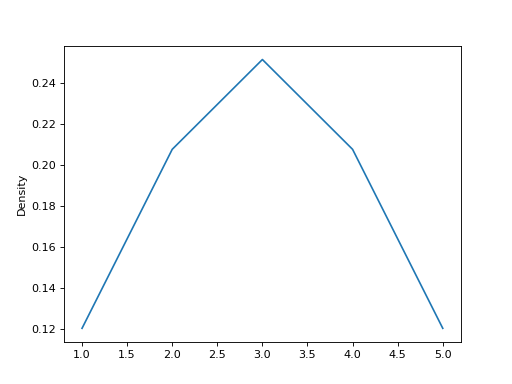
最后,ind 参数决定了估计概率密度函数的绘图评估点:
对于 DataFrame,它的工作方式相同:
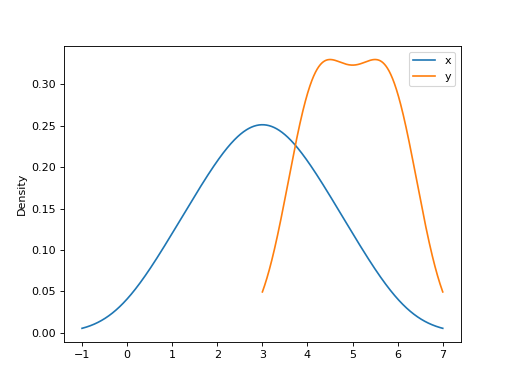
可以指定一个标量带宽。使用较小的带宽值可能导致过拟合,而使用较大的带宽值可能会导致欠拟合:
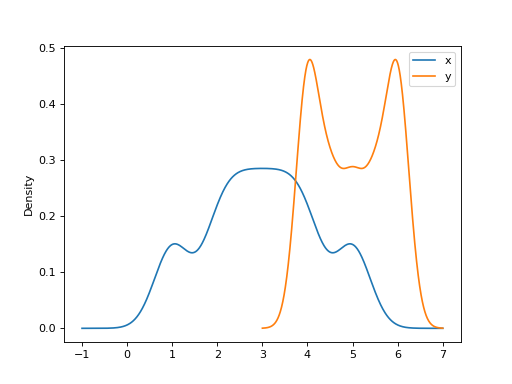

最后,ind 参数决定了估计概率密度函数的绘图评估点:
